Predicting Biased Human Decision-Making with Large Language Models in Conversational Settings
作者: Stephen Pilli, Vivek Nallur
分类: cs.HC, cs.AI
发布日期: 2026-01-16
备注: Accepted at ACM IUI 2026
💡 一句话要点
利用大型语言模型预测会话场景中人类决策偏差
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 决策偏差 认知负荷 会话代理 框架效应
📋 核心要点
- 现有方法难以准确预测会话场景中人类决策偏差,尤其是在认知负荷变化的情况下。
- 利用大型语言模型,结合人口统计信息和对话上下文,预测个体决策,并捕捉认知偏差和负荷效应。
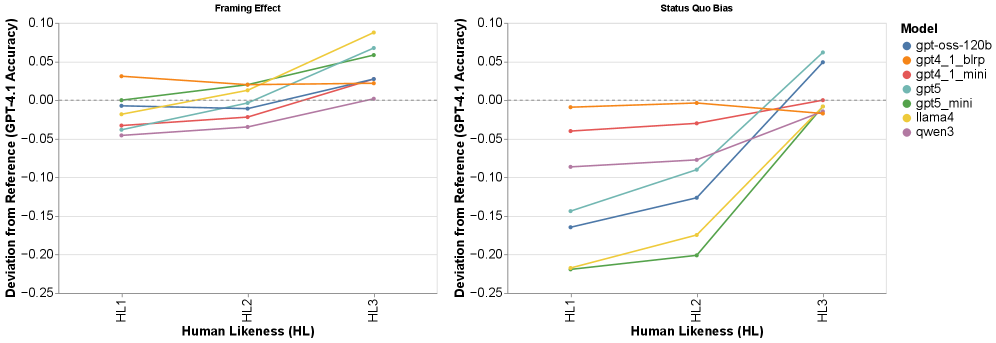
- 实验表明,GPT-4在预测人类决策偏差方面表现最佳,能够重现人类的偏差模式和负荷-偏差交互。
📝 摘要(中文)
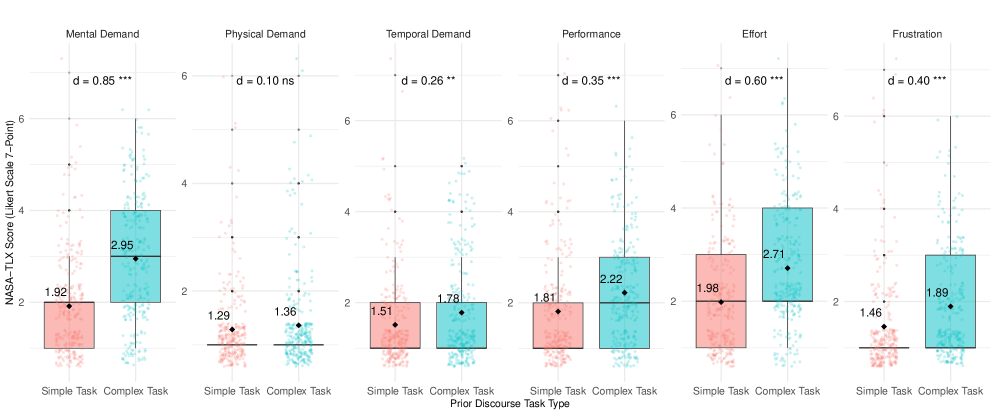
本文研究了大型语言模型(LLMs)是否能够预测会话场景中人类有偏差的决策,以及它们的预测是否不仅能捕捉到人类的认知偏差,还能捕捉到这些偏差效应如何在认知负荷下发生变化。在一项预注册研究(N = 1,648)中,参与者通过聊天机器人完成了六项经典的决策任务,对话的复杂程度各不相同。参与者表现出两种有据可查的认知偏差:框架效应和现状偏差。对话复杂性的增加导致参与者报告更高的心理需求。这种认知负荷的增加选择性地但显著地增加了偏差的影响,证明了负荷-偏差的相互作用。然后,我们评估了LLMs(GPT-4、GPT-5和开源模型)是否能够在给定人口统计信息和先前对话的情况下预测个人决策。虽然结果在不同的选择问题中好坏参半,但在几个关键场景中,包含对话上下文的LLM预测明显更准确。重要的是,它们的预测重现了人类观察到的相同偏差模式和负荷-偏差的相互作用。在所有测试模型中,GPT-4系列始终与人类行为保持一致,在预测准确性和对人类偏差模式的保真度方面均优于GPT-5和开源模型。这些发现加深了我们对LLMs作为模拟人类决策工具的理解,并为适应用户偏差的会话代理的设计提供了信息。
🔬 方法详解
问题定义:论文旨在解决在会话环境中,如何利用大型语言模型准确预测人类决策偏差的问题。现有方法难以捕捉认知负荷变化对决策偏差的影响,并且缺乏对个体决策差异的精细化建模。
核心思路:论文的核心思路是利用大型语言模型理解对话上下文,并结合个体的人口统计信息,来预测其在特定决策任务中的选择。通过模拟人类的认知过程,捕捉认知偏差(如框架效应和现状偏差)以及认知负荷对这些偏差的影响。
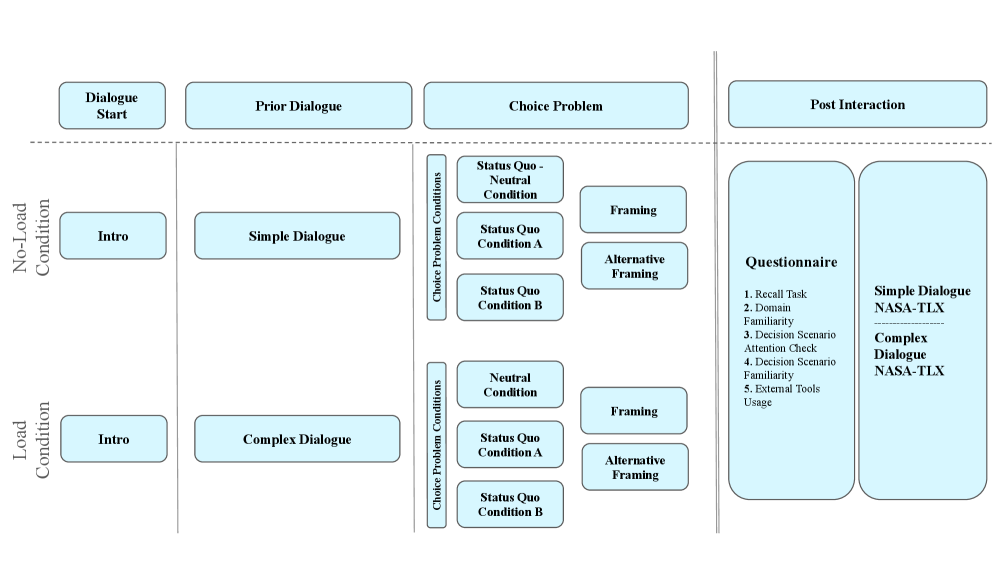
技术框架:整体框架包括以下几个阶段:1) 通过聊天机器人与参与者进行对话,完成决策任务;2) 收集参与者的人口统计信息和对话历史;3) 使用大型语言模型(GPT-4, GPT-5, 开源模型)进行预测,输入包括人口统计信息和对话上下文;4) 评估模型的预测准确性,并分析其是否能重现人类的偏差模式和负荷-偏差交互。
关键创新:最重要的创新点在于,论文验证了大型语言模型不仅可以预测人类的决策,还可以模拟人类的认知偏差,并捕捉认知负荷对这些偏差的影响。这为理解和模拟人类决策过程提供了一种新的工具。
关键设计:研究中使用了六个经典的决策任务,并通过改变对话的复杂程度来操纵认知负荷。模型的输入包括人口统计信息和对话上下文,输出是预测的决策选择。通过比较不同模型的预测准确性和与人类行为的相似度,评估模型的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GPT-4在预测人类决策偏差方面表现最佳,能够重现人类的偏差模式和负荷-偏差交互。在包含对话上下文的情况下,LLM的预测准确性显著提高。GPT-4在预测准确性和对人类偏差模式的保真度方面均优于GPT-5和开源模型。
