Model See, Model Do? Exposure-Aware Evaluation of Bug-vs-Fix Preference in Code LLMs
作者: Ali Al-Kaswan, Claudio Spiess, Prem Devanbu, Arie van Deursen, Maliheh Izadi
分类: cs.SE, cs.AI
发布日期: 2026-01-15
备注: MSR 2026 Technical Track
💡 一句话要点
提出一种暴露感知的评估框架,用于评估代码LLM在缺陷代码与修复代码之间的偏好。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码LLM 缺陷修复 暴露感知 模型评估 成员测试
📋 核心要点
- 代码LLM易受训练数据影响,可能偏好或传播已知的缺陷代码,现有评估方法缺乏对训练数据暴露的考虑。
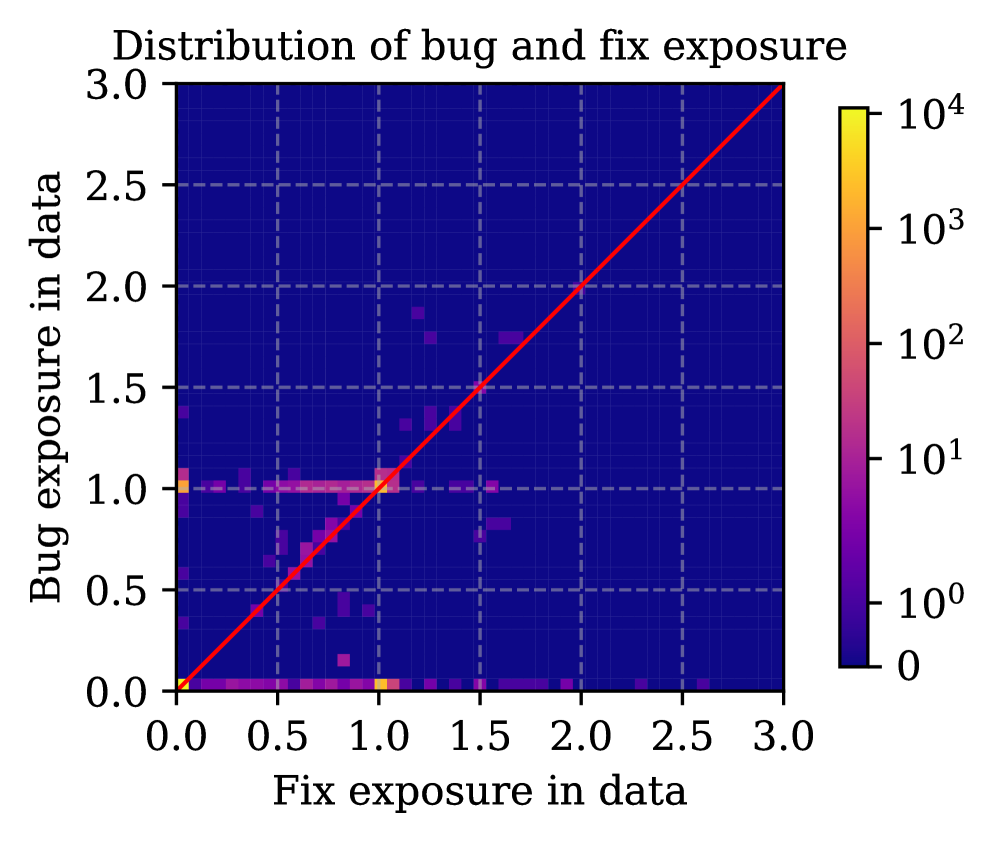
- 提出暴露感知评估框架,通过成员测试估计训练集中缺陷和修复代码的暴露情况,并分层评估模型偏好。
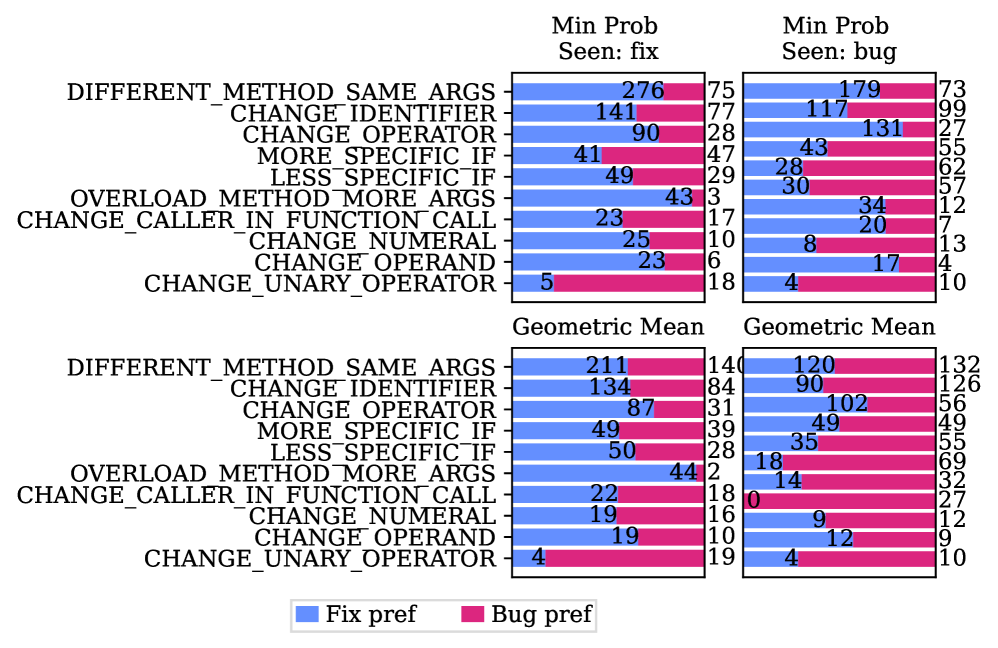
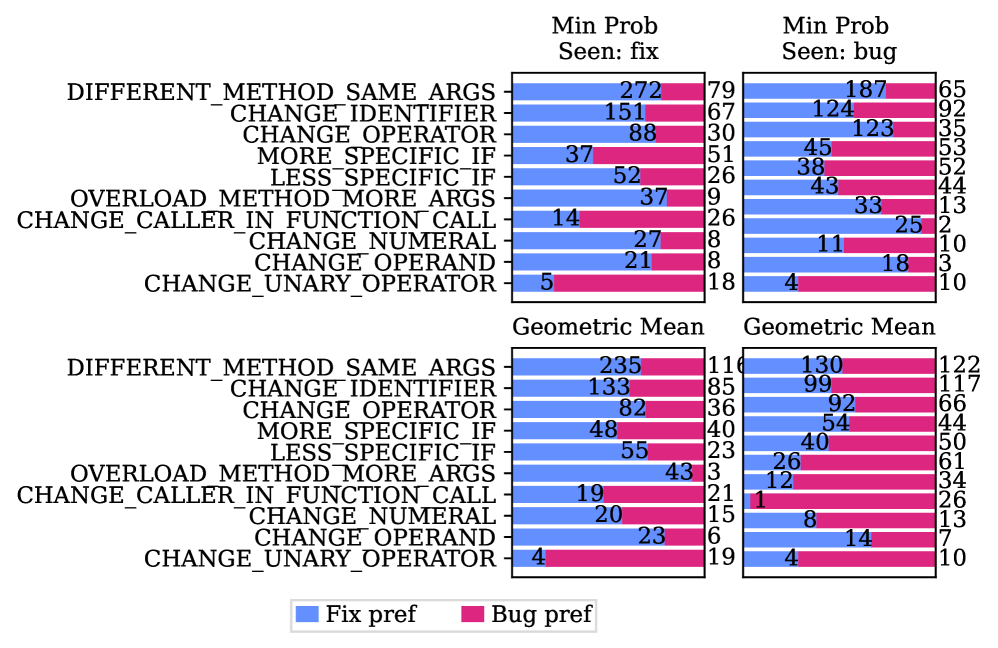
- 实验表明,模型更倾向于生成缺陷代码,尤其是在暴露于缺陷代码时,但基于似然性的评分指标在一定程度上能识别修复。
📝 摘要(中文)
大型语言模型越来越多地用于代码生成和调试,但其输出仍然可能包含源于训练数据的缺陷。区分LLM是偏好正确的代码,还是偏好其熟悉的错误版本,可能受到训练期间接触的影响。我们引入了一种暴露感知的评估框架,该框架量化了先前暴露于缺陷代码与修复代码对模型偏好的影响。我们使用ManySStuBs4J基准,应用Data Portraits对Stack-V2语料库进行成员测试,以估计每个缺陷和修复变体是否在训练期间被看到。然后,我们按暴露情况对示例进行分层,并使用代码补全以及多个基于似然性的评分指标来比较模型偏好。我们发现,大多数示例(67%)的训练数据中都没有这两种变体,并且当只有一种变体存在时,修复比缺陷更常见。在模型生成中,模型重现缺陷行的频率远高于修复,暴露于缺陷的示例放大了这种趋势,而暴露于修复的示例仅显示出边际改进。在似然性评分中,最小和最大token概率指标始终偏好所有条件下的修复代码,表明对正确修复的稳定偏好。相比之下,当仅看到缺陷变体时,诸如Gini系数之类的指标会反转偏好。我们的结果表明,暴露可能会扭曲缺陷修复评估,并突显了LLM在实践中可能传播记忆错误的风险。
🔬 方法详解
问题定义:论文旨在解决代码LLM在缺陷代码和修复代码之间偏好评估的问题。现有评估方法没有充分考虑模型在训练过程中对缺陷代码和修复代码的暴露情况,这可能导致评估结果产生偏差。例如,如果模型在训练集中大量接触到某个特定的缺陷代码,它可能会倾向于生成或偏好该缺陷代码,即使存在正确的修复方案。因此,需要一种能够感知模型暴露情况的评估方法,以更准确地衡量模型对缺陷和修复的真实偏好。
