SPRInG: Continual LLM Personalization via Selective Parametric Adaptation and Retrieval-Interpolated Generation
作者: Seoyeon Kim, Jaehyung Kim
分类: cs.AI, cs.CL
发布日期: 2026-01-15
备注: under review, 23 pages
💡 一句话要点
SPRInG:通过选择性参数适配与检索插值生成实现LLM的持续个性化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 个性化 大型语言模型 参数适配 检索增强生成
📋 核心要点
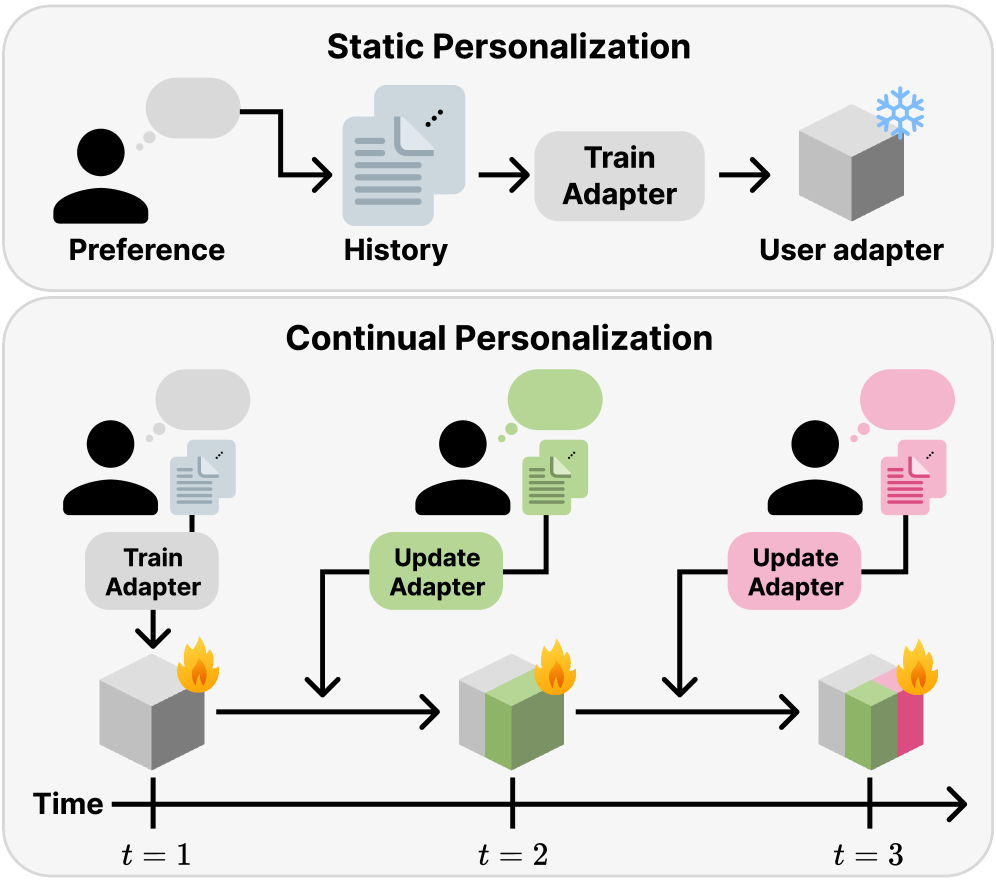
- 现有LLM个性化方法难以适应用户偏好随时间动态变化的问题,容易发生灾难性遗忘。
- SPRInG通过漂移驱动的选择性参数适配和检索插值生成,实现LLM的持续个性化。
- 实验表明,SPRInG在长文本个性化生成任务上优于现有基线,验证了其有效性。
📝 摘要(中文)
大型语言模型的个性化通常依赖于静态检索或一次性适配,这假设用户偏好随时间保持不变。然而,现实世界的交互是动态的,用户兴趣不断演变,这对模型适应偏好漂移提出了挑战,同时避免灾难性遗忘。标准的持续学习方法通常在此背景下表现不佳,因为它们不加区分地在嘈杂的交互流上更新,无法区分真正的偏好变化与瞬时上下文。为了解决这个问题,我们引入了SPRInG,这是一个新颖的半参数框架,专为有效的持续个性化而设计。在训练期间,SPRInG采用漂移驱动的选择性适配,它利用基于似然的评分函数来识别高新颖性的交互。这使得模型能够选择性地更新用户特定的适配器以响应漂移信号,同时将难以学习的残差保存在重放缓冲区中。在推理期间,我们应用严格的相关性门控,并通过logit插值将参数化知识与检索到的历史融合。在长文本个性化生成基准上的实验表明,SPRInG优于现有的基线,验证了其在真实世界持续个性化中的鲁棒性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在持续个性化场景下的偏好漂移问题。现有方法,如静态检索或一次性适配,无法有效应对用户兴趣随时间演变的情况,容易导致灾难性遗忘。标准的持续学习方法又无法区分真正的偏好变化与噪声交互,导致模型更新不稳定。
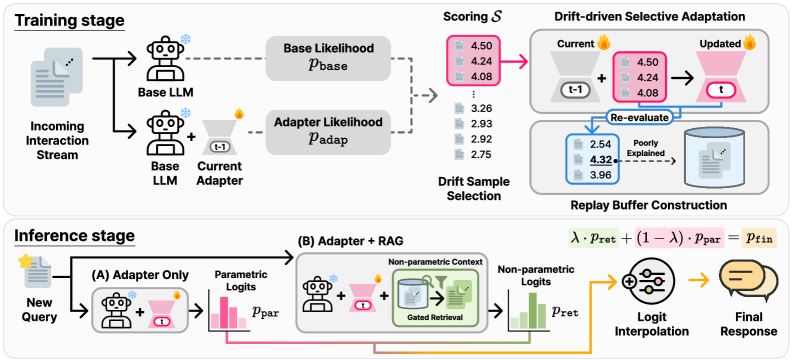
核心思路:SPRInG的核心思路是结合参数化适配和非参数化检索,并引入选择性更新机制。通过选择性地更新用户特定的适配器来适应偏好漂移,同时利用重放缓冲区保存历史信息,避免灾难性遗忘。在推理阶段,通过相关性门控和logit插值,融合参数化知识和检索到的历史信息,提高生成质量。
技术框架:SPRInG框架包含训练和推理两个阶段。在训练阶段,首先使用基于似然的评分函数识别高新颖性的交互,然后选择性地更新用户特定的适配器。同时,将难以学习的残差保存在重放缓冲区中。在推理阶段,首先应用严格的相关性门控,然后通过logit插值将参数化知识与检索到的历史融合。
关键创新:SPRInG的关键创新在于漂移驱动的选择性适配机制。通过基于似然的评分函数,模型能够自动识别高新颖性的交互,并选择性地更新用户特定的适配器。这种选择性更新机制可以有效地适应偏好漂移,同时避免在噪声交互上进行不必要的更新。
关键设计:SPRInG的关键设计包括:1) 基于似然的评分函数,用于识别高新颖性的交互;2) 用户特定的适配器,用于参数化地学习用户偏好;3) 重放缓冲区,用于保存历史信息,避免灾难性遗忘;4) 相关性门控,用于过滤不相关的历史信息;5) Logit插值,用于融合参数化知识和检索到的历史信息。具体的损失函数和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
