Is More Context Always Better? Examining LLM Reasoning Capability for Time Interval Prediction
作者: Yanan Cao, Farnaz Fallahi, Murali Mohana Krishna Dandu, Lalitesh Morishetti, Kai Zhao, Luyi Ma, Sinduja Subramaniam, Jianpeng Xu, Evren Korpeoglu, Kaushiki Nag, Sushant Kumar, Kannan Achan
分类: cs.AI, cs.LG
发布日期: 2026-01-15
备注: Accepted at The Web Conference 2026 (WWW 2026)
💡 一句话要点
研究表明,过度提供用户行为上下文信息反而会降低LLM对时间间隔预测的准确性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 时间序列预测 上下文学习 用户行为分析 零样本学习
📋 核心要点
- 现有方法难以有效利用LLM从结构化行为数据中推断时间规律,尤其是在预测用户行为时间间隔方面。
- 该研究通过系统实验,考察了不同程度的上下文信息对LLM预测用户重复购买时间间隔的影响。
- 实验表明,LLM在时间间隔预测方面不如专用机器学习模型,且过度提供上下文信息会降低预测准确性。
📝 摘要(中文)
大型语言模型(LLM)在不同领域的推理和预测方面表现出令人印象深刻的能力。然而,它们从结构化行为数据中推断时间规律的能力仍未得到充分探索。本文对LLM预测用户重复行为(如重复购买)之间的时间间隔的能力进行了系统研究,并探讨了不同程度的上下文信息如何影响其预测行为。通过一个简单但具有代表性的重复购买场景,我们在零样本设置下,将最先进的LLM与统计和机器学习模型进行了基准测试。研究结果表明,虽然LLM优于轻量级统计基线,但始终不如专门的机器学习模型,表明它们在捕捉定量时间结构方面的能力有限。此外,虽然适度的上下文可以提高LLM的准确性,但添加更多的用户级别细节会降低性能。这些结果挑战了“更多上下文带来更好推理”的假设。我们的研究强调了当前LLM在结构化时间推理方面的根本局限性,并为设计未来的上下文感知混合模型提供了指导,这些模型将统计精度与语言灵活性相结合。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在预测用户重复行为(例如,重复购买)之间的时间间隔方面的能力。现有方法,特别是直接应用LLM的方法,在捕捉定量时间结构方面存在局限性,并且对上下文信息的利用方式尚不明确。一个关键的痛点是,是否提供更多的上下文信息总能提升LLM的预测性能,这需要进一步的实验验证。
