What Do LLM Agents Know About Their World? Task2Quiz: A Paradigm for Studying Environment Understanding
作者: Siyuan Liu, Hongbang Yuan, Xinze Li, Ziyue Zhu, Yixin Cao, Yu-Gang Jiang
分类: cs.AI
发布日期: 2026-01-14
💡 一句话要点
提出Task2Quiz评估范式,用于研究LLM Agent的环境理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 环境理解 评估范式 Task2Quiz 泛化能力
📋 核心要点
- 现有LLM Agent评估侧重任务成功率,忽略了对环境理解能力的评估,导致泛化能力不足。
- 提出Task-to-Quiz (T2Q) 范式,通过问答形式解耦任务执行与环境理解,实现更精准评估。
- 实验表明任务成功率与环境理解并非强相关,现有记忆机制未能有效提升Agent的环境认知。
📝 摘要(中文)
大型语言模型(LLM)Agent在复杂的决策和工具使用任务中表现出卓越的能力,但它们在不同环境中泛化的能力仍然是一个未被充分研究的问题。目前的评估范式主要依赖于衡量任务成功率的基于轨迹的指标,而未能评估Agent是否拥有一个扎根的、可转移的环境模型。为了解决这个差距,我们提出了Task-to-Quiz(T2Q),这是一种确定性的和自动化的评估范式,旨在将任务执行与世界状态理解分离。我们在T2QBench中实例化了这个范式,T2QBench包含30个环境和1,967个跨多个难度级别的、基于现实的问答对。我们广泛的实验表明,任务成功率通常不能很好地代表环境理解能力,并且当前的记忆机制不能有效地帮助Agent获得一个扎根的环境模型。这些发现将主动探索和细粒度的状态表示确定为主要瓶颈,为开发更具泛化能力的自主Agent提供了坚实的基础。
🔬 方法详解
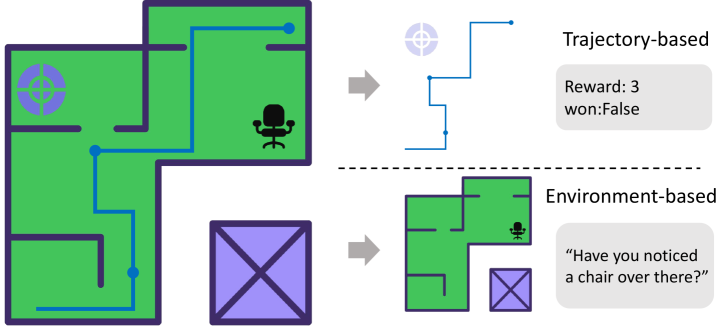
问题定义:现有LLM Agent的评估方法主要依赖于任务完成的轨迹和成功率,缺乏对Agent是否真正理解环境状态的有效评估。这种评估方式无法区分Agent是偶然成功还是真正理解了环境,导致Agent在面对新环境时泛化能力不足。现有方法的痛点在于无法有效衡量Agent对环境的grounded理解。
核心思路:论文的核心思路是将任务执行与环境理解解耦。通过设计一系列基于环境状态的问答题,直接评估Agent对环境的理解程度,而不再仅仅依赖于任务完成的成功率。这种方式可以更清晰地了解Agent是否真正掌握了环境的内在规律。
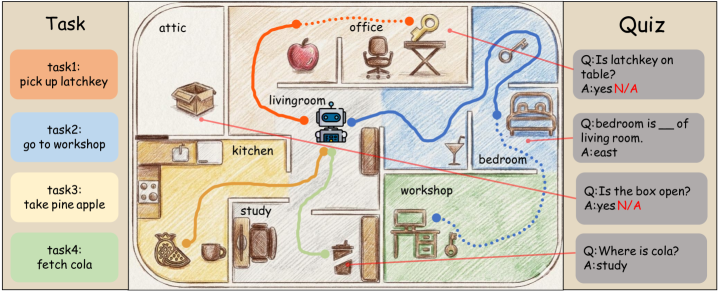
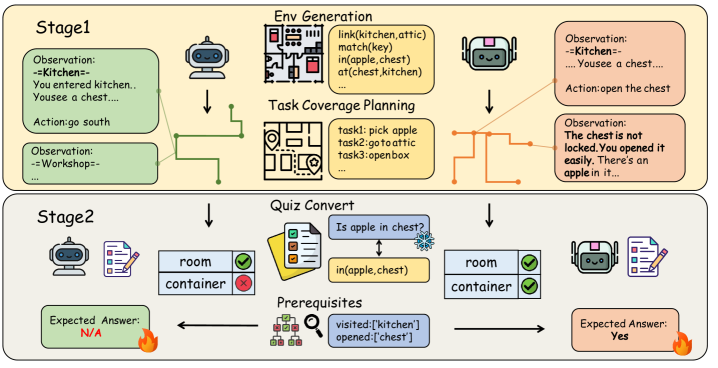
技术框架:T2Q范式包含以下几个主要组成部分:首先,构建包含多个环境的T2QBench数据集,每个环境都包含一系列基于环境状态的问答对。其次,Agent在给定环境下执行任务,并记录其行为轨迹。然后,根据Agent的行为轨迹和环境状态,向Agent提出相应的问答题。最后,根据Agent回答的准确率来评估其对环境的理解程度。整个流程是确定性的和自动化的,保证了评估的客观性和可重复性。
关键创新:T2Q范式的关键创新在于它提供了一种解耦任务执行与环境理解的评估方法。与传统的基于任务成功率的评估方法不同,T2Q直接评估Agent对环境状态的理解程度,从而更准确地反映Agent的泛化能力。此外,T2QBench数据集的构建也为研究LLM Agent的环境理解能力提供了benchmark。
关键设计:T2QBench数据集包含30个环境和1,967个问答对,涵盖了多个难度级别。问答对的设计需要保证与环境状态紧密相关,并且能够有效区分Agent是否真正理解了环境。论文中没有详细说明具体的参数设置、损失函数或网络结构,因为T2Q范式主要关注评估方法本身,而不是特定的Agent模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,任务成功率并不能很好地代表Agent对环境的理解程度。即使Agent能够成功完成任务,其对环境状态的理解程度可能仍然很低。此外,实验还发现,现有的记忆机制并不能有效地帮助Agent获得一个扎根的环境模型。这些发现表明,主动探索和细粒度的状态表示是提高LLM Agent环境理解能力的关键。
🎯 应用场景
该研究成果可应用于开发更智能、更具泛化能力的机器人和AI Agent。例如,在自动驾驶领域,可以利用T2Q范式评估自动驾驶系统对复杂交通环境的理解程度,从而提高其安全性和可靠性。此外,该方法还可以用于评估和改进虚拟助手、游戏AI等应用。
📄 摘要(原文)
Large language model (LLM) agents have demonstrated remarkable capabilities in complex decision-making and tool-use tasks, yet their ability to generalize across varying environments remains a under-examined concern. Current evaluation paradigms predominantly rely on trajectory-based metrics that measure task success, while failing to assess whether agents possess a grounded, transferable model of the environment. To address this gap, we propose Task-to-Quiz (T2Q), a deterministic and automated evaluation paradigm designed to decouple task execution from world-state understanding. We instantiate this paradigm in T2QBench, a suite comprising 30 environments and 1,967 grounded QA pairs across multiple difficulty levels. Our extensive experiments reveal that task success is often a poor proxy for environment understanding, and that current memory machanism can not effectively help agents acquire a grounded model of the environment. These findings identify proactive exploration and fine-grained state representation as primary bottlenecks, offering a robust foundation for developing more generalizable autonomous agents.