Do We Always Need Query-Level Workflows? Rethinking Agentic Workflow Generation for Multi-Agent Systems
作者: Zixu Wang, Bingbing Xu, Yige Yuan, Huawei Shen, Xueqi Cheng
分类: cs.AI
发布日期: 2026-01-16
备注: 17 pages, 4 figures, 3 tables
💡 一句话要点
提出SCALE框架以优化多智能体系统的工作流生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 工作流生成 任务级评估 自我预测 生成奖励建模 低成本优化 效率提升
📋 核心要点
- 现有的工作流生成方法在任务级和查询级之间的选择存在不明确的成本和收益,导致效率低下。
- 论文提出的SCALE框架通过自我预测和少量样本校准,优化了任务级工作流生成,降低了执行成本。
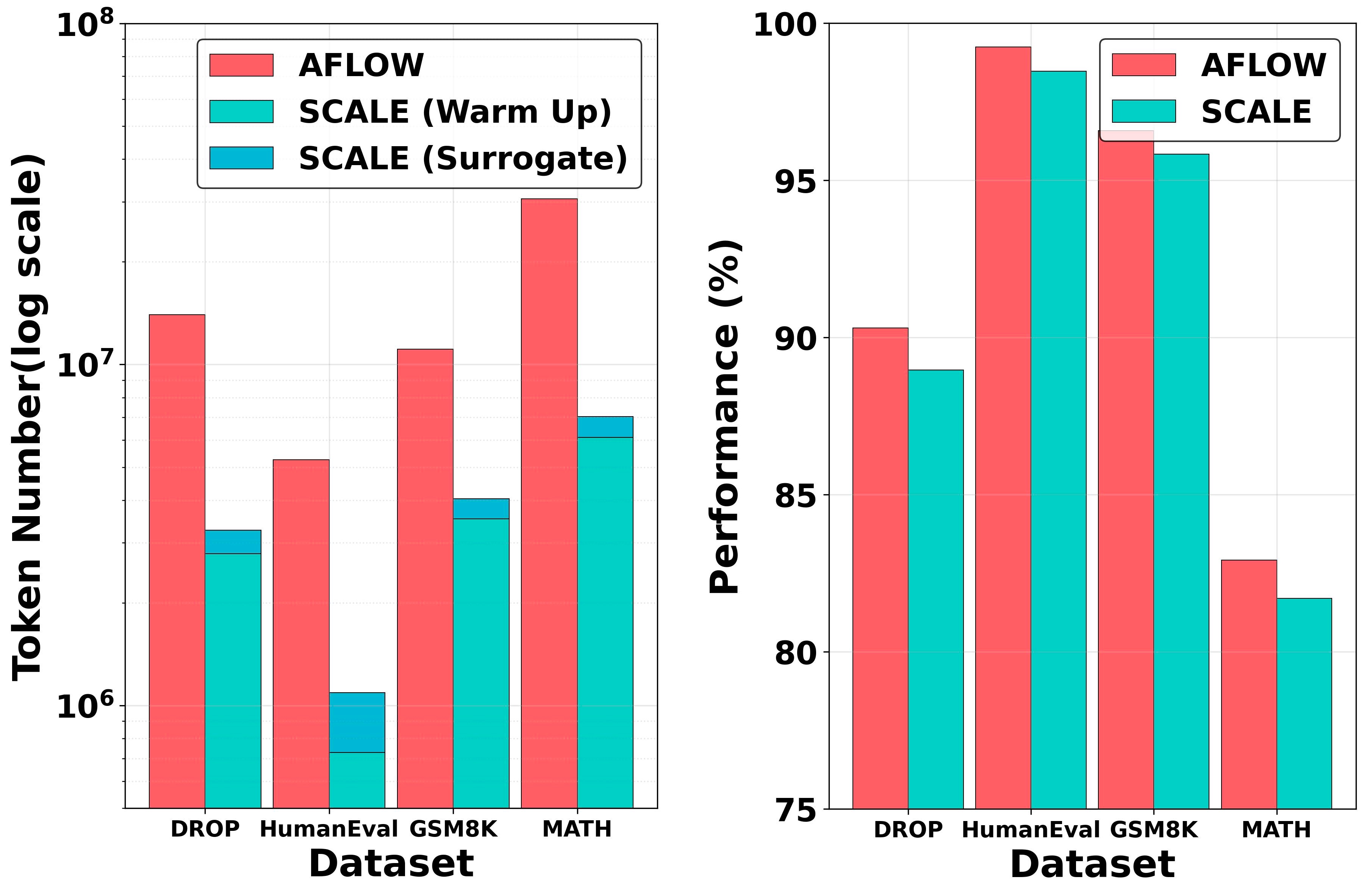
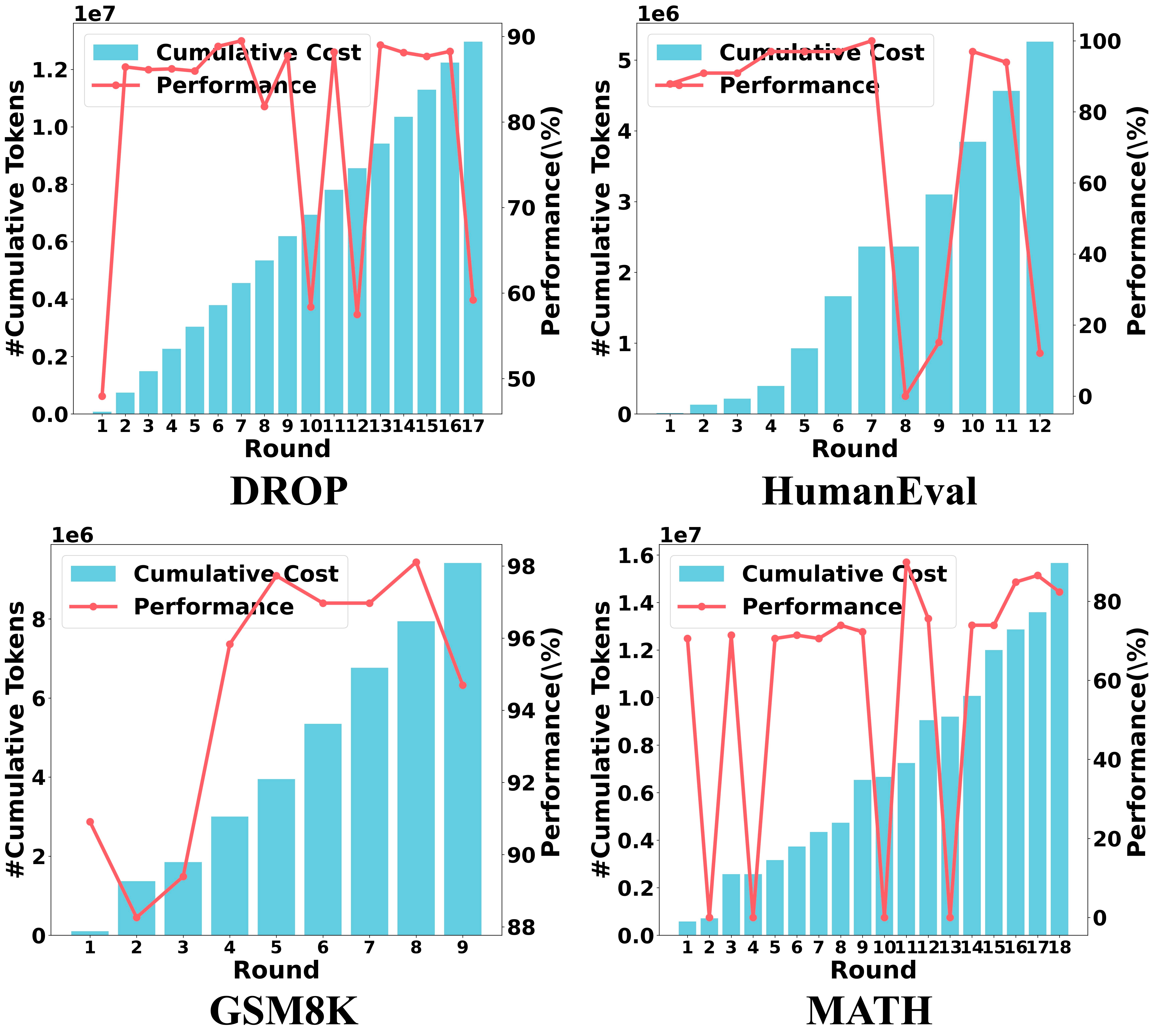
- 实验结果显示,SCALE在多个数据集上性能仅下降0.61%,同时令牌使用量减少了83%,展现出显著的效率提升。
📝 摘要(中文)
