Learn Before Represent: Bridging Generative and Contrastive Learning for Domain-Specific LLM Embeddings
作者: Xiaoyu Liang, Yuchen Peng, Jiale Luo, Wenhao Wang, Haoji Hu, Xincheng Zhou
分类: cs.IR, cs.AI
发布日期: 2026-01-16
备注: 10 pages, 3 figures
💡 一句话要点
LBR:桥接生成式与对比学习,提升领域特定LLM嵌入表示能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 领域特定LLM 对比学习 生成式学习 信息瓶颈 表示学习
📋 核心要点
- 现有“LLM+CL”方法在垂直领域表现不佳,主要原因是缺乏领域知识,无法有效获取和利用专业术语。
- LBR框架首先通过生成式学习注入领域知识,利用信息瓶颈约束压缩语义,保留LLM的因果注意力。
- LBR在医学、化学和代码检索任务上显著优于现有基线,验证了其在垂直领域表示学习方面的有效性。
📝 摘要(中文)
大型语言模型(LLM)通过对比学习进行适配,在通用表示学习方面表现出色,但在化学和法律等垂直领域却表现不佳,这主要是由于缺乏领域特定知识。这项工作确定了一个核心瓶颈:流行的“LLM+CL”范式侧重于语义对齐,但无法执行知识获取,导致在专业术语上失败。为了弥合这一差距,我们提出了一种新颖的两阶段框架——Learn Before Represent (LBR)。LBR首先通过信息瓶颈约束的生成学习阶段注入领域知识,保留LLM的因果注意力以最大化知识获取,同时压缩语义。然后,它对压缩表示执行生成式精炼的对比学习以进行对齐。这种方法保持了架构一致性,并解决了生成式学习和对比学习之间的目标冲突。在医学、化学和代码检索任务上的大量实验表明,LBR显著优于强大的基线。我们的工作为构建垂直领域中准确而鲁棒的表示建立了一个新的范例。
🔬 方法详解
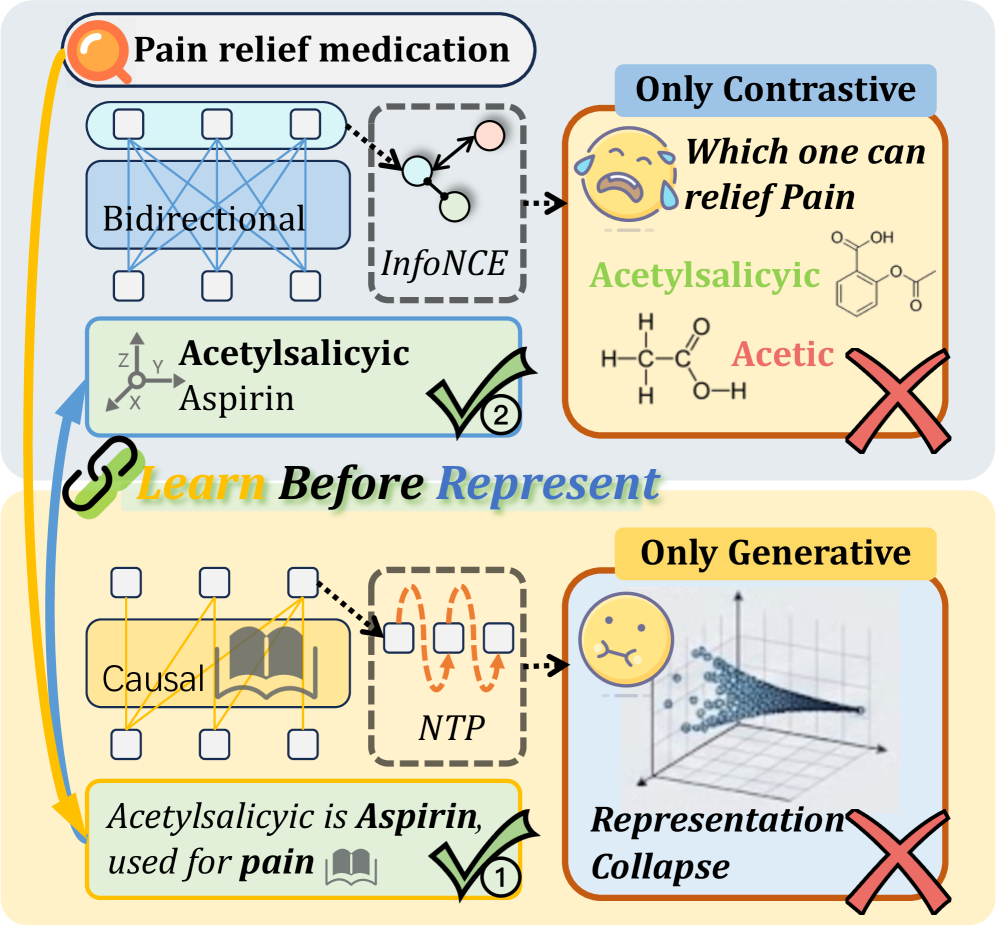
问题定义:现有方法,特别是直接将对比学习应用于LLM的方法,在垂直领域表现不佳。这是因为对比学习主要关注语义对齐,而忽略了领域知识的获取。因此,LLM无法理解和处理特定领域的专业术语,导致表示质量下降。
核心思路:LBR的核心思路是在表示学习之前先进行知识学习。通过生成式学习,让LLM主动学习并吸收领域知识,然后再利用对比学习进行语义对齐。这种“先学习,后表示”的策略能够有效解决现有方法的瓶颈。
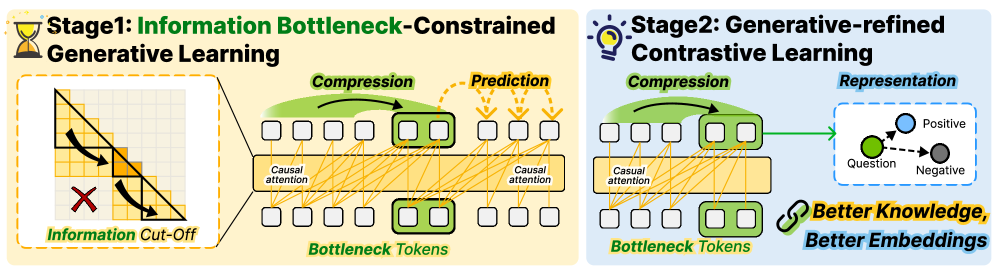
技术框架:LBR框架包含两个主要阶段:1) 信息瓶颈约束的生成学习阶段:利用生成模型,例如Transformer,对领域数据进行训练,并引入信息瓶颈约束,迫使模型学习到更紧凑、更具信息量的表示。2) 生成式精炼的对比学习阶段:利用第一阶段学习到的表示,通过对比学习进一步优化LLM的嵌入,使其更好地适应特定领域。
关键创新:LBR的关键创新在于将生成式学习和对比学习有机结合,并提出了“先学习,后表示”的新范式。与直接应用对比学习的方法相比,LBR能够有效提升LLM在垂直领域的知识获取能力,从而提高表示质量。
关键设计:在生成学习阶段,使用了信息瓶颈约束,具体实现方式未知,可能是通过添加正则化项或者使用特定的网络结构来实现。在对比学习阶段,使用了生成式精炼,具体如何利用生成模型的信息来指导对比学习也未知。损失函数的设计也未知。
