Omni-R1: Towards the Unified Generative Paradigm for Multimodal Reasoning
作者: Dongjie Cheng, Yongqi Li, Zhixin Ma, Hongru Cai, Yupeng Hu, Wenjie Wang, Liqiang Nie, Wenjie Li
分类: cs.AI
发布日期: 2026-01-14
💡 一句话要点
Omni-R1:提出统一生成式多模态推理框架,通过生成中间图像实现多任务泛化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 生成式模型 统一框架 图像生成 强化学习 自监督学习 大型语言模型
📋 核心要点
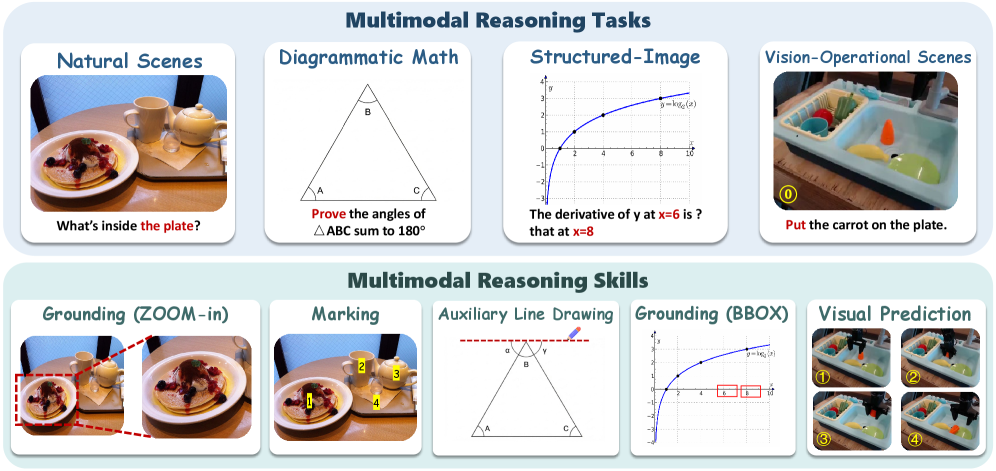
- 现有MLLM推理方法依赖于特定任务的推理模式,泛化能力受限,无法处理需要多样推理技巧的任务。
- Omni-R1通过生成中间图像来统一不同的多模态推理技能,实现跨任务的统一生成式多模态推理。
- Omni-R1-Zero无需多模态标注,仅通过文本推理数据引导可视化,性能可与Omni-R1媲美甚至超越。
📝 摘要(中文)
多模态大型语言模型(MLLM)在多模态推理方面取得了显著进展。早期方法侧重于纯文本推理。最近的研究将多模态信息融入推理步骤,但它们通常遵循单一的、特定于任务的推理模式,限制了其在各种多模态任务中的泛化能力。事实上,存在许多需要不同推理技能的多模态任务,例如放大特定区域或标记图像中的对象。为了解决这个问题,我们提出了统一生成式多模态推理,通过在推理过程中生成中间图像来统一不同的多模态推理技能。我们使用Omni-R1实例化了这个范例,Omni-R1是一个两阶段的SFT+RL框架,具有感知对齐损失和感知奖励,从而实现了功能性图像生成。此外,我们引入了Omni-R1-Zero,它通过从纯文本推理数据中引导逐步可视化,消除了对多模态注释的需求。实验结果表明,Omni-R1在各种多模态任务中实现了统一的生成式推理,而Omni-R1-Zero在平均水平上可以匹配甚至超过Omni-R1,这为生成式多模态推理提供了一个有希望的方向。
🔬 方法详解
问题定义:现有的大型多模态语言模型(MLLM)在多模态推理任务中表现出色,但通常针对特定任务设计推理模式,缺乏通用性。例如,针对图像局部区域推理、目标检测等任务,需要不同的推理步骤和方法。这种任务特定性限制了模型在面对复杂、多样的多模态任务时的泛化能力。
核心思路:论文的核心思路是提出一种统一的生成式多模态推理框架,通过在推理过程中生成中间图像,将不同的多模态推理技能统一起来。这种方法将复杂的推理过程分解为一系列图像生成步骤,使得模型能够逐步地、可视化地进行推理,从而提高模型的通用性和可解释性。
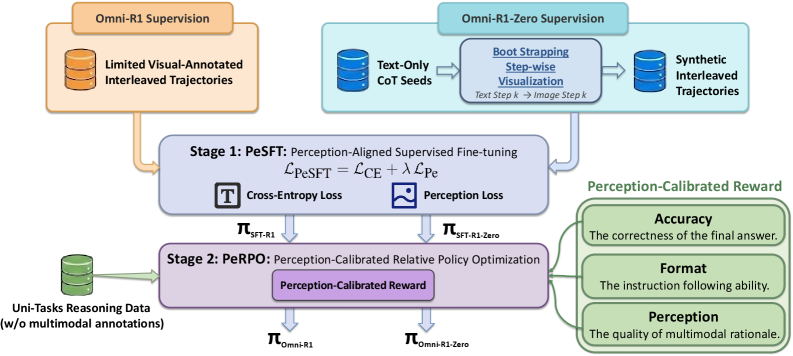
技术框架:Omni-R1框架包含两个主要阶段:监督微调(SFT)和强化学习(RL)。在SFT阶段,模型通过多模态数据进行训练,学习生成中间图像的能力。在RL阶段,模型通过感知奖励进行优化,进一步提高生成图像的质量和与任务的相关性。此外,Omni-R1-Zero通过从纯文本推理数据中引导逐步可视化,消除了对多模态注释的需求。
关键创新:该论文的关键创新在于提出了统一生成式多模态推理范式,通过生成中间图像来统一不同的多模态推理技能。此外,Omni-R1-Zero的提出,使得模型可以在没有多模态标注的情况下进行训练,降低了训练成本。与现有方法相比,该方法具有更强的通用性和可扩展性。
