ShortCoder: Knowledge-Augmented Syntax Optimization for Token-Efficient Code Generation
作者: Sicong Liu, Yanxian Huang, Mingwei Liu, Jiachi Chen, Ensheng Shi, Yuchi Ma, Hongyu Zhang, Yin Zhang, Yanlin Wang
分类: cs.SE, cs.AI, cs.CL
发布日期: 2026-01-14
💡 一句话要点
ShortCoder:通过知识增强的语法优化实现高效代码生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 语法优化 知识增强 代码简化
📋 核心要点
- 大型语言模型在代码生成中面临效率瓶颈,每次生成token都需要完整推理,资源消耗大。
- ShortCoder通过知识注入,利用语法简化规则和混合数据合成,优化代码生成效率并保持语义。
- 实验表明,ShortCoder在HumanEval上优于现有方法,代码生成效率提升18.1%-37.8%。
📝 摘要(中文)
代码生成旨在将用户需求自动转换为可执行代码,从而显著减少手动开发工作并提高软件生产力。大型语言模型(LLM)的出现极大地推动了代码生成的发展,但其效率仍然受到某些固有架构约束的影响。每次token生成都需要完整的推理过程,需要持续将上下文信息保存在内存中,从而增加资源消耗。现有研究主要关注推理阶段的优化,如提示压缩和模型量化,而生成阶段仍未得到充分探索。为了应对这些挑战,我们提出了一个名为ShortCoder的知识注入框架,该框架优化了代码生成效率,同时保持了语义等价性和可读性。具体来说,我们引入了:(1)十条Python语法级别的简化规则,这些规则源于AST保持转换,实现了18.1%的token减少,而没有功能上的妥协;(2)一种混合数据合成管道,将基于规则的重写与LLM引导的细化相结合,生成了ShorterCodeBench,这是一个包含原始代码和简化代码的验证元组的语料库,具有语义一致性;(3)一种微调策略,将简洁意识注入到基础LLM中。大量的实验结果表明,ShortCoder在HumanEval上始终优于最先进的方法,与以前的方法相比,在确保代码生成性能的同时,生成效率提高了18.1%-37.8%。
🔬 方法详解
问题定义:现有代码生成方法,特别是基于大型语言模型的方法,在生成代码时效率较低,因为每个token的生成都需要进行完整的推理过程,导致资源消耗大。现有的优化方法主要集中在推理阶段,例如提示压缩和模型量化,而忽略了生成阶段的优化。因此,如何提高代码生成效率,同时保持代码的语义等价性和可读性,是一个亟待解决的问题。
核心思路:ShortCoder的核心思路是通过知识增强的语法优化,在代码生成过程中引入简洁性意识。具体来说,它利用一系列预定义的语法简化规则,将原始代码转换为更简洁但语义等价的代码。同时,通过混合数据合成管道,生成包含原始代码和简化代码的训练数据,并使用这些数据对大型语言模型进行微调,从而使模型能够生成更简洁的代码。
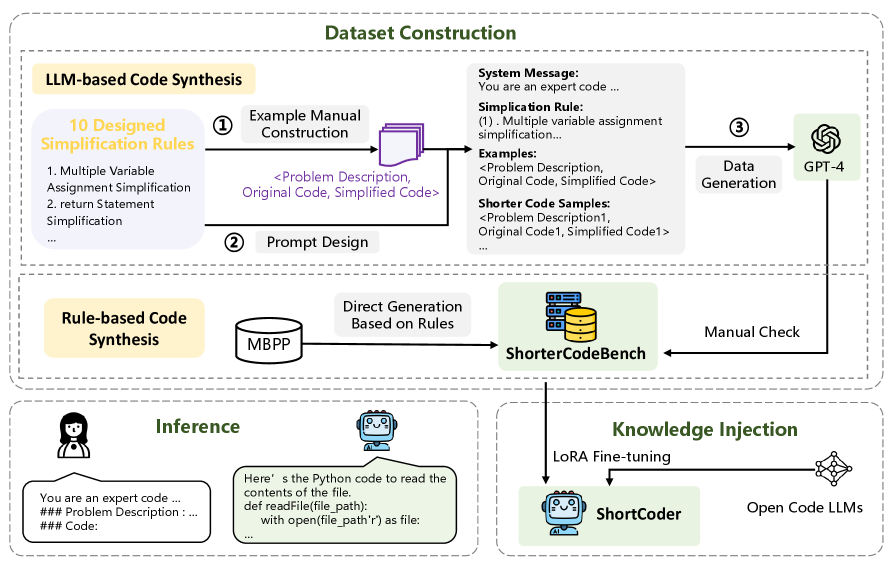
技术框架:ShortCoder框架主要包含三个模块:(1) 语法简化规则:定义了一系列Python语法级别的简化规则,这些规则基于AST保持转换,确保简化后的代码与原始代码在语义上等价。(2) 混合数据合成管道:该管道结合了基于规则的重写和LLM引导的细化,用于生成包含原始代码和简化代码的训练数据。首先,使用语法简化规则对原始代码进行重写,生成候选的简化代码。然后,使用LLM对候选代码进行评估和改进,确保其语义正确性和可读性。(3) 微调策略:使用生成的训练数据对大型语言模型进行微调,使模型能够学习到简洁代码的生成模式。
关键创新:ShortCoder的关键创新在于其知识增强的语法优化方法。与现有方法相比,ShortCoder不是直接优化推理过程,而是通过在生成阶段引入简洁性意识来提高代码生成效率。具体来说,它通过预定义的语法简化规则和混合数据合成管道,将简洁性知识注入到大型语言模型中,从而使模型能够生成更简洁的代码。
关键设计:(1) 语法简化规则:论文定义了10条Python语法级别的简化规则,例如将if condition: return True else: return False简化为return condition。(2) 混合数据合成管道:该管道使用LLM(例如GPT-3)对候选的简化代码进行评估和改进,确保其语义正确性和可读性。(3) 微调策略:使用生成的训练数据对CodeT5+模型进行微调,使用标准的交叉熵损失函数进行训练。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ShortCoder在HumanEval数据集上显著优于现有方法。例如,与CodeT5+相比,ShortCoder在pass@1指标上取得了18.1%的提升,在生成效率上提升了18.1%-37.8%。这些结果表明,ShortCoder能够有效地提高代码生成效率,同时保持代码的语义正确性。
