State of AI: An Empirical 100 Trillion Token Study with OpenRouter
作者: Malika Aubakirova, Alex Atallah, Chris Clark, Justin Summerville, Anjney Midha
分类: cs.AI
发布日期: 2026-01-15
备注: 36 pages
💡 一句话要点
基于100万亿token的实证研究揭示LLM的实际应用模式与用户行为
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM应用 用户行为分析 开源模型 代理推理 OpenRouter 实证研究
📋 核心要点
- 现有研究对LLM在实际应用中的使用模式理解不足,缺乏大规模真实数据的分析。
- 本文利用OpenRouter平台的海量数据,深入分析LLM在不同任务和用户群体中的实际应用情况。
- 研究揭示了开源模型、特定应用场景的流行趋势,并发现了用户参与度随时间变化的“灰姑娘玻璃鞋”效应。
📝 摘要(中文)
本文利用OpenRouter平台,分析超过100万亿token的真实世界LLM交互数据,涵盖不同任务、地域和时间。研究揭示了开源模型的广泛采用、创造性角色扮演和代码辅助的突出流行,以及代理推理的兴起。此外,保留分析识别出早期用户群体,他们的参与度远高于后来的群体,作者称之为“灰姑娘玻璃鞋”效应。这些发现表明,开发者和终端用户与LLM的互动方式是复杂且多方面的。本文讨论了对模型构建者、AI开发者和基础设施提供商的影响,并概述了数据驱动的用法理解如何为LLM系统的更好设计和部署提供信息。
🔬 方法详解
问题定义:现有研究缺乏对大型语言模型(LLM)在真实世界中应用情况的深入理解,尤其是在模型推理能力增强后,开发者和用户如何使用这些模型,以及哪些应用场景更受欢迎等问题尚不明确。现有的研究方法往往依赖于小规模数据集或特定任务的分析,难以全面反映LLM的实际应用模式。
