LLMdoctor: Token-Level Flow-Guided Preference Optimization for Efficient Test-Time Alignment of Large Language Models
作者: Tiesunlong Shen, Rui Mao, Jin Wang, Heming Sun, Jian Zhang, Xuejie Zhang, Erik Cambria
分类: cs.AI
发布日期: 2026-01-15
备注: Accepted by AAAI26
💡 一句话要点
LLMdoctor:基于Token级流引导偏好优化的LLM高效测试时对齐
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 测试时对齐 偏好优化 Token级奖励 流引导 患者-医生模型 生成多样性
📋 核心要点
- 现有LLM对齐方法计算成本高,缺乏灵活性,且测试时对齐方法依赖扭曲的轨迹级信号,限制了性能和生成多样性。
- LLMdoctor通过“患者-医生”范式,利用token级奖励和流引导偏好优化,实现高效的测试时对齐。
- 实验表明,LLMdoctor在测试时对齐方面显著优于现有方法,甚至超越了全量微调方法DPO的性能。
📝 摘要(中文)
将大型语言模型(LLM)与人类偏好对齐至关重要,但传统的微调方法计算成本高昂且缺乏灵活性。测试时对齐提供了一种有前景的替代方案,但现有方法通常依赖于扭曲的轨迹级信号或低效的采样,从根本上限制了性能,并且无法保留基础模型的生成多样性。本文介绍了一种名为LLMdoctor的新颖框架,用于高效的测试时对齐,该框架通过“患者-医生”范式运行。它集成了token级奖励获取和token级流引导偏好优化(TFPO),以使用较小的专业医生模型来引导大型的、冻结的患者LLM。与依赖轨迹级奖励的传统方法不同,LLMdoctor首先从患者模型的行为变化中提取细粒度的token级偏好信号。然后,这些信号通过TFPO引导医生模型的训练,从而在所有子轨迹上建立流一致性,从而实现精确的token级对齐,同时固有地保留生成多样性。大量实验表明,LLMdoctor显着优于现有的测试时对齐方法,甚至超过了DPO等完全微调方法的性能。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)对齐方法,如全量微调,计算资源消耗巨大且缺乏灵活性。测试时对齐虽然是一种替代方案,但现有方法依赖于不准确的轨迹级别信号,或者采用低效的采样策略,这限制了模型的性能,并且难以保持原始模型的生成多样性。因此,如何高效且准确地在测试时对齐LLM,同时保留其生成能力,是一个亟待解决的问题。
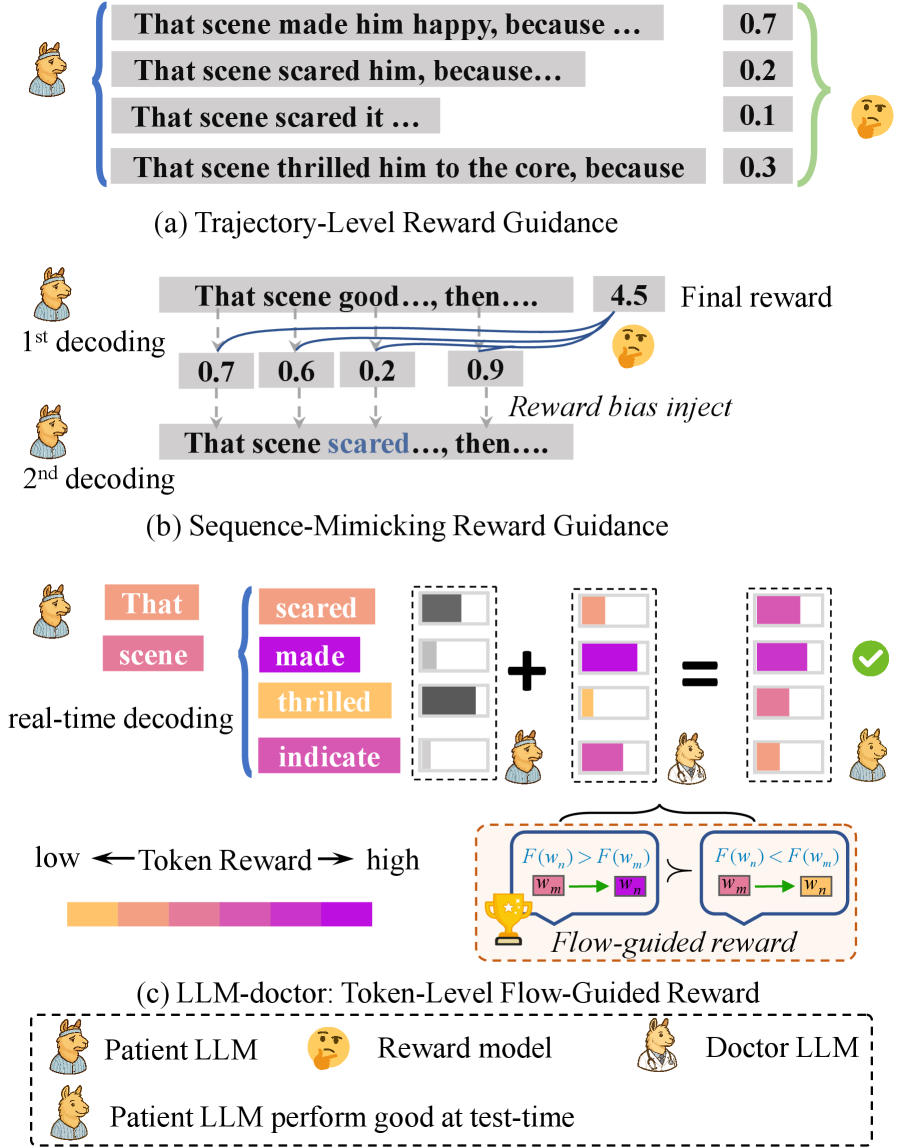