🖼️ 关键图片
📊 实验亮点
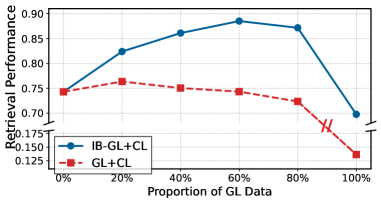
LBR在医学、化学和代码检索任务上取得了显著的性能提升。具体提升幅度未知,但论文强调LBR显著优于强大的基线模型,表明其在垂直领域表示学习方面的有效性。这些实验结果验证了LBR框架的优越性和实用性。
🎯 应用场景
LBR框架可广泛应用于各种垂直领域的LLM嵌入表示学习,例如医学、法律、金融、化学、代码等。通过提升LLM在这些领域的知识理解和表示能力,可以有效改善信息检索、文本分类、问答系统等下游任务的性能,具有重要的实际应用价值和广阔的发展前景。
📄 摘要(原文)
Large Language Models (LLMs) adapted via contrastive learning excel in general representation learning but struggle in vertical domains like chemistry and law, primarily due to a lack of domain-specific knowledge. This work identifies a core bottleneck: the prevailing ``LLM+CL'' paradigm focuses on semantic alignment but cannot perform knowledge acquisition, leading to failures on specialized terminology. To bridge this gap, we propose Learn Before Represent (LBR), a novel two-stage framework. LBR first injects domain knowledge via an Information Bottleneck-Constrained Generative Learning stage, preserving the LLM's causal attention to maximize knowledge acquisition while compressing semantics. It then performs Generative-Refined Contrastive Learning on the compressed representations for alignment. This approach maintains architectural consistency and resolves the objective conflict between generative and contrastive learning. Extensive experiments on medical, chemistry, and code retrieval tasks show that LBR significantly outperforms strong baselines. Our work establishes a new paradigm for building accurate and robust representations in vertical domains.