核心思路:论文的核心思路是通过系统性的实验,评估LLM在不同上下文信息量下的时间间隔预测能力。通过控制提供给LLM的上下文信息,例如用户历史行为的详细程度,来观察LLM预测性能的变化。这种方法旨在揭示LLM在处理结构化时间数据时的优势和局限性,并挑战“更多上下文带来更好推理”的假设。
技术框架:研究采用了一个重复购买的场景作为实验平台。整体流程包括:1)构建包含用户行为数据的结构化数据集;2)设计不同的上下文信息输入方案,例如仅提供用户ID,或提供用户详细的历史购买记录;3)使用不同的LLM模型进行零样本预测;4)将LLM的预测结果与统计基线模型(如平均时间间隔)和机器学习模型(如时间序列模型)进行比较;5)分析不同上下文信息量下LLM的预测准确性。
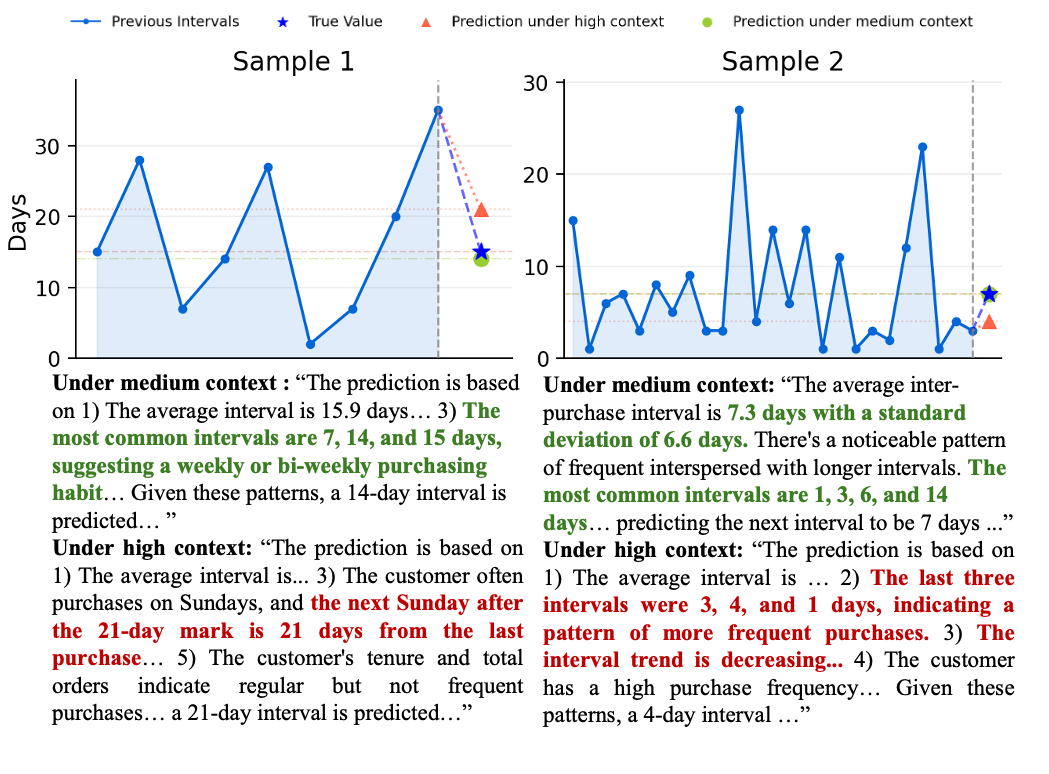
关键创新:该研究的关键创新在于它系统地考察了上下文信息量对LLM时间间隔预测性能的影响。以往的研究可能更多关注LLM在自然语言处理任务上的表现,而忽略了其在结构化时间数据处理方面的能力。该研究通过实验证明,过度提供上下文信息反而会降低LLM的预测准确性,这挑战了传统的认知。
关键设计:研究的关键设计包括:1)选择重复购买场景,该场景具有明确的时间结构和可控的上下文信息;2)设计多种上下文信息输入方案,例如仅提供用户ID、提供用户历史购买记录、提供用户人口统计信息等;3)采用零样本学习设置,避免对LLM进行特定任务的微调,从而更好地评估其泛化能力;4)使用多种评估指标,例如平均绝对误差(MAE)和均方根误差(RMSE),来衡量预测准确性。
🖼️ 关键图片
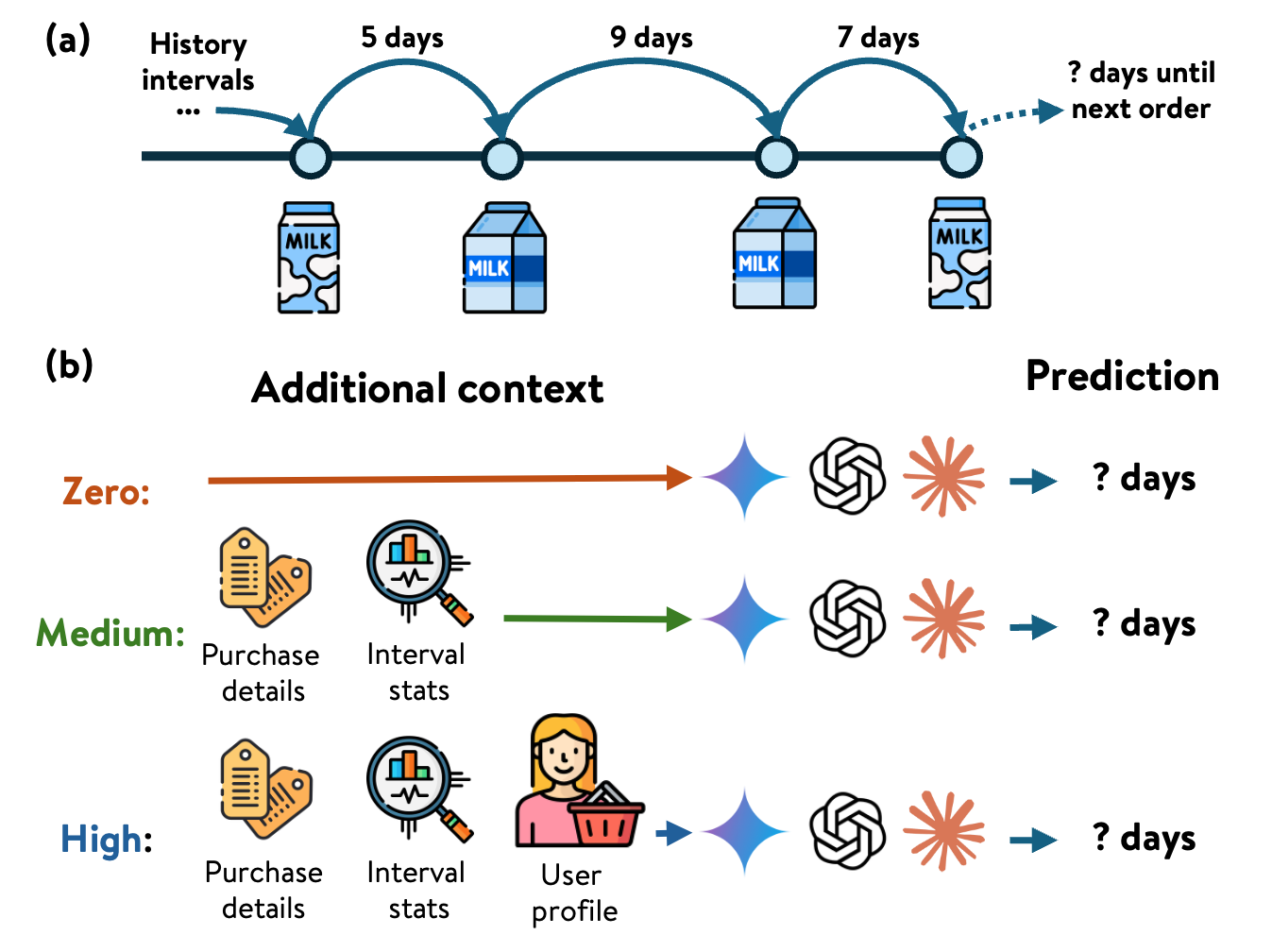

📊 实验亮点
实验结果表明,虽然LLM在零样本设置下优于简单的统计基线,但在时间间隔预测任务中,其性能始终低于专门的机器学习模型。更重要的是,研究发现,适度的上下文信息可以提高LLM的预测准确性,但过度提供用户级别的详细信息反而会降低性能。例如,在某些实验中,添加用户的人口统计信息导致预测误差增加了10%-20%。
🎯 应用场景
该研究的潜在应用领域包括用户行为预测、个性化推荐系统、供应链管理和金融风险评估。通过更好地理解LLM在时间序列数据上的推理能力,可以开发更智能的预测模型,从而优化资源分配、提高用户满意度并降低运营成本。未来的研究可以探索如何将LLM与传统的统计和机器学习模型相结合,构建更强大的混合预测系统。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning and prediction across different domains. Yet, their ability to infer temporal regularities from structured behavioral data remains underexplored. This paper presents a systematic study investigating whether LLMs can predict time intervals between recurring user actions, such as repeated purchases, and how different levels of contextual information shape their predictive behavior. Using a simple but representative repurchase scenario, we benchmark state-of-the-art LLMs in zero-shot settings against both statistical and machine-learning models. Two key findings emerge. First, while LLMs surpass lightweight statistical baselines, they consistently underperform dedicated machine-learning models, showing their limited ability to capture quantitative temporal structure. Second, although moderate context can improve LLM accuracy, adding further user-level detail degrades performance. These results challenge the assumption that "more context leads to better reasoning". Our study highlights fundamental limitations of today's LLMs in structured temporal inference and offers guidance for designing future context-aware hybrid models that integrate statistical precision with linguistic flexibility.