A Safety Report on GPT-5.2, Gemini 3 Pro, Qwen3-VL, Doubao 1.8, Grok 4.1 Fast, Nano Banana Pro, and Seedream 4.5
作者: Xingjun Ma, Yixu Wang, Hengyuan Xu, Yutao Wu, Yifan Ding, Yunhan Zhao, Zilong Wang, Jiabin Hua, Ming Wen, Jianan Liu, Ranjie Duan, Yifeng Gao, Yingshui Tan, Yunhao Chen, Hui Xue, Xin Wang, Wei Cheng, Jingjing Chen, Zuxuan Wu, Bo Li, Yu-Gang Jiang
分类: cs.AI, cs.CL, cs.CV, cs.LG
发布日期: 2026-01-15
备注: 42 pages, 24 figures
💡 一句话要点
综合安全评估揭示前沿LLM/MLLM在多模态、多语言和对抗环境下的安全异构性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型安全 多模态学习 对抗攻击 多语言评估 合规性评估 安全基准 模型评估
📋 核心要点
- 现有LLM/MLLM安全评估缺乏统一标准,难以全面衡量模型在不同模态和威胁下的真实风险。
- 论文提出统一的评估协议,整合基准、对抗、多语言和合规性评估,全面评估7个前沿模型的安全性。
- 实验结果表明,模型安全性存在显著异构性,在对抗攻击下脆弱性明显,需标准化评估以指导模型开发。
📝 摘要(中文)
大型语言模型(LLM)和多模态大型语言模型(MLLM)的快速发展在语言和视觉的推理、感知和生成能力方面取得了显著进展。然而,这些进步是否带来了相应的安全改进尚不清楚,部分原因是评估实践分散,仅限于单一模态或威胁模型。本报告对7个前沿模型:GPT-5.2、Gemini 3 Pro、Qwen3-VL、Doubao 1.8、Grok 4.1 Fast、Nano Banana Pro和Seedream 4.5进行了综合安全评估。我们使用统一的协议,整合了基准评估、对抗评估、多语言评估和合规性评估,在语言、视觉-语言和图像生成设置中评估每个模型。将评估结果汇总到安全排行榜和跨多种评估模式的模型安全配置文件中,揭示了一个高度异构的安全格局。虽然GPT-5.2在各项评估中表现出始终如一的强大且均衡的安全性能,但其他模型在基准安全性、对抗对齐、多语言泛化和法规遵从性之间表现出明显的权衡。语言和视觉-语言模态在对抗评估下都显示出显著的脆弱性,尽管在标准基准测试中取得了优异的成绩,但所有模型的性能都大幅下降。文本到图像模型在受监管的视觉风险类别中实现了相对较强的对齐,但在对抗性或语义模糊的提示下仍然脆弱。总的来说,这些结果表明,前沿模型的安全性本质上是多维的——受模态、语言和评估方案的影响,强调需要标准化的安全评估来准确评估真实世界的风险,并指导负责任的模型开发和部署。
🔬 方法详解
问题定义:当前LLM和MLLM的安全评估体系存在碎片化问题,缺乏统一的标准和方法,难以全面评估模型在不同模态(语言、视觉-语言、图像生成)、不同语言和不同威胁模型下的安全性。现有方法往往只关注单一模态或特定类型的攻击,无法反映模型在真实世界复杂场景中的安全风险。