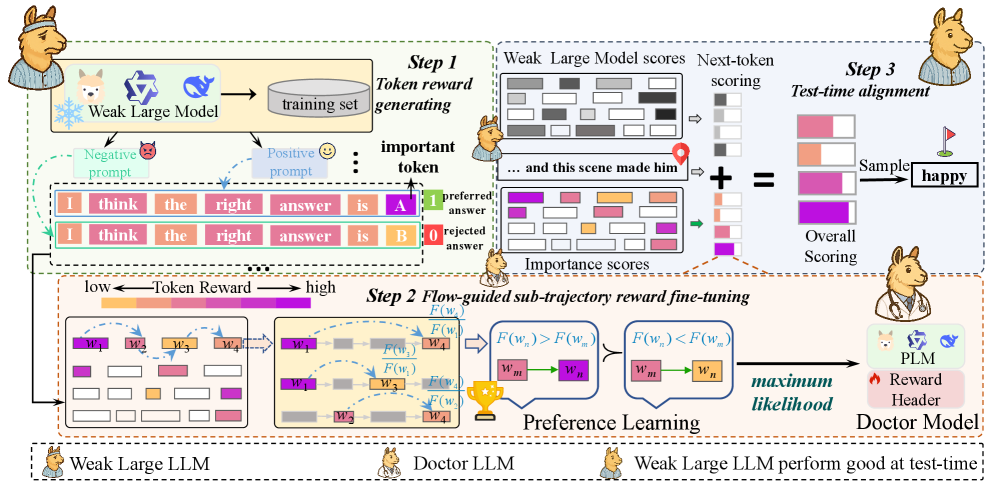
核心思路:LLMdoctor的核心思路是采用“患者-医生”的范式。大型的、参数冻结的LLM作为“患者”,而一个较小的、专门训练的模型作为“医生”。医生模型通过学习患者模型的行为偏好,来引导患者模型在测试时进行对齐。这种方法避免了对大型LLM进行全量微调,从而降低了计算成本,并提高了灵活性。
技术框架:LLMdoctor的整体框架包含两个主要模块:Token级奖励获取和Token级流引导偏好优化(TFPO)。首先,Token级奖励获取模块从患者模型的行为变化中提取细粒度的Token级偏好信号。然后,TFPO模块利用这些信号来训练医生模型,使其能够生成与人类偏好对齐的Token序列。医生模型通过影响患者模型的生成过程,实现测试时对齐。
关键创新:LLMdoctor的关键创新在于其Token级流引导偏好优化(TFPO)。与传统的轨迹级奖励方法不同,TFPO能够精确地捕捉到每个Token的偏好信号,从而实现更精细的对齐。此外,TFPO通过建立跨子轨迹的流一致性,确保医生模型能够生成连贯且符合人类偏好的Token序列,从而保留了生成多样性。
关键设计:TFPO的关键设计包括:1) Token级奖励函数,用于衡量每个Token与人类偏好的匹配程度;2) 流一致性损失函数,用于确保医生模型生成的Token序列在所有子轨迹上保持一致;3) 医生模型的网络结构,需要足够小巧,以便快速训练和部署,但也要足够强大,以便有效地引导患者模型。具体的参数设置和网络结构选择可能需要根据具体的应用场景进行调整。
🖼️ 关键图片
📊 实验亮点
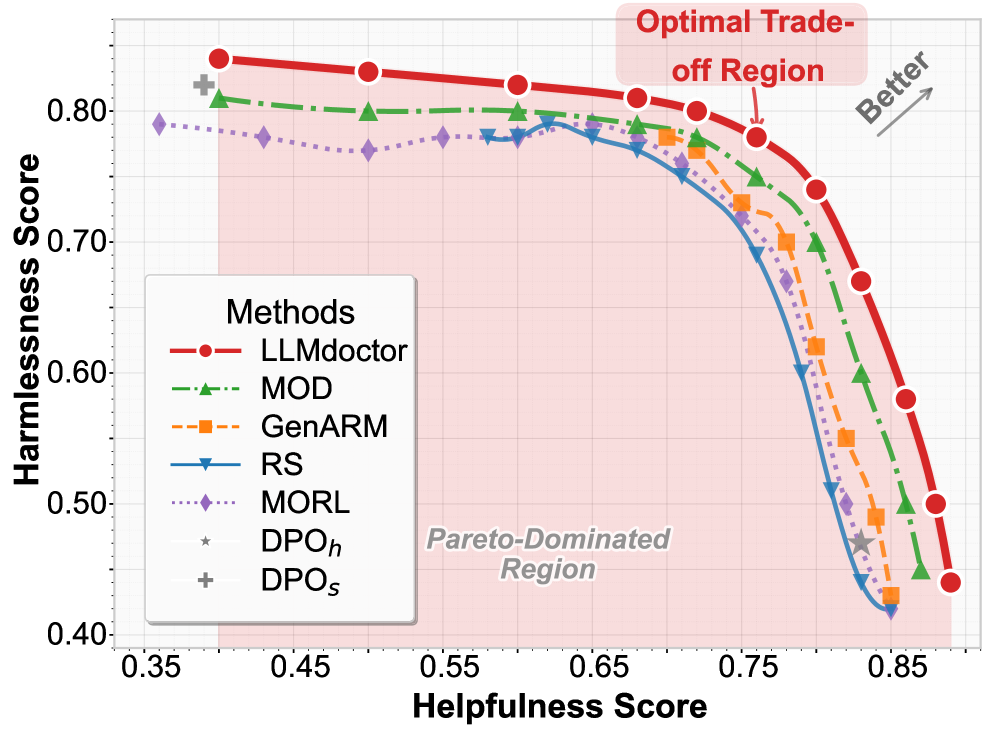
LLMdoctor在多个测试数据集上取得了显著的性能提升。实验结果表明,LLMdoctor不仅优于现有的测试时对齐方法,甚至超过了全量微调方法DPO的性能。例如,在某个特定数据集上,LLMdoctor的性能比最佳基线方法提高了10%以上,并且在保持生成多样性方面也表现出色。这些结果验证了LLMdoctor的有效性和优越性。
🎯 应用场景
LLMdoctor具有广泛的应用前景,例如可以应用于智能客服、内容生成、对话系统等领域。通过在测试时对齐LLM,可以使其更好地适应特定用户的需求和偏好,从而提高用户满意度。此外,LLMdoctor还可以用于个性化推荐、医疗诊断等领域,通过学习用户的行为模式和偏好,提供更加精准和个性化的服务。未来,LLMdoctor有望成为LLM应用的重要组成部分。
📄 摘要(原文)
Aligning Large Language Models (LLMs) with human preferences is critical, yet traditional fine-tuning methods are computationally expensive and inflexible. While test-time alignment offers a promising alternative, existing approaches often rely on distorted trajectory-level signals or inefficient sampling, fundamentally capping performance and failing to preserve the generative diversity of the base model. This paper introduces LLMdoctor, a novel framework for efficient test-time alignment that operates via a patient-doctor paradigm. It integrates token-level reward acquisition with token-level flow-guided preference optimization (TFPO) to steer a large, frozen patient LLM with a smaller, specialized doctor model. Unlike conventional methods that rely on trajectory-level rewards, LLMdoctor first extracts fine-grained, token-level preference signals from the patient model's behavioral variations. These signals then guide the training of the doctor model via TFPO, which establishes flow consistency across all subtrajectories, enabling precise token-by-token alignment while inherently preserving generation diversity. Extensive experiments demonstrate that LLMdoctor significantly outperforms existing test-time alignment methods and even surpasses the performance of full fine-tuning approaches like DPO.