关键设计:Omni-R1的关键设计包括感知对齐损失和感知奖励。感知对齐损失用于约束生成的中间图像与输入图像之间的语义一致性。感知奖励用于鼓励模型生成与任务相关的、高质量的图像。此外,Omni-R1-Zero通过自举的方式,从纯文本推理数据中学习生成中间图像,避免了对多模态标注的依赖。具体的网络结构和参数设置在论文中有详细描述,但此处未提供详细信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Omni-R1在各种多模态任务中实现了统一的生成式推理。更重要的是,Omni-R1-Zero在平均水平上可以匹配甚至超过Omni-R1,这表明即使在没有多模态标注的情况下,模型也可以通过自监督学习获得良好的性能。这些结果验证了该方法的有效性和潜力。
🎯 应用场景
该研究成果可应用于各种需要多模态推理的场景,例如智能问答、视觉导航、机器人控制等。通过统一生成式推理,可以提高模型在复杂任务中的表现,并降低对特定任务数据的依赖。未来,该方法有望推动多模态人工智能的发展,实现更智能、更通用的AI系统。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) are making significant progress in multimodal reasoning. Early approaches focus on pure text-based reasoning. More recent studies have incorporated multimodal information into the reasoning steps; however, they often follow a single task-specific reasoning pattern, which limits their generalizability across various multimodal tasks. In fact, there are numerous multimodal tasks requiring diverse reasoning skills, such as zooming in on a specific region or marking an object within an image. To address this, we propose unified generative multimodal reasoning, which unifies diverse multimodal reasoning skills by generating intermediate images during the reasoning process. We instantiate this paradigm with Omni-R1, a two-stage SFT+RL framework featuring perception alignment loss and perception reward, thereby enabling functional image generation. Additionally, we introduce Omni-R1-Zero, which eliminates the need for multimodal annotations by bootstrapping step-wise visualizations from text-only reasoning data. Empirical results show that Omni-R1 achieves unified generative reasoning across a wide range of multimodal tasks, and Omni-R1-Zero can match or even surpass Omni-R1 on average, suggesting a promising direction for generative multimodal reasoning.