Chinese Labor Law Large Language Model Benchmark
作者: Zixun Lan, Maochun Xu, Yifan Ren, Rui Wu, Jianghui Zhou, Xueyang Cheng, Jianan Ding Ding, Xinheng Wang, Mingmin Chi, Fei Ma
分类: cs.AI
发布日期: 2026-01-15
💡 一句话要点
提出 LabourLawLLM:针对中国劳动法的专业大语言模型及评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 中国劳动法 领域特定模型 法律人工智能 评测基准
📋 核心要点
- 通用大语言模型在劳动法等专业法律领域面临知识精度、复杂推理和上下文理解的挑战。
- 论文提出LabourLawLLM,一个针对中国劳动法定制的法律大语言模型,并构建了相应的评测基准LabourLawBench。
- 实验结果表明,LabourLawLLM在各项劳动法任务中显著优于通用模型和现有的法律专用模型。
📝 摘要(中文)
大语言模型(LLMs)的最新进展推动了特定领域应用的发展,尤其是在法律领域。然而,GPT-4等通用模型在需要精确法律知识、复杂推理和上下文敏感性的专业子领域中表现不佳。为了解决这些局限性,我们提出了LabourLawLLM,一个专门为中国劳动法定制的法律大语言模型。我们还引入了LabourLawBench,一个全面的基准,涵盖了各种劳动法任务,包括法律条文引用、基于知识的问答、案例分类、赔偿计算、命名实体识别和法律案例分析。我们的评估框架结合了客观指标(例如,ROUGE-L、准确率、F1和soft-F1)和基于GPT-4评分的主观评估。实验表明,LabourLawLLM在各类任务中始终优于通用和现有的法律专用LLM。除了劳动法,我们的方法为在其他法律子领域构建专业LLM提供了一种可扩展的方法,从而提高了法律AI应用的准确性、可靠性和社会价值。
🔬 方法详解
问题定义:现有通用大语言模型(如GPT-4)在处理中国劳动法等专业法律领域的任务时,由于缺乏特定领域的知识和推理能力,表现不佳。这些任务包括法律条文引用、知识问答、案例分类、赔偿计算、命名实体识别和法律案例分析等。现有方法难以满足对法律知识精度、复杂推理和上下文敏感性的要求。
