Following the Teacher's Footsteps: Scheduled Checkpoint Distillation for Domain-Specific LLMs
作者: Cheng Feng, Chaoliang Zhong, Jun Sun, Yusuke Oishi
分类: cs.AI
发布日期: 2026-01-15
备注: 15 pages, submitted to ICPR 2026
💡 一句话要点
提出Scheduled Checkpoint Distillation方法,提升领域特定LLM蒸馏性能,使小模型超越教师模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 领域特定LLM 模型压缩 自适应加权 监督微调
📋 核心要点
- 领域特定LLM部署困难,直接蒸馏效果不佳,学生模型难以超越教师模型。
- 论文提出Scheduled Checkpoint Distillation (SCD)方法,模拟教师收敛过程,并自适应调整样本权重。
- 实验表明,SCD方法在多种领域任务上超越现有蒸馏方法,学生模型性能匹配甚至超过教师模型。
📝 摘要(中文)
由于大规模语言模型(LLMs)的巨大规模,将其部署到领域特定任务中具有挑战性。将微调后的LLM提炼成较小的学生模型是一种有前景的替代方案,但教师和学生之间的能力差距通常会导致次优性能。这就提出了一个关键问题:学生模型何时以及如何才能在领域特定任务上匹配甚至超过其教师?在这项工作中,我们提出了一个新的理论见解:如果学生在学生优势子域(SFS)上的优势超过其在教师优势子域(TFS)上的不足,那么学生可以胜过其教师。在该理论的指导下,我们提出了Scheduled Checkpoint Distillation (SCD),它通过在领域任务上的监督微调(SFT)期间模拟教师的收敛过程来减少TFS不足,以及一种样本自适应加权(AW)机制来保持学生在SFS上的优势。在包括QA、NER和多语言文本分类在内的各种领域任务上的实验表明,我们的方法始终优于现有的蒸馏方法,从而使学生模型能够匹配甚至超过其微调教师的性能。
🔬 方法详解
问题定义:论文旨在解决领域特定大型语言模型(LLM)蒸馏中,学生模型因能力差距难以超越教师模型的问题。现有蒸馏方法无法充分利用学生模型自身的优势,导致性能瓶颈。
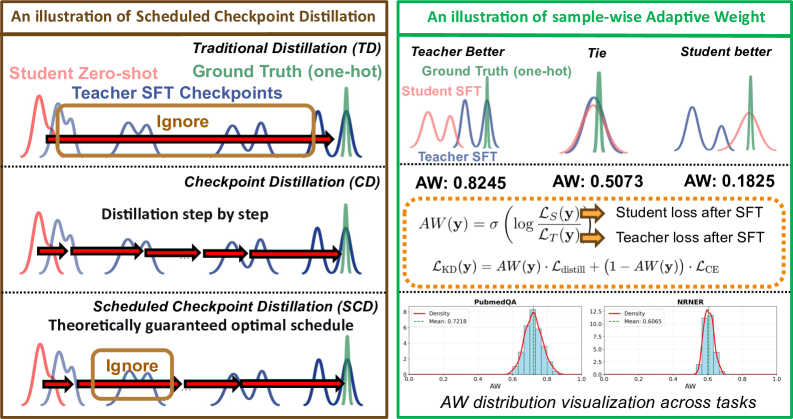