SPRInG在长文本个性化生成基准上进行了实验,结果表明SPRInG显著优于现有的基线方法。具体而言,SPRInG在多个指标上取得了明显的提升,验证了其在真实世界持续个性化中的鲁棒性和有效性。论文中提供了详细的实验数据和对比分析。
🎯 应用场景
SPRInG可应用于各种需要持续个性化的场景,例如个性化推荐系统、对话系统、内容生成等。通过不断学习用户的新偏好,SPRInG可以提供更符合用户需求的个性化服务,提高用户满意度和参与度。该研究对于提升LLM在动态环境下的适应能力具有重要意义。
📄 摘要(原文)
Personalizing Large Language Models typically relies on static retrieval or one-time adaptation, assuming user preferences remain invariant over time. However, real-world interactions are dynamic, where user interests continuously evolve, posing a challenge for models to adapt to preference drift without catastrophic forgetting. Standard continual learning approaches often struggle in this context, as they indiscriminately update on noisy interaction streams, failing to distinguish genuine preference shifts from transient contexts. To address this, we introduce SPRInG, a novel semi-parametric framework designed for effective continual personalization. During training, SPRInG employs drift-driven selective adaptation, which utilizes a likelihood-based scoring function to identify high-novelty interactions. This allows the model to selectively update the user-specific adapter on drift signals while preserving hard-to-learn residuals in a replay buffer. During inference, we apply strict relevance gating and fuse parametric knowledge with retrieved history via logit interpolation. Experiments on the long-form personalized generation benchmark demonstrate that SPRInG outperforms existing baselines, validating its robustness for real-world continual personalization.