核心思路:论文的核心思路是构建一个专门针对中国劳动法的领域特定大语言模型LabourLawLLM,并通过高质量的劳动法数据进行训练和微调,使其具备更强的专业知识和推理能力。同时,构建全面的评测基准LabourLawBench,用于客观评估模型在各项劳动法任务上的表现。
技术框架:整体框架包含两个主要部分:一是LabourLawLLM的构建,二是LabourLawBench的构建和评估。LabourLawLLM的构建可能涉及预训练、微调等阶段,使用劳动法相关的文本数据进行训练。LabourLawBench包含多个劳动法任务,每个任务都有相应的评估指标。评估过程结合了客观指标(如ROUGE-L、准确率、F1、soft-F1)和基于GPT-4评分的主观评估。
关键创新:关键创新在于构建了一个专门针对中国劳动法的领域特定大语言模型LabourLawLLM,并提出了一个全面的评测基准LabourLawBench。这种领域特定的方法能够显著提高模型在专业领域的表现,克服了通用模型在专业知识和推理方面的局限性。
关键设计:论文中未明确说明LabourLawLLM的具体网络结构、损失函数和训练参数等技术细节,这些属于实现层面的细节,可能涉及对现有大语言模型的微调或从头训练。LabourLawBench的关键设计在于任务的多样性和评估指标的全面性,既包括客观指标,也包括主观评估,从而更全面地评估模型的性能。
🖼️ 关键图片
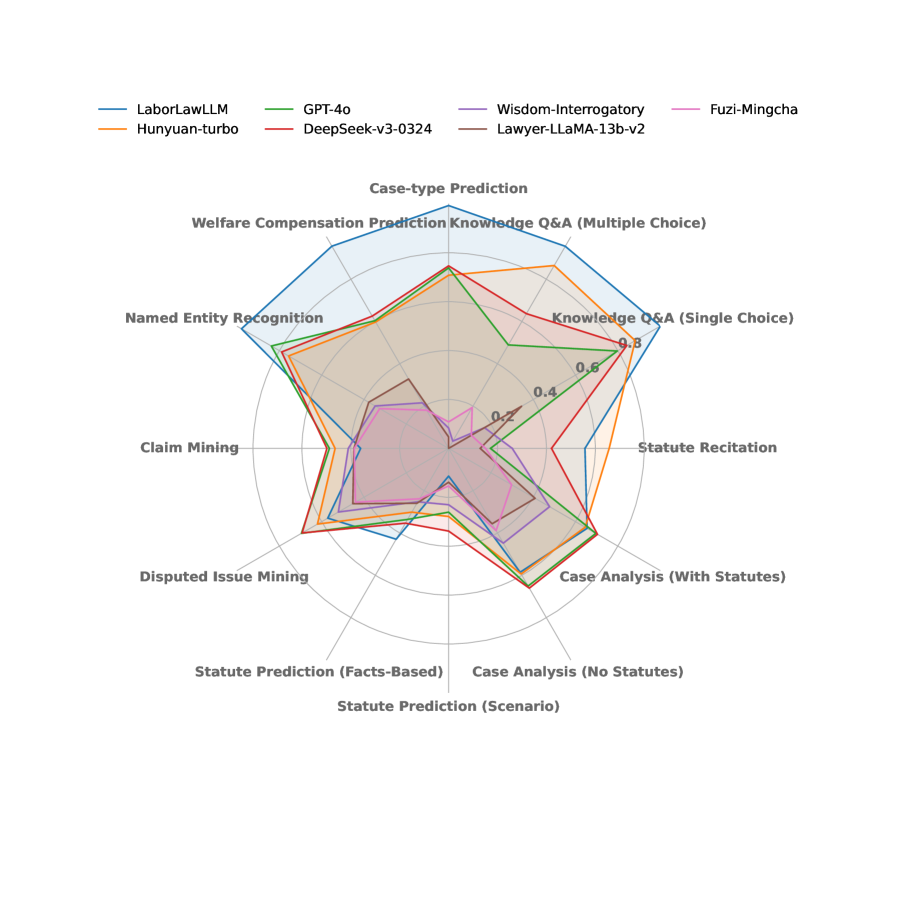
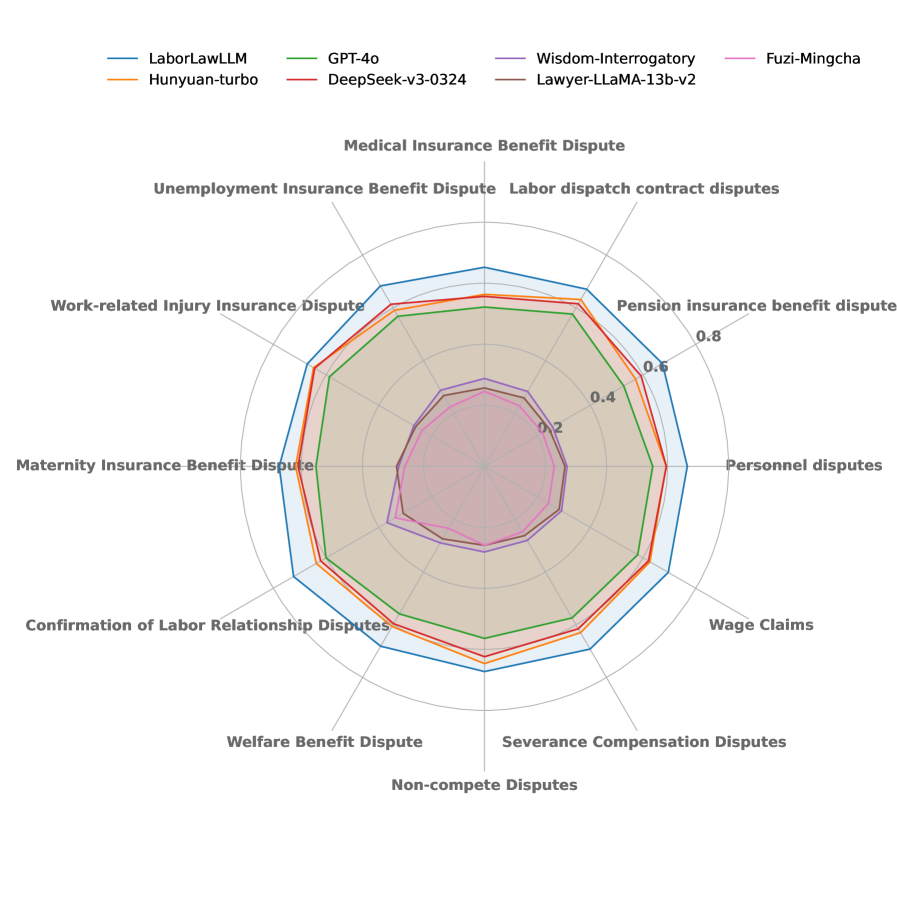
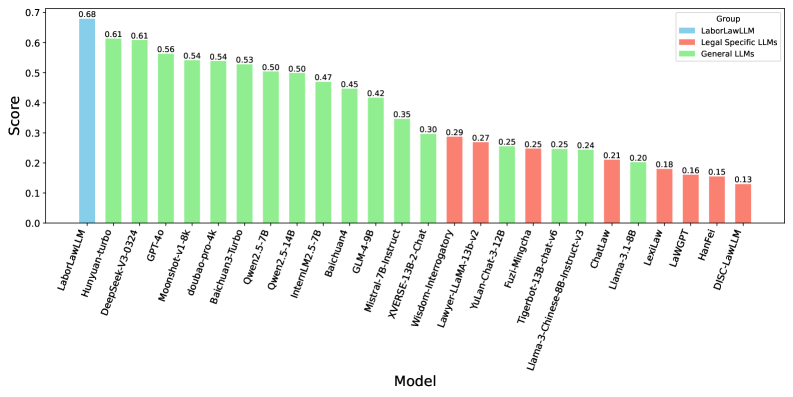
📊 实验亮点
实验结果表明,LabourLawLLM在LabourLawBench的各项任务中均优于通用大语言模型和现有的法律专用模型。具体的性能提升数据未知,但摘要强调了LabourLawLLM在各类任务中“始终优于”其他模型,表明其具有显著的优势。
🎯 应用场景
该研究成果可应用于智能法律咨询、法律文书生成、法律风险评估等领域,为律师、法务人员和普通民众提供更准确、高效的法律服务。未来,该方法可扩展到其他法律子领域,构建更多专业化的法律大语言模型,提升法律AI应用的社会价值。
📄 摘要(原文)
Recent advances in large language models (LLMs) have led to substantial progress in domain-specific applications, particularly within the legal domain. However, general-purpose models such as GPT-4 often struggle with specialized subdomains that require precise legal knowledge, complex reasoning, and contextual sensitivity. To address these limitations, we present LabourLawLLM, a legal large language model tailored to Chinese labor law. We also introduce LabourLawBench, a comprehensive benchmark covering diverse labor-law tasks, including legal provision citation, knowledge-based question answering, case classification, compensation computation, named entity recognition, and legal case analysis. Our evaluation framework combines objective metrics (e.g., ROUGE-L, accuracy, F1, and soft-F1) with subjective assessment based on GPT-4 scoring. Experiments show that LabourLawLLM consistently outperforms general-purpose and existing legal-specific LLMs across task categories. Beyond labor law, our methodology provides a scalable approach for building specialized LLMs in other legal subfields, improving accuracy, reliability, and societal value of legal AI applications.