NoReGeo: Non-Reasoning Geometry Benchmark
作者: Irina Abdullaeva, Anton Vasiliuk, Elizaveta Goncharova, Temurbek Rahmatullaev, Zagorulko Ivan, Maxim Kurkin, Andrey Kuznetsov
分类: cs.AI
发布日期: 2026-01-15
💡 一句话要点
提出NoReGeo:用于评估LLM几何理解能力的新型无推理几何基准
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 几何理解 大型语言模型 基准测试 非推理 空间关系
📋 核心要点
- 现有几何基准侧重于考察模型基于推理的几何能力,依赖代数方法求解,忽略了模型对几何属性的直接理解。
- NoReGeo基准旨在评估LLM在已知对象位置的条件下,仅通过原生几何理解解决问题的能力,无需推理或代数计算。
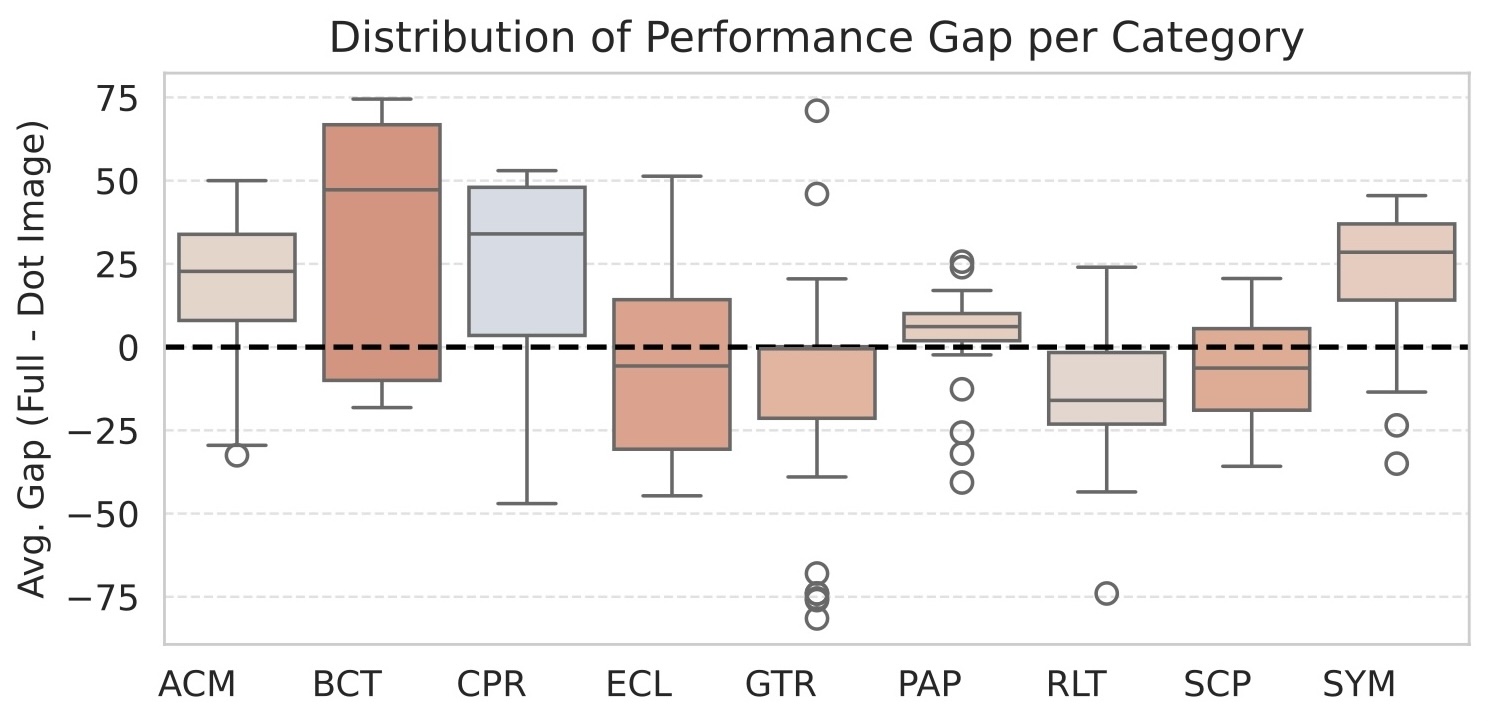
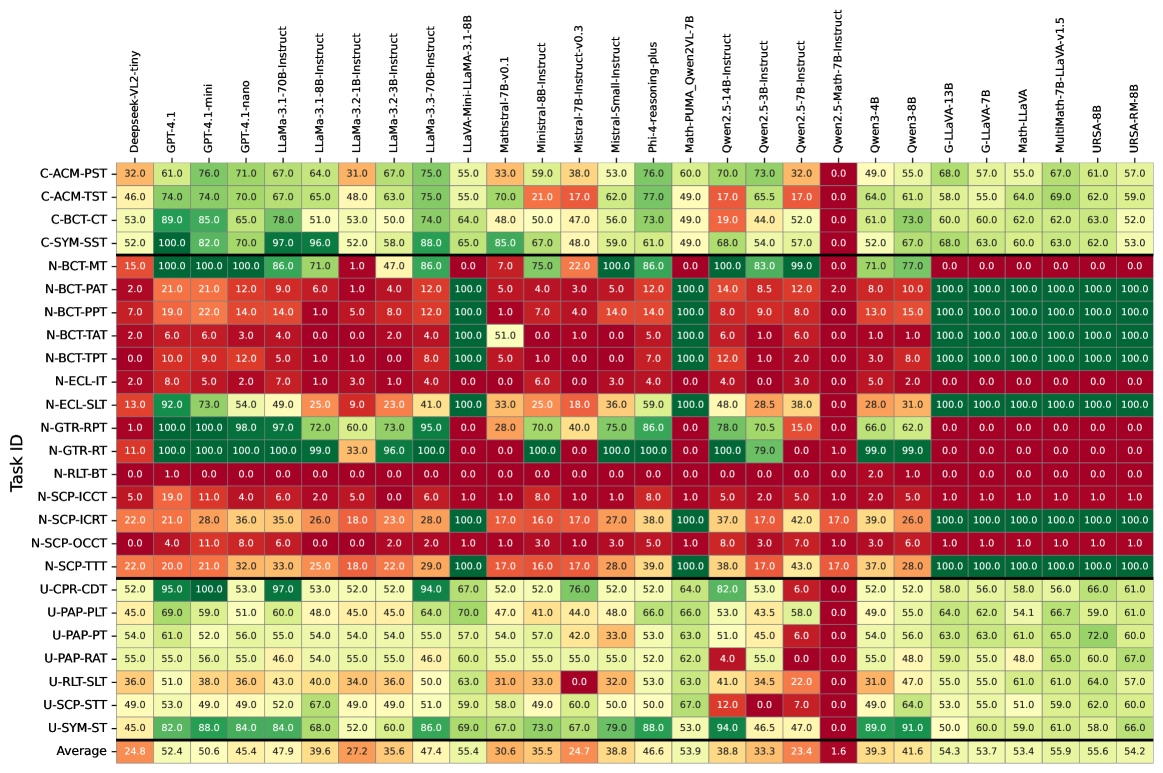
- 实验结果表明,即使是GPT-4等先进模型在NoReGeo上的准确率也仅为65%,且微调无法有效提升几何理解能力。
📝 摘要(中文)
本文提出NoReGeo,一种新型基准,旨在评估大型语言模型(LLM)固有的几何理解能力,而不依赖于推理或代数计算。与主要评估模型基于推理的几何能力(即使用代数方法推导解决方案)的现有基准不同,NoReGeo侧重于评估LLM是否能够固有地编码空间关系并直接识别几何属性。该基准包含2500个简单的几何问题,涵盖25个类别,每个问题都经过精心设计,仅通过原生的几何理解即可解决,假设已知对象位置。我们评估了NoReGeo上的一系列最先进的模型,包括GPT-4等前沿模型,观察到即使是最先进的系统在二元分类任务中的总体最高准确率也仅为65%。此外,我们的消融实验表明,这种几何理解并非仅通过微调就能产生,表明有效的几何理解训练需要从一开始就采用专门的方法。我们的研究结果突出了当前LLM在原生掌握几何概念方面的显著差距,为未来研究具有真正几何认知能力的模型奠定了基础。
🔬 方法详解
问题定义:现有几何基准主要评估LLM通过代数推理解决几何问题的能力,忽略了LLM对几何概念和空间关系的直接理解。这些基准无法有效衡量LLM是否真正具备“几何直觉”,而更多地是测试其代数运算和逻辑推理能力。因此,需要一种新的基准来专门评估LLM固有的几何理解能力。
