DecisionLLM: Large Language Models for Long Sequence Decision Exploration
作者: Xiaowei Lv, Zhilin Zhang, Yijun Li, Yusen Huo, Siyuan Ju, Xuyan Li, Chunxiang Hong, Tianyu Wang, Yongcai Wang, Peng Sun, Chuan Yu, Jian Xu, Bo Zheng
分类: cs.AI
发布日期: 2026-01-15
💡 一句话要点
提出DecisionLLM以解决长序列决策探索问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长序列决策 大型语言模型 自回归建模 轨迹对齐 强化学习 动态环境 决策支持
📋 核心要点
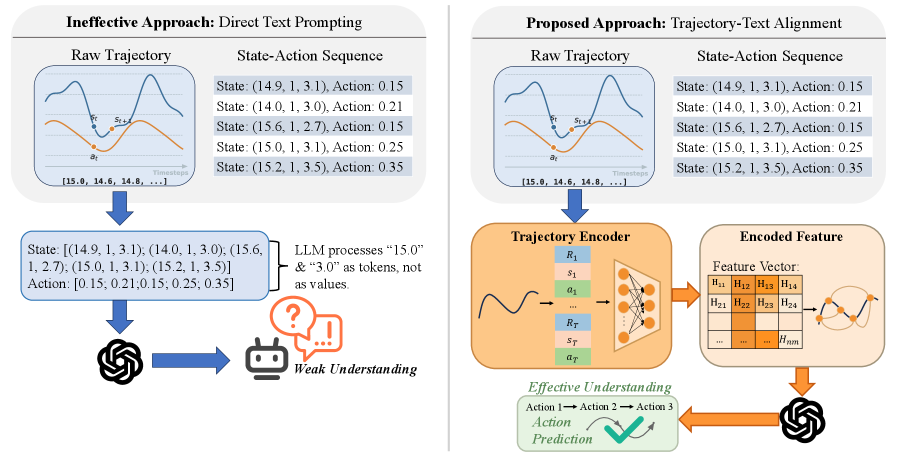
- 长序列决策制定面临LLMs无法理解连续值的挑战,限制了其在决策任务中的应用。
- 提出将决策轨迹视为独特模态,通过自然语言描述对齐轨迹数据,构建DecisionLLM模型。
- 在离线基准测试中,DecisionLLM-3B在多个任务上显著超越传统方法,展示了其强大的性能提升。
📝 摘要(中文)
长序列决策制定通常通过强化学习(RL)来解决,是动态环境中优化战略操作的关键组成部分。Decision Transformer(DT)通过将RL框架化为自回归序列建模问题,提出了一种强大的范式。与此同时,大型语言模型(LLMs)在复杂推理和规划任务中表现出色。本文探讨LLMs在离线决策任务中的应用,提出将轨迹视为一种独特的模态,通过学习将轨迹数据与自然语言任务描述对齐,构建了DecisionLLM模型。我们建立了一套支配这一范式的扩展法则,表明性能依赖于模型规模、数据量和数据质量。在离线实验基准和竞标场景中,DecisionLLM表现出色,尤其是DecisionLLM-3B在Maze2D umaze-v1上超越传统DT达69.4,在AuctionNet上超越0.085,扩展了AIGB范式,为未来在线竞标探索指明了方向。
🔬 方法详解
问题定义:本文旨在解决长序列决策制定中的连续值理解问题,现有方法在处理数值时存在局限性,影响决策效果。
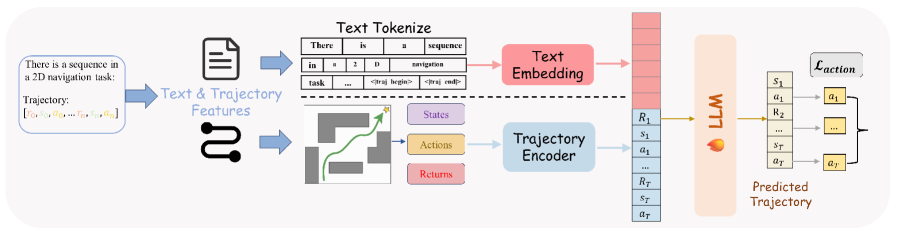
核心思路:通过将决策轨迹视为一种独特的模态,学习将轨迹数据与自然语言任务描述对齐,从而实现自回归预测未来决策。
技术框架:整体架构包括数据预处理、轨迹与语言对齐、模型训练和决策预测四个主要模块。数据预处理阶段将轨迹数据转换为适合模型输入的格式,接着通过对齐模块实现轨迹与语言的关联,最后进行模型训练和决策预测。
关键创新:最重要的创新在于将轨迹视为独特模态的处理方式,使得LLMs能够有效理解和预测连续值决策,与传统方法相比,提升了决策的准确性和效率。
关键设计:在模型设计中,采用了特定的损失函数来优化轨迹与语言对齐的效果,并在网络结构上进行了调整,以适应长序列数据的处理需求。
🖼️ 关键图片
📊 实验亮点
在实验中,DecisionLLM-3B在Maze2D umaze-v1任务上超越传统Decision Transformer(DT)达69.4分,在AuctionNet上提升0.085,显示出显著的性能优势。这些结果表明,DecisionLLM在长序列决策任务中具有强大的应用潜力。
🎯 应用场景
该研究在动态环境中的长序列决策制定领域具有广泛的应用潜力,尤其是在实时竞标、智能交通管理和金融决策等场景中。通过提升决策的准确性和效率,DecisionLLM能够为企业和组织提供更优的决策支持,推动相关领域的发展。
📄 摘要(原文)
Long-sequence decision-making, which is usually addressed through reinforcement learning (RL), is a critical component for optimizing strategic operations in dynamic environments, such as real-time bidding in computational advertising. The Decision Transformer (DT) introduced a powerful paradigm by framing RL as an autoregressive sequence modeling problem. Concurrently, Large Language Models (LLMs) have demonstrated remarkable success in complex reasoning and planning tasks. This inspires us whether LLMs, which share the same Transformer foundation, but operate at a much larger scale, can unlock new levels of performance in long-horizon sequential decision-making problem. This work investigates the application of LLMs to offline decision making tasks. A fundamental challenge in this domain is the LLMs' inherent inability to interpret continuous values, as they lack a native understanding of numerical magnitude and order when values are represented as text strings. To address this, we propose treating trajectories as a distinct modality. By learning to align trajectory data with natural language task descriptions, our model can autoregressively predict future decisions within a cohesive framework we term DecisionLLM. We establish a set of scaling laws governing this paradigm, demonstrating that performance hinges on three factors: model scale, data volume, and data quality. In offline experimental benchmarks and bidding scenarios, DecisionLLM achieves strong performance. Specifically, DecisionLLM-3B outperforms the traditional Decision Transformer (DT) by 69.4 on Maze2D umaze-v1 and by 0.085 on AuctionNet. It extends the AIGB paradigm and points to promising directions for future exploration in online bidding.