核心思路:本文的核心思路是通过分析OpenRouter平台上的大规模LLM交互数据,来揭示LLM在不同任务、地域和时间维度上的实际使用情况。OpenRouter作为一个连接多种LLM的AI推理平台,提供了丰富且多样化的数据来源,可以更全面地反映LLM的真实应用场景和用户行为。
技术框架:本文的技术框架主要包括以下几个阶段:1) 数据收集:从OpenRouter平台收集超过100万亿token的LLM交互数据。2) 数据清洗与预处理:对收集到的数据进行清洗和预处理,包括去除噪声数据、标准化文本格式等。3) 任务分类与场景识别:根据用户输入和模型输出,对LLM交互数据进行任务分类和场景识别,例如创造性角色扮演、代码辅助、代理推理等。4) 用户行为分析:分析不同用户群体的使用模式和参与度,识别早期用户群体和“灰姑娘玻璃鞋”效应。5) 统计分析与可视化:对分析结果进行统计分析和可视化,揭示LLM的实际应用趋势和用户行为特征。
关键创新:本文的关键创新在于:1) 利用OpenRouter平台的大规模真实数据,对LLM的实际应用情况进行了全面而深入的分析。2) 揭示了开源模型、特定应用场景(如创造性角色扮演和代码辅助)的流行趋势,这些趋势可能与之前的假设不同。3) 发现了用户参与度随时间变化的“灰姑娘玻璃鞋”效应,为理解用户行为和模型长期发展提供了新的视角。
关键设计:本文的关键设计包括:1) 任务分类方法:设计了有效的任务分类方法,能够准确识别LLM交互数据的应用场景。2) 用户行为分析指标:定义了合适的指标来衡量用户参与度和留存率,例如token使用量、会话时长等。3) “灰姑娘玻璃鞋”效应的识别方法:通过分析不同用户群体的参与度随时间的变化,识别出早期用户群体和“灰姑娘玻璃鞋”效应。
🖼️ 关键图片
📊 实验亮点
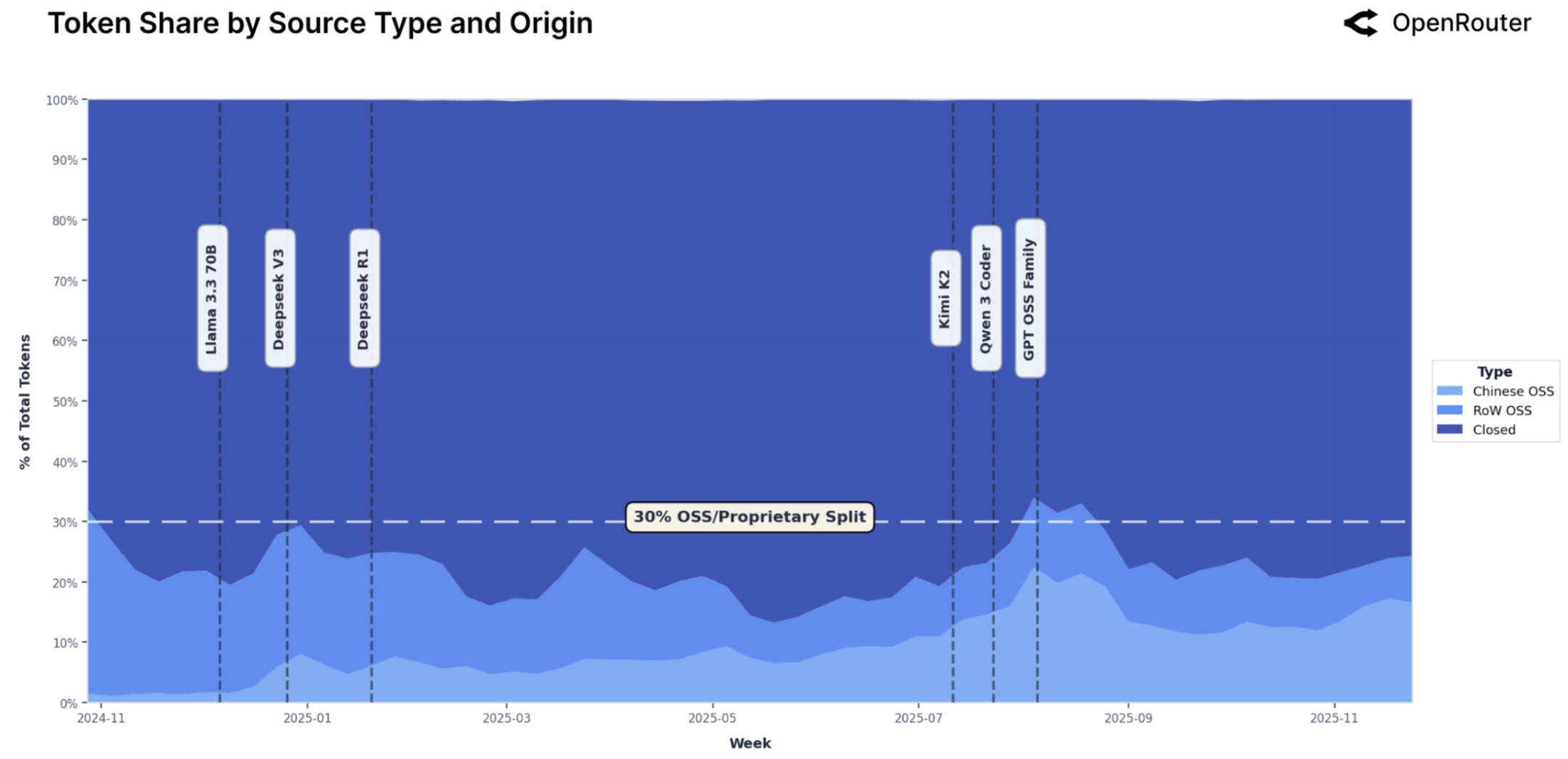
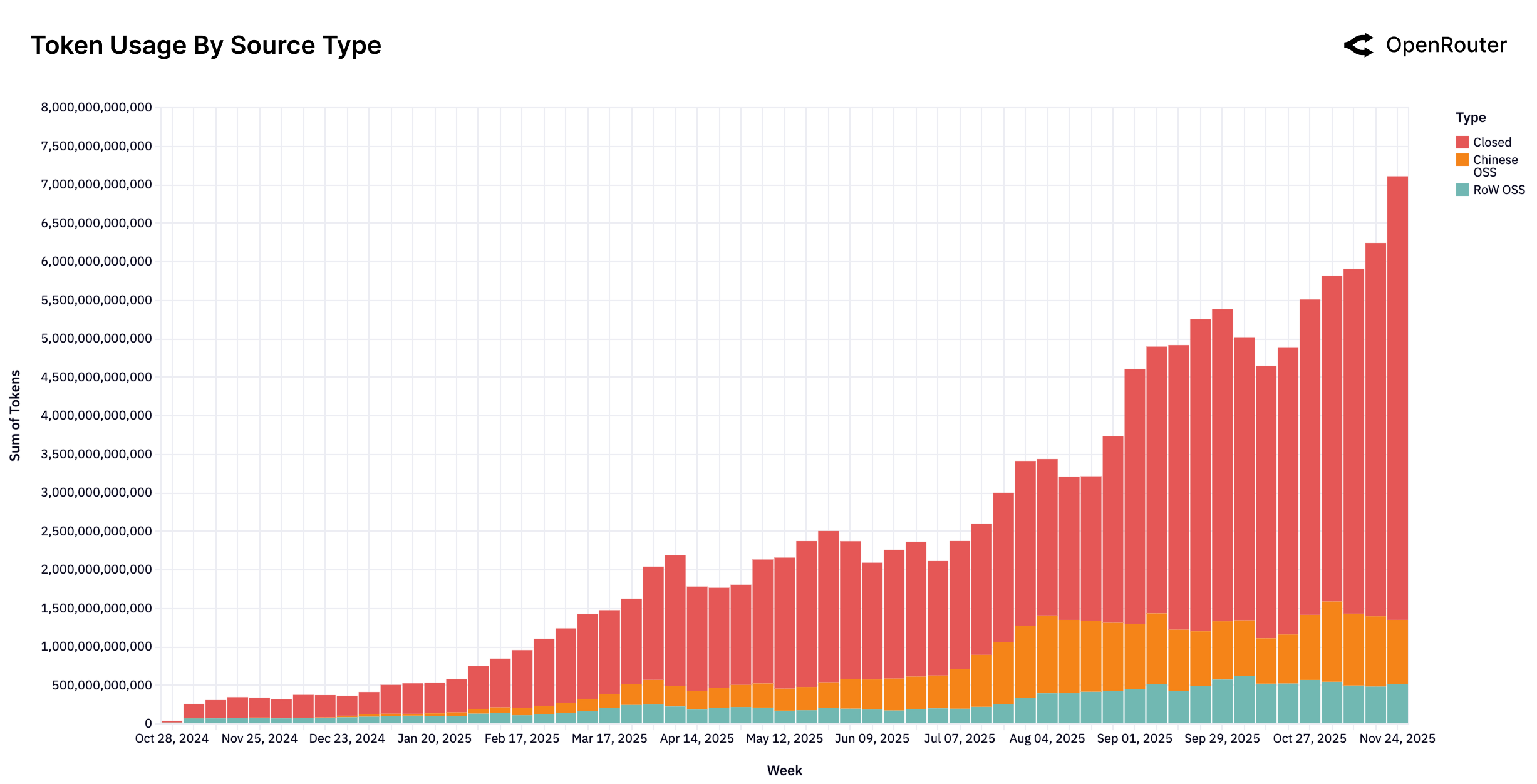
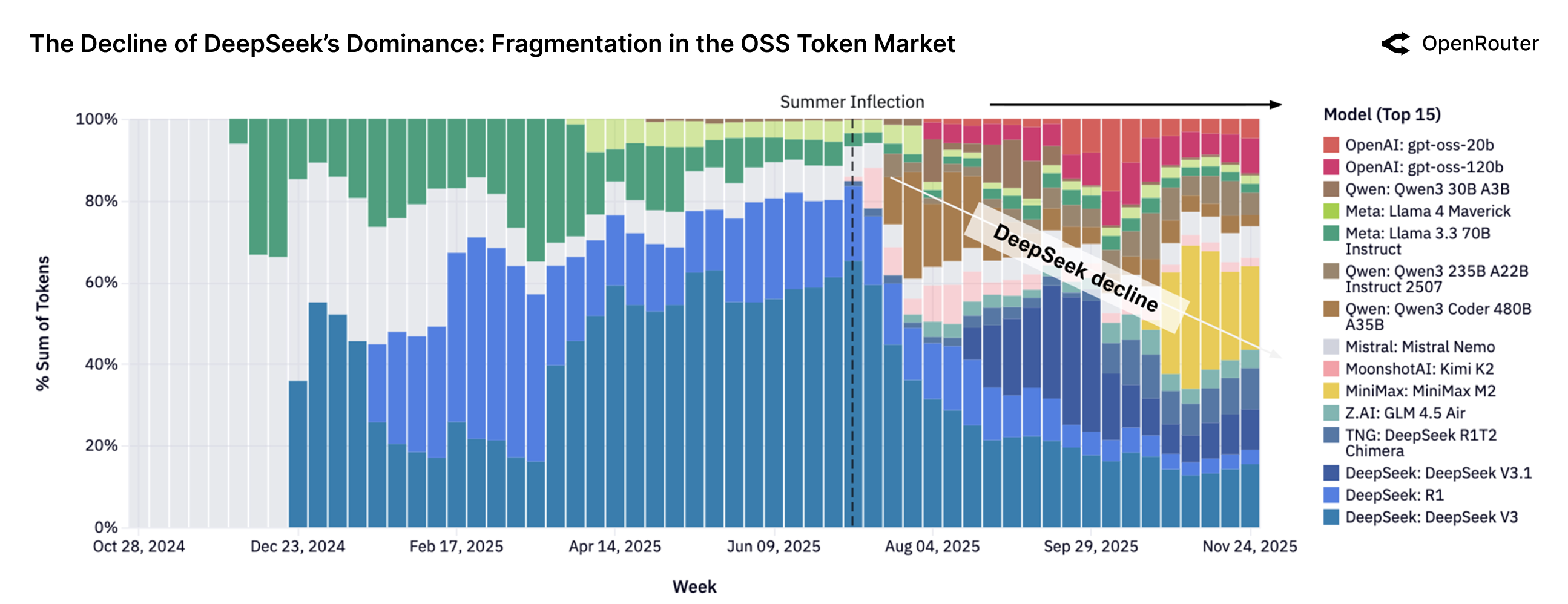
