Collaborative Multi-Agent Test-Time Reinforcement Learning for Reasoning
作者: Zhiyuan Hu, Yunhai Hu, Juncheng Liu, Shuyue Stella Li, Yucheng Wang, Zhen Xu, See-Kiong Ng, Anh Tuan Luu, Xinxing Xu, Bryan Hooi, Cynthia Breazeal, Hae Won Park
分类: cs.AI, cs.CL
发布日期: 2026-01-14
备注: Work in Progress
💡 一句话要点
提出MATTRL,一种用于多智能体推理的测试时强化学习框架。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体系统 强化学习 测试时学习 文本经验 推理 信用分配 分布偏移
📋 核心要点
- 多智能体强化学习训练成本高昂且不稳定,难以适应环境变化,是当前研究面临的核心挑战。
- MATTRL通过在推理时注入结构化文本经验,构建多专家团队,实现更稳健的多智能体决策。
- 实验表明,MATTRL在医学、数学和教育等领域,显著提升了多智能体系统的准确性,平均提升达3.67%。
📝 摘要(中文)
多智能体系统已发展成为许多应用中由大型语言模型驱动的实用协作工具,通过多样性和交叉检查获得稳健性。然而,多智能体强化学习(MARL)训练资源密集且不稳定:协同适应的队友会导致非平稳性,并且奖励通常是稀疏且高方差的。因此,我们引入了 extbf{多智能体测试时强化学习(MATTRL)},该框架在推理时将结构化的文本经验注入到多智能体审议中。MATTRL形成一个由专家组成的多专家团队,用于多轮讨论,检索和整合测试时经验,并达成共识以进行最终决策。我们还研究了信用分配,以构建turn-level经验池,然后将其重新注入到对话中。在医学、数学和教育等具有挑战性的基准测试中,MATTRL的准确率比多智能体基线平均提高了3.67%,比可比的单智能体基线平均提高了8.67%。消融研究检查了不同的信用分配方案,并详细比较了它们如何影响训练结果。MATTRL提供了一种稳定、有效且高效的路径,无需调整即可实现对分布偏移具有鲁棒性的多智能体推理。
🔬 方法详解
问题定义:现有MARL方法在训练阶段面临资源消耗大、训练不稳定等问题,尤其是在队友协同适应时,环境的非平稳性以及奖励的稀疏性和高方差使得训练更加困难。此外,已训练好的MARL模型在面对分布偏移时,泛化能力较弱。
核心思路:MATTRL的核心在于利用测试时强化学习,避免了耗时的训练过程。通过在推理阶段引入结构化的文本经验,指导多智能体进行审议和决策。这种方法允许智能体在实际应用中学习和适应,从而提高其鲁棒性和泛化能力。
技术框架:MATTRL框架包含以下几个主要模块:1) 多专家团队构建:形成一个由多个专业智能体组成的团队,每个智能体负责不同的方面。2) 经验检索与整合:在测试时,检索相关的文本经验,并将其整合到多智能体的讨论中。3) 多轮讨论与共识:智能体之间进行多轮讨论,最终达成共识,做出最终决策。4) 信用分配与经验重注入:对每一轮对话进行信用分配,构建turn-level经验池,并将这些经验重新注入到对话中,以进一步提升性能。
关键创新:MATTRL的关键创新在于将测试时强化学习应用于多智能体系统,并结合了结构化的文本经验。这使得智能体能够在推理阶段持续学习和适应,从而提高了其对分布偏移的鲁棒性。与传统的MARL方法相比,MATTRL避免了耗时的训练过程,并且能够更好地应对实际应用中的变化。
关键设计:论文研究了不同的信用分配方案,并比较了它们对训练结果的影响。具体的信用分配方法未知,但强调了其对性能的重要性。此外,论文还设计了一种机制,用于将turn-level经验重新注入到对话中,以进一步提升性能。具体的网络结构和损失函数等技术细节未知。