基于大型语言模型的多智能体系统(MAS)通常通过工作流协调多个智能体以解决复杂任务。现有方法在任务级或查询级生成工作流,但其相对成本和收益尚不明确。经过重新思考和实证分析,我们发现查询级工作流生成并非总是必要,因为少量最佳任务级工作流已能覆盖等效或更多查询。此外,基于执行的任务级评估既昂贵又不可靠。受自我演化和生成奖励建模的启发,我们提出了一种低成本的任务级生成框架SCALE,旨在通过少量样本校准优化器的自我预测来替代全面验证执行。大量实验表明,SCALE在多个数据集上保持竞争力,平均性能下降仅为0.61%,同时整体令牌使用量减少高达83%。
🔬 方法详解
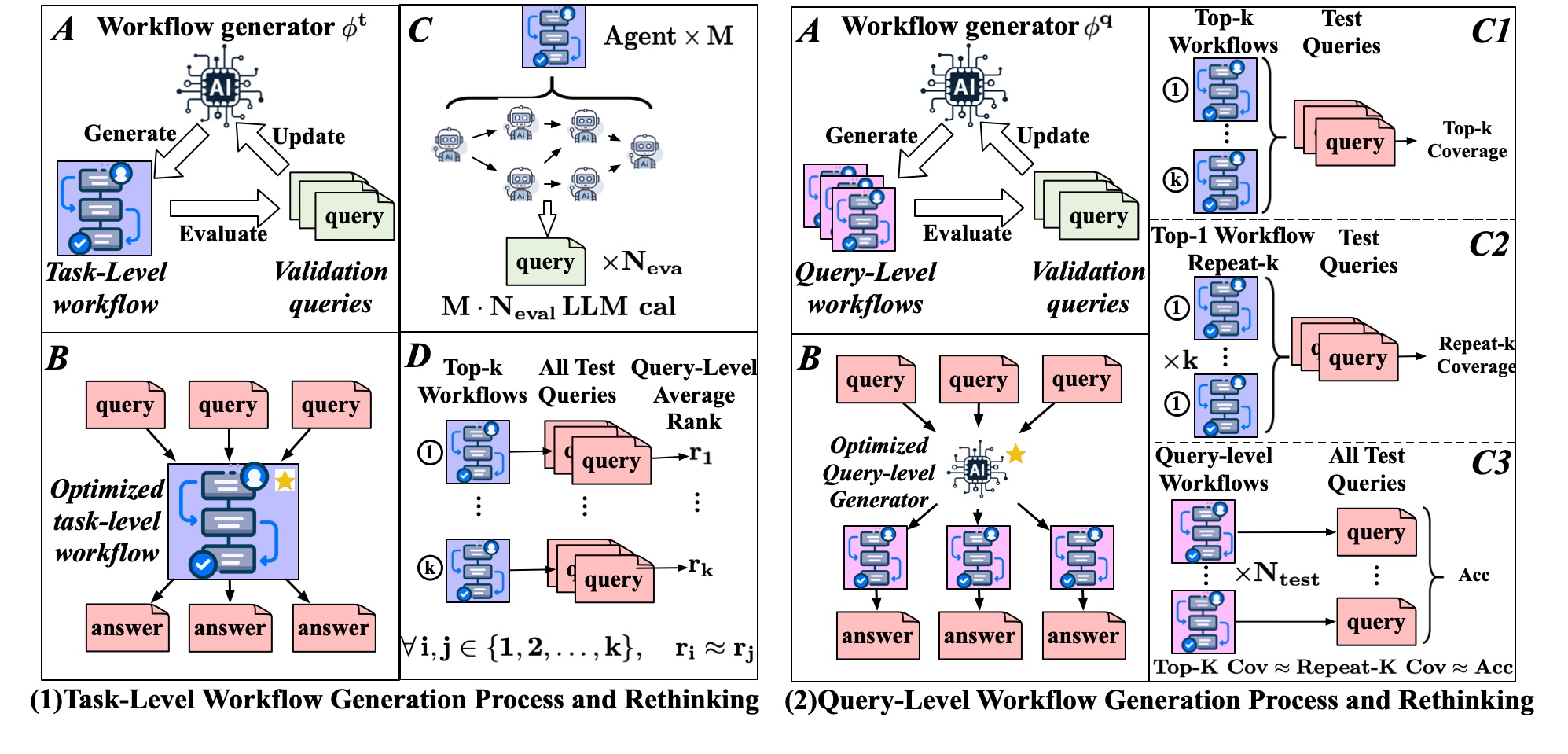
问题定义:现有的多智能体系统工作流生成方法在任务级和查询级之间的选择存在不明确的成本和收益,导致生成效率低下,尤其是在执行成本和可靠性方面存在挑战。
核心思路:论文提出的SCALE框架通过自我预测和少量样本校准,旨在优化任务级工作流生成,避免全面验证执行的高成本和不可靠性。
技术框架:SCALE框架主要包括自我预测模块、少量样本校准模块和评估模块。自我预测模块负责生成任务级工作流,校准模块通过少量样本进行优化,而评估模块则用于验证生成的工作流的有效性。
关键创新:SCALE的核心创新在于通过自我演化和生成奖励建模,替代了传统的全面验证执行方法,从而显著降低了令牌使用量和执行成本。
关键设计:在SCALE中,关键参数设置包括自我预测的样本数量和校准的策略,同时损失函数设计上强调生成质量与执行效率的平衡。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SCALE在多个数据集上与现有方法相比,性能仅下降0.61%,而整体令牌使用量减少高达83%。这一显著的性能提升和资源节约,展示了SCALE框架在多智能体系统中的有效性和优势。