研究发现开源模型的使用量显著增长,表明开源生态在LLM领域的重要性日益提升。创造性角色扮演和代码辅助成为LLM的主要应用场景,颠覆了以往认为生产力工具占据主导地位的认知。早期用户群体表现出极高的留存率,验证了“灰姑娘玻璃鞋”效应,为用户增长策略提供了新的思路。
🎯 应用场景
该研究成果可应用于LLM模型的设计与优化、AI应用的开发与推广、以及AI基础设施的建设与改进。模型构建者可以根据实际应用场景调整模型特性,开发者可以针对用户偏好开发更受欢迎的应用,基础设施提供商可以优化资源分配以满足用户需求。研究结果有助于推动LLM技术在更广泛领域的应用。
📄 摘要(原文)
The past year has marked a turning point in the evolution and real-world use of large language models (LLMs). With the release of the first widely adopted reasoning model, o1, on December 5th, 2024, the field shifted from single-pass pattern generation to multi-step deliberation inference, accelerating deployment, experimentation, and new classes of applications. As this shift unfolded at a rapid pace, our empirical understanding of how these models have actually been used in practice has lagged behind. In this work, we leverage the OpenRouter platform, which is an AI inference provider across a wide variety of LLMs, to analyze over 100 trillion tokens of real-world LLM interactions across tasks, geographies, and time. In our empirical study, we observe substantial adoption of open-weight models, the outsized popularity of creative roleplay (beyond just the productivity tasks many assume dominate) and coding assistance categories, plus the rise of agentic inference. Furthermore, our retention analysis identifies foundational cohorts: early users whose engagement persists far longer than later cohorts. We term this phenomenon the Cinderella "Glass Slipper" effect. These findings underscore that the way developers and end-users engage with LLMs "in the wild" is complex and multifaceted. We discuss implications for model builders, AI developers, and infrastructure providers, and outline how a data-driven understanding of usage can inform better design and deployment of LLM systems.