🎯 应用场景
该研究成果可应用于开发更智能的会话代理,这些代理能够理解用户的认知偏差,并根据用户的具体情况调整对话策略,从而提高用户满意度和决策质量。此外,该研究还可以用于模拟人类行为,帮助研究人员更好地理解人类决策过程。
📄 摘要(原文)
We examine whether large language models (LLMs) can predict biased decision-making in conversational settings, and whether their predictions capture not only human cognitive biases but also how those effects change under cognitive load. In a pre-registered study (N = 1,648), participants completed six classic decision-making tasks via a chatbot with dialogues of varying complexity. Participants exhibited two well-documented cognitive biases: the Framing Effect and the Status Quo Bias. Increased dialogue complexity resulted in participants reporting higher mental demand. This increase in cognitive load selectively, but significantly, increased the effect of the biases, demonstrating the load-bias interaction. We then evaluated whether LLMs (GPT-4, GPT-5, and open-source models) could predict individual decisions given demographic information and prior dialogue. While results were mixed across choice problems, LLM predictions that incorporated dialogue context were significantly more accurate in several key scenarios. Importantly, their predictions reproduced the same bias patterns and load-bias interactions observed in humans. Across all models tested, the GPT-4 family consistently aligned with human behavior, outperforming GPT-5 and open-source models in both predictive accuracy and fidelity to human-like bias patterns. These findings advance our understanding of LLMs as tools for simulating human decision-making and inform the design of conversational agents that adapt to user biases.