🎯 应用场景
该研究的SCALE框架具有广泛的应用潜力,特别是在需要高效协调多个智能体的复杂任务场景中,如智能交通系统、机器人协作和自动化生产线等。其低成本的工作流生成方法能够提高系统的整体效率,降低资源消耗,具有重要的实际价值和未来影响。
📄 摘要(原文)
Multi-Agent Systems (MAS) built on large language models typically solve complex tasks by coordinating multiple agents through workflows. Existing approaches generates workflows either at task level or query level, but their relative costs and benefits remain unclear. After rethinking and empirical analyses, we show that query-level workflow generation is not always necessary, since a small set of top-K best task-level workflows together already covers equivalent or even more queries. We further find that exhaustive execution-based task-level evaluation is both extremely token-costly and frequently unreliable. Inspired by the idea of self-evolution and generative reward modeling, we propose a low-cost task-level generation framework \textbf{SCALE}, which means \underline{\textbf{S}}elf prediction of the optimizer with few shot \underline{\textbf{CAL}}ibration for \underline{\textbf{E}}valuation instead of full validation execution. Extensive experiments demonstrate that \textbf{SCALE} maintains competitive performance, with an average degradation of just 0.61\% compared to existing approach across multiple datasets, while cutting overall token usage by up to 83\%.