🎯 应用场景
ShortCoder具有广泛的应用前景,可以应用于各种需要代码自动生成的场景,例如软件开发、自动化测试、代码补全等。通过提高代码生成效率,ShortCoder可以显著减少开发时间和成本,提高软件生产力。此外,ShortCoder生成的简洁代码也更易于阅读和维护,有助于提高代码质量。未来,ShortCoder可以进一步扩展到其他编程语言和代码生成任务中。
📄 摘要(原文)
Code generation tasks aim to automate the conversion of user requirements into executable code, significantly reducing manual development efforts and enhancing software productivity. The emergence of large language models (LLMs) has significantly advanced code generation, though their efficiency is still impacted by certain inherent architectural constraints. Each token generation necessitates a complete inference pass, requiring persistent retention of contextual information in memory and escalating resource consumption. While existing research prioritizes inference-phase optimizations such as prompt compression and model quantization, the generation phase remains underexplored. To tackle these challenges, we propose a knowledge-infused framework named ShortCoder, which optimizes code generation efficiency while preserving semantic equivalence and readability. In particular, we introduce: (1) ten syntax-level simplification rules for Python, derived from AST-preserving transformations, achieving 18.1% token reduction without functional compromise; (2) a hybrid data synthesis pipeline integrating rule-based rewriting with LLM-guided refinement, producing ShorterCodeBench, a corpus of validated tuples of original code and simplified code with semantic consistency; (3) a fine-tuning strategy that injects conciseness awareness into the base LLMs. Extensive experimental results demonstrate that ShortCoder consistently outperforms state-of-the-art methods on HumanEval, achieving an improvement of 18.1%-37.8% in generation efficiency over previous methods while ensuring the performance of code generation.