核心思路:NoReGeo的核心思路是设计一系列简单的几何问题,这些问题不需要复杂的代数运算或逻辑推理,仅通过观察和理解基本的几何概念和空间关系即可解决。通过这种方式,可以更直接地评估LLM是否具备对几何形状、位置和关系的内在理解。
技术框架:NoReGeo基准包含2500个问题,分为25个类别,涵盖了基本的几何概念,如点、线、角、形状等。每个问题都以二元分类的形式呈现,要求模型判断给定的几何关系是否成立。问题的设计保证了在已知对象位置的前提下,仅通过原生几何理解即可解决。评估过程直接测量模型在这些简单几何任务上的准确率。
关键创新:NoReGeo的关键创新在于其专注于评估LLM的“非推理”几何理解能力。与以往的基准不同,NoReGeo避免了需要代数运算或复杂推理的问题,而是侧重于考察LLM对基本几何概念的直接感知和理解。这种设计使得NoReGeo能够更准确地反映LLM在几何认知方面的真实水平。
关键设计:NoReGeo的问题设计力求简洁明了,避免歧义。每个问题都包含清晰的几何图形和明确的判断目标。为了保证问题的难度适中,所有问题都设计为仅通过基本的几何概念和空间关系即可解决。此外,基准还包含了消融实验,用于评估微调对几何理解能力的影响。消融实验的结果表明,仅通过微调无法有效提升LLM的几何理解能力,需要从一开始就采用专门的训练方法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使是GPT-4等最先进的LLM在NoReGeo上的总体准确率也仅为65%,这表明当前LLM在原生几何理解方面存在显著差距。消融实验进一步表明,仅通过微调无法有效提升LLM的几何理解能力,需要从一开始就采用专门的训练方法。这些发现为未来研究如何有效提升LLM的几何认知能力提供了重要的指导。
🎯 应用场景
NoReGeo基准的提出,为未来开发具有更强几何认知能力的LLM奠定了基础。这些模型可以应用于机器人导航、自动驾驶、计算机辅助设计(CAD)等领域,提升机器在三维空间中的感知、推理和决策能力。此外,该基准还可以用于评估和改进LLM在其他涉及空间推理的任务中的表现。
📄 摘要(原文)
We present NoReGeo, a novel benchmark designed to evaluate the intrinsic geometric understanding of large language models (LLMs) without relying on reasoning or algebraic computation. Unlike existing benchmarks that primarily assess models' proficiency in reasoning-based geometry-where solutions are derived using algebraic methods-NoReGeo focuses on evaluating whether LLMs can inherently encode spatial relationships and recognize geometric properties directly. Our benchmark comprises 2,500 trivial geometric problems spanning 25 categories, each carefully crafted to be solvable purely through native geometric understanding, assuming known object locations. We assess a range of state-of-the-art models on NoReGeo, including frontier models like GPT-4, observing that even the most advanced systems achieve an overall maximum of 65% accuracy in binary classification tasks. Further, our ablation experiments demonstrate that such geometric understanding does not emerge through fine-tuning alone, indicating that effective training for geometric comprehension requires a specialized approach from the outset. Our findings highlight a significant gap in current LLMs' ability to natively grasp geometric concepts, providing a foundation for future research toward models with true geometric cognition.