🖼️ 关键图片
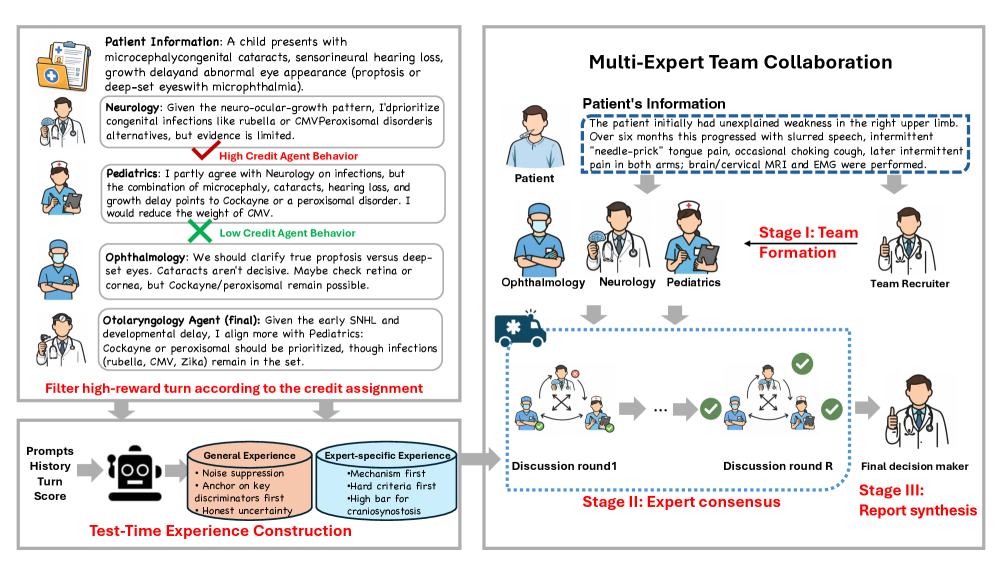

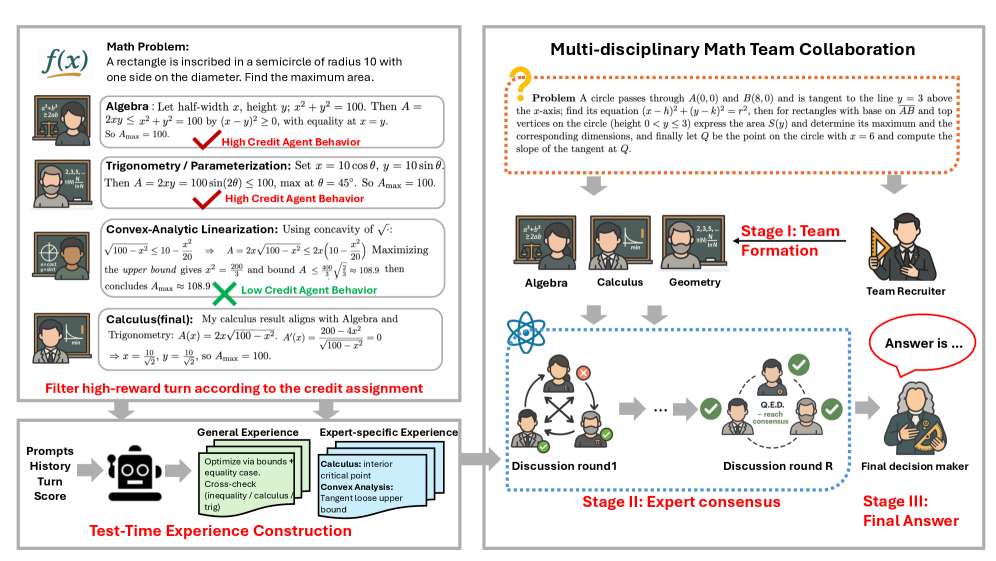
📊 实验亮点
实验结果表明,MATTRL在医学、数学和教育等多个具有挑战性的基准测试中,显著优于传统的多智能体和单智能体基线。具体而言,MATTRL的准确率比多智能体基线平均提高了3.67%,比可比的单智能体基线平均提高了8.67%。这些结果验证了MATTRL的有效性和优越性。
🎯 应用场景
MATTRL具有广泛的应用前景,例如在医疗诊断、教育辅导、金融决策等领域,可以构建更智能、更可靠的多智能体协作系统。通过利用领域知识和实时经验,MATTRL能够提升决策的准确性和效率,为用户提供更好的服务。
📄 摘要(原文)
Multi-agent systems have evolved into practical LLM-driven collaborators for many applications, gaining robustness from diversity and cross-checking. However, multi-agent RL (MARL) training is resource-intensive and unstable: co-adapting teammates induce non-stationarity, and rewards are often sparse and high-variance. Therefore, we introduce \textbf{Multi-Agent Test-Time Reinforcement Learning (MATTRL)}, a framework that injects structured textual experience into multi-agent deliberation at inference time. MATTRL forms a multi-expert team of specialists for multi-turn discussions, retrieves and integrates test-time experiences, and reaches consensus for final decision-making. We also study credit assignment for constructing a turn-level experience pool, then reinjecting it into the dialogue. Across challenging benchmarks in medicine, math, and education, MATTRL improves accuracy by an average of 3.67\% over a multi-agent baseline, and by 8.67\% over comparable single-agent baselines. Ablation studies examine different credit-assignment schemes and provide a detailed comparison of how they affect training outcomes. MATTRL offers a stable, effective and efficient path to distribution-shift-robust multi-agent reasoning without tuning.