核心思路:论文的核心思路是引入“暴露感知”的概念,即在评估代码LLM对缺陷和修复的偏好时,需要考虑模型在训练过程中是否以及如何接触过这些代码。通过分析训练数据,确定模型是否见过特定的缺陷代码或修复代码,并将这些信息纳入评估过程。这样可以更准确地判断模型是真正理解了修复方案,还是仅仅记住了训练数据中的缺陷代码。
技术框架:该评估框架主要包含以下几个阶段:1) 数据准备:使用ManySStuBs4J基准数据集,该数据集包含缺陷代码和对应的修复代码。2) 暴露估计:使用Data Portraits技术对Stack-V2语料库进行成员测试,以估计每个缺陷和修复变体是否在训练期间被看到。Data Portraits是一种用于检测给定数据样本是否属于某个数据集的技术。3) 分层评估:根据暴露情况对示例进行分层,例如“仅暴露于缺陷代码”、“仅暴露于修复代码”、“均未暴露”等。4) 模型评估:使用代码补全和基于似然性的评分指标来评估模型在不同暴露情况下的偏好。代码补全任务要求模型根据给定的上下文生成代码,然后比较生成代码与缺陷代码和修复代码的相似度。基于似然性的评分指标则通过计算模型生成缺陷代码和修复代码的概率来评估模型偏好。
关键创新:该论文最重要的技术创新点在于提出了“暴露感知”的评估方法。与传统的评估方法相比,该方法能够更准确地衡量代码LLM对缺陷和修复的真实偏好,避免了因训练数据偏差而导致的评估结果失真。通过将暴露信息纳入评估过程,可以更好地了解模型是如何学习和处理缺陷代码和修复代码的。
关键设计:在暴露估计方面,使用了Data Portraits技术,这是一种高效且准确的成员测试方法。在模型评估方面,使用了多种代码补全和基于似然性的评分指标,例如最小和最大token概率、Gini系数等,这些指标可以从不同角度衡量模型对缺陷和修复的偏好。此外,论文还特别关注了不同暴露情况下的模型表现,通过分层评估,可以更清晰地了解暴露对模型偏好的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,模型在生成代码时更倾向于重现缺陷代码,尤其是在暴露于缺陷代码时。然而,基于似然性的评分指标(如最小和最大token概率)在所有条件下都更偏好修复代码,表明模型在一定程度上能够识别正确的修复方案。当仅看到缺陷变体时,Gini系数等指标会反转偏好,突显了暴露对模型评估的影响。
🎯 应用场景
该研究成果可应用于代码LLM的评估和改进,帮助开发者更好地了解模型的缺陷修复能力,并针对性地优化训练数据,减少模型生成缺陷代码的风险。此外,该方法也可用于评估其他类型的AI模型,例如文本生成模型,以避免模型传播训练数据中的错误信息。
📄 摘要(原文)
Large language models are increasingly used for code generation and debugging, but their outputs can still contain bugs, that originate from training data. Distinguishing whether an LLM prefers correct code, or a familiar incorrect version might be influenced by what it's been exposed to during training. We introduce an exposure-aware evaluation framework that quantifies how prior exposure to buggy versus fixed code influences a model's preference. Using the ManySStuBs4J benchmark, we apply Data Portraits for membership testing on the Stack-V2 corpus to estimate whether each buggy and fixed variant was seen during training. We then stratify examples by exposure and compare model preference using code completion as well as multiple likelihood-based scoring metrics We find that most examples (67%) have neither variant in the training data, and when only one is present, fixes are more frequently present than bugs. In model generations, models reproduce buggy lines far more often than fixes, with bug-exposed examples amplifying this tendency and fix-exposed examples showing only marginal improvement. In likelihood scoring, minimum and maximum token-probability metrics consistently prefer the fixed code across all conditions, indicating a stable bias toward correct fixes. In contrast, metrics like the Gini coefficient reverse preference when only the buggy variant was seen. Our results indicate that exposure can skew bug-fix evaluations and highlight the risk that LLMs may propagate memorised errors in practice.