核心思路:论文的核心思路是构建一个统一的、多维度的安全评估框架,通过整合基准评估、对抗评估、多语言评估和合规性评估,全面评估LLM和MLLM的安全性。该框架旨在揭示模型在不同评估维度上的安全性能差异,并识别模型在对抗攻击、多语言环境和法规遵从方面的潜在脆弱性。
技术框架:该研究的技术框架包含以下几个主要模块:1) 模型选择:选择7个前沿LLM/MLLM进行评估,包括GPT-5.2、Gemini 3 Pro、Qwen3-VL等。2) 评估协议设计:设计统一的评估协议,涵盖语言、视觉-语言和图像生成三个模态,并整合基准评估、对抗评估、多语言评估和合规性评估四种评估方法。3) 评估实施:针对每个模型,在不同模态和评估方法下进行实验,收集评估数据。4) 结果分析:对评估数据进行分析,生成安全排行榜和模型安全配置文件,揭示模型在不同评估维度上的安全性能差异。
关键创新:该研究的关键创新在于提出了一个统一的、多维度的安全评估框架,能够全面评估LLM和MLLM的安全性。与现有方法相比,该框架不仅考虑了模型在标准基准测试上的性能,还关注了模型在对抗攻击、多语言环境和法规遵从方面的表现,从而更准确地评估模型在真实世界中的安全风险。
关键设计:在评估协议设计方面,论文考虑了以下关键设计:1) 对抗评估:采用多种对抗攻击方法,例如文本对抗攻击和图像对抗攻击,评估模型在面对恶意输入时的鲁棒性。2) 多语言评估:使用多种语言的数据集进行评估,评估模型在不同语言环境下的泛化能力。3) 合规性评估:评估模型是否符合相关的法律法规和伦理规范,例如是否生成有害内容或侵犯用户隐私。
🖼️ 关键图片
📊 实验亮点
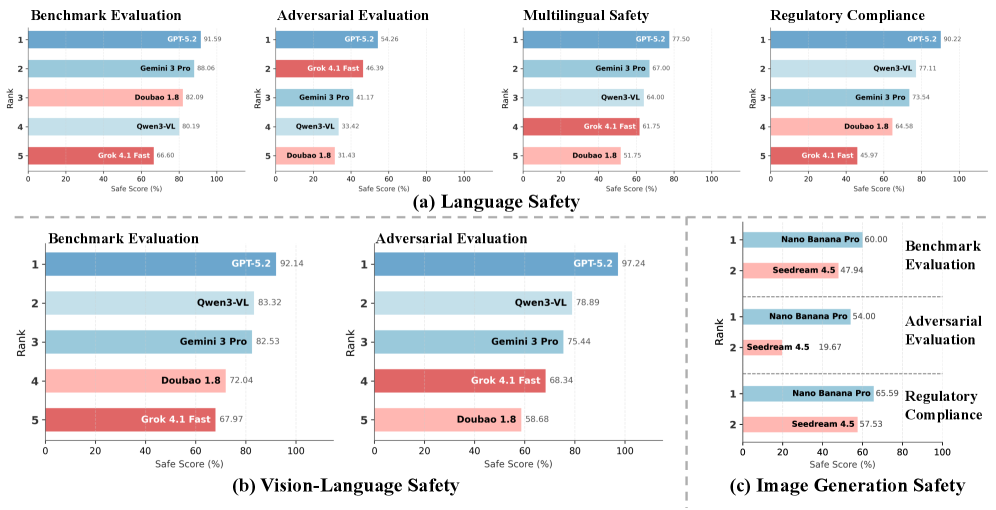
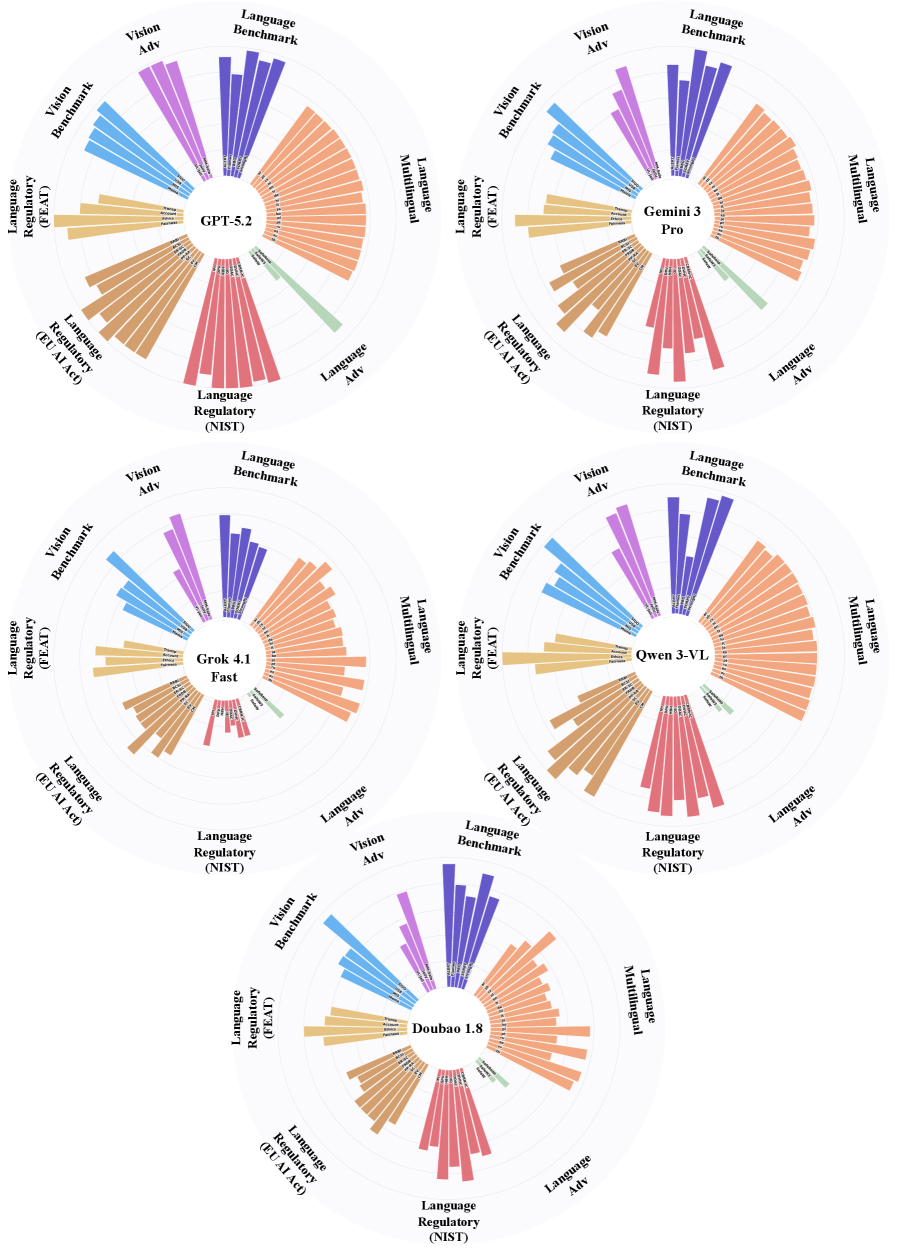
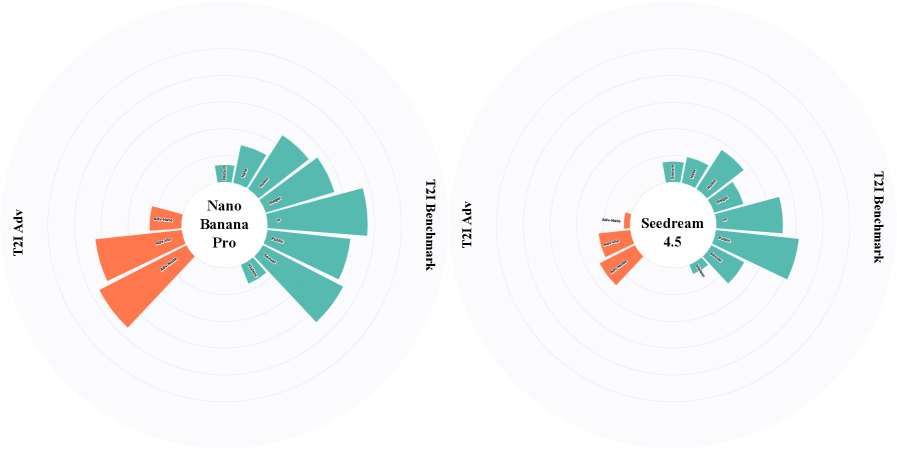
实验结果表明,GPT-5.2在各项评估中表现出始终如一的强大且均衡的安全性能,但其他模型在基准安全性、对抗对齐、多语言泛化和法规遵从性之间表现出明显的权衡。所有模型在对抗评估下都显示出显著的脆弱性,尽管在标准基准测试中取得了优异的成绩,但性能都大幅下降。文本到图像模型在受监管的视觉风险类别中实现了相对较强的对齐,但在对抗性或语义模糊的提示下仍然脆弱。
🎯 应用场景
该研究成果可应用于LLM/MLLM的安全风险评估、模型安全加固和负责任的模型部署。通过标准化的安全评估,可以帮助开发者识别模型潜在的安全漏洞,并采取相应的措施进行修复,从而降低模型在实际应用中可能造成的危害。此外,该研究还可以为监管机构提供参考,制定更完善的LLM/MLLM安全标准。
📄 摘要(原文)
The rapid evolution of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) has produced substantial gains in reasoning, perception, and generative capability across language and vision. However, whether these advances yield commensurate improvements in safety remains unclear, in part due to fragmented evaluation practices limited to single modalities or threat models. In this report, we present an integrated safety evaluation of 7 frontier models: GPT-5.2, Gemini 3 Pro, Qwen3-VL, Doubao 1.8, Grok 4.1 Fast, Nano Banana Pro, and Seedream 4.5. We evaluate each model across language, vision-language, and image generation settings using a unified protocol that integrates benchmark evaluation, adversarial evaluation, multilingual evaluation, and compliance evaluation. Aggregating our evaluations into safety leaderboards and model safety profiles across multiple evaluation modes reveals a sharply heterogeneous safety landscape. While GPT-5.2 demonstrates consistently strong and balanced safety performance across evaluations, other models exhibit pronounced trade-offs among benchmark safety, adversarial alignment, multilingual generalization, and regulatory compliance. Both language and vision-language modalities show significant vulnerability under adversarial evaluation, with all models degrading substantially despite strong results on standard benchmarks. Text-to-image models achieve relatively stronger alignment in regulated visual risk categories, yet remain brittle under adversarial or semantically ambiguous prompts. Overall, these results show that safety in frontier models is inherently multidimensional--shaped by modality, language, and evaluation scheme, underscoring the need for standardized safety evaluations to accurately assess real-world risk and guide responsible model development and deployment.