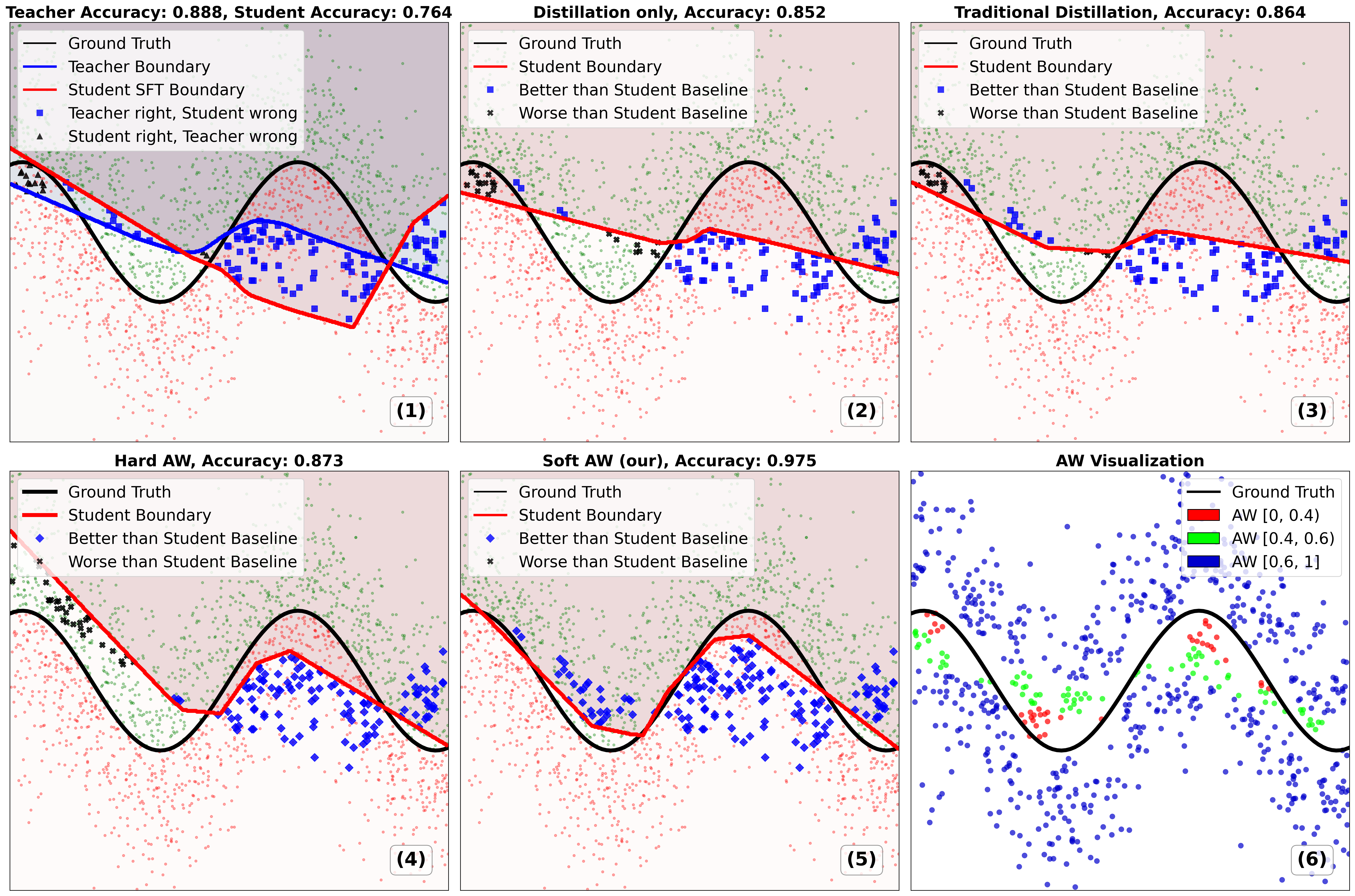
核心思路:论文的核心思路是基于一个理论洞见:学生模型可以在其擅长的子域(Student-Favored Subdomain, SFS)上超越教师模型,只要其在SFS上的优势能够弥补在教师擅长的子域(Teacher-Favored Subdomain, TFS)上的不足。因此,需要同时提升学生模型在TFS上的能力,并保留其在SFS上的优势。
技术框架:整体框架包含两个主要组成部分:Scheduled Checkpoint Distillation (SCD) 和 Sample-wise Adaptive Weighting (AW)。SCD通过模仿教师模型的训练过程,减小学生模型在TFS上的差距。AW机制则根据样本的特点,自适应地调整损失函数中不同样本的权重,从而保留学生模型在SFS上的优势。
关键创新:论文的关键创新在于提出了SCD和AW相结合的蒸馏策略,并基于SFS和TFS的理论分析,为蒸馏过程提供了指导。与传统蒸馏方法相比,SCD更加关注学生模型和教师模型在不同子域上的差异,并针对性地进行优化。
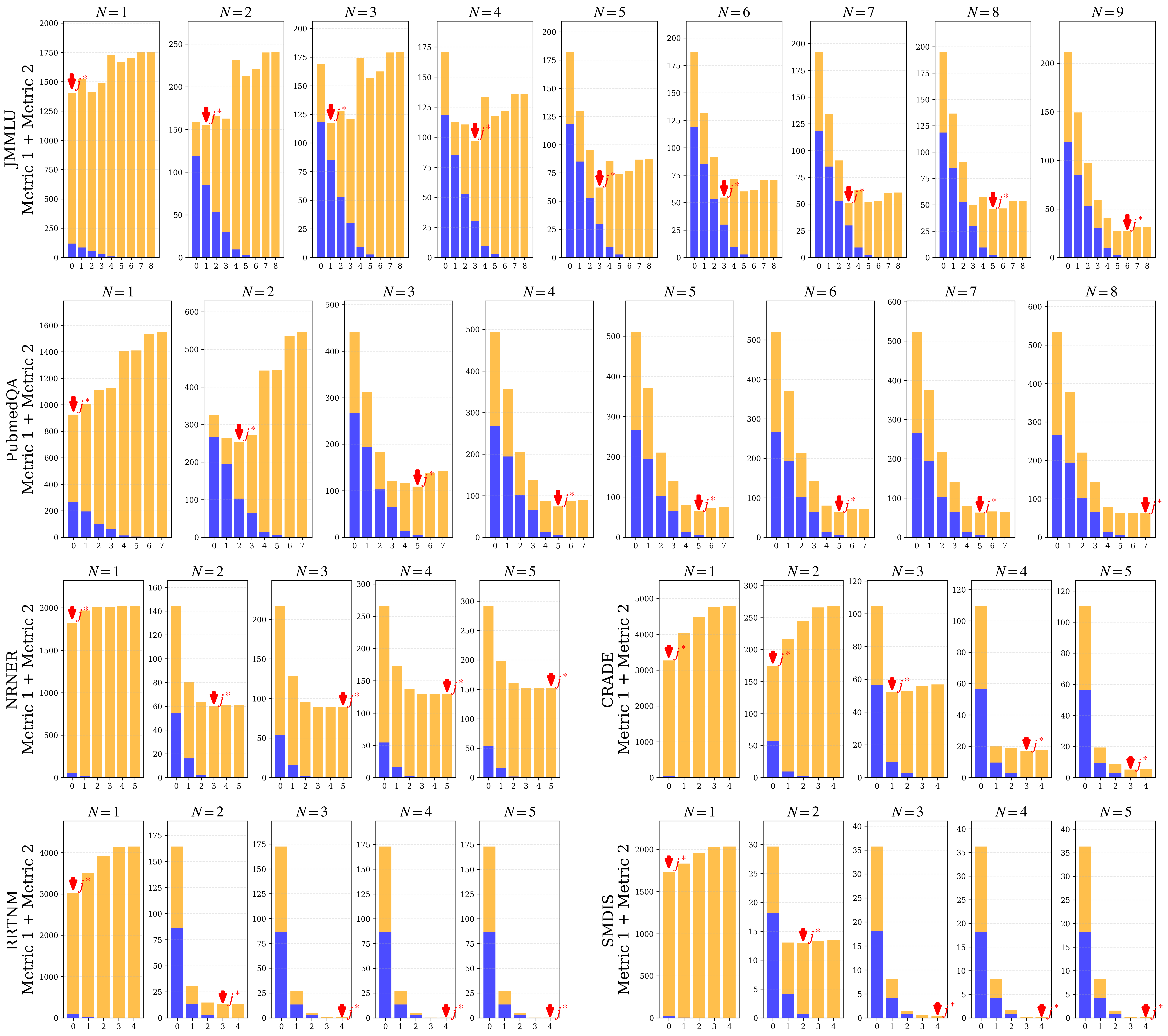
关键设计:SCD的关键设计在于选择合适的教师模型checkpoint。论文通过实验确定了在SFT过程中,教师模型在不同阶段的checkpoint对学生模型的影响。AW机制的关键设计在于如何定义和计算样本的权重。论文采用了一种基于模型预测置信度的自适应加权方法,使得学生模型更加关注其擅长的样本。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SCD方法在QA、NER和文本分类等多个领域任务上,均显著优于现有的蒸馏方法。在某些任务上,学生模型的性能甚至超过了其微调后的教师模型。例如,在特定数据集上,学生模型相比于教师模型,F1值提升了超过2个百分点。
🎯 应用场景
该研究成果可应用于各种领域特定的大型语言模型蒸馏任务,例如金融、医疗、法律等。通过蒸馏,可以将大型模型压缩成更小、更高效的模型,从而降低部署成本,提高推理速度,并能够在资源受限的设备上运行。这对于推动LLM在各行业的应用具有重要意义。
📄 摘要(原文)
Large language models (LLMs) are challenging to deploy for domain-specific tasks due to their massive scale. While distilling a fine-tuned LLM into a smaller student model is a promising alternative, the capacity gap between teacher and student often leads to suboptimal performance. This raises a key question: when and how can a student model match or even surpass its teacher on domain-specific tasks? In this work, we propose a novel theoretical insight: a student can outperform its teacher if its advantage on a Student-Favored Subdomain (SFS) outweighs its deficit on the Teacher-Favored Subdomain (TFS). Guided by this insight, we propose Scheduled Checkpoint Distillation (SCD), which reduces the TFS deficit by emulating the teacher's convergence process during supervised fine-tuning (SFT) on the domain task, and a sample-wise Adaptive Weighting (AW) mechanism to preserve student strengths on SFS. Experiments across diverse domain tasks--including QA, NER, and text classification in multiple languages--show that our method consistently outperforms existing distillation approaches, allowing the student model to match or even exceed the performance of its fine-tuned teacher.