Population-Aligned Audio Reproduction With LLM-Based Equalizers
作者: Ioannis Stylianou, Jon Francombe, Pablo Martinez-Nuevo, Sven Ewan Shepstone, Zheng-Hua Tan
分类: cs.SD, cs.AI
发布日期: 2026-01-14
备注: 12 pages, 13 figures, 2 tables, IEEE JSTSP journal submission under first revision
💡 一句话要点
提出基于LLM的音频均衡器,通过自然语言控制实现个性化音效调整
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频均衡 大型语言模型 自然语言处理 个性化音频 参数高效微调
📋 核心要点
- 传统音频均衡需要手动调整以适应不同情境,过程繁琐且缺乏智能化。
- 利用大型语言模型,将自然语言指令转化为均衡器设置,实现对话式音频控制。
- 实验表明,该方法在分布对齐方面显著优于传统方法,更贴合用户个性化偏好。
📝 摘要(中文)
本文提出了一种基于大型语言模型(LLM)的音频均衡替代方案,该方案将自然语言文本提示映射到均衡设置,从而实现声音系统控制的对话式方法。通过利用从受控听力实验中收集的数据,我们的模型利用上下文学习和参数高效的微调技术,可靠地与人群偏好的均衡设置对齐。我们的评估方法利用了捕捉用户不同偏好的分布度量,显示出与随机抽样和静态预设基线相比,分布对齐方面具有统计意义上的显著改进。这些结果表明,LLM可以作为“人工均衡器”,有助于开发更易于访问、感知上下文和专家级的音频调优方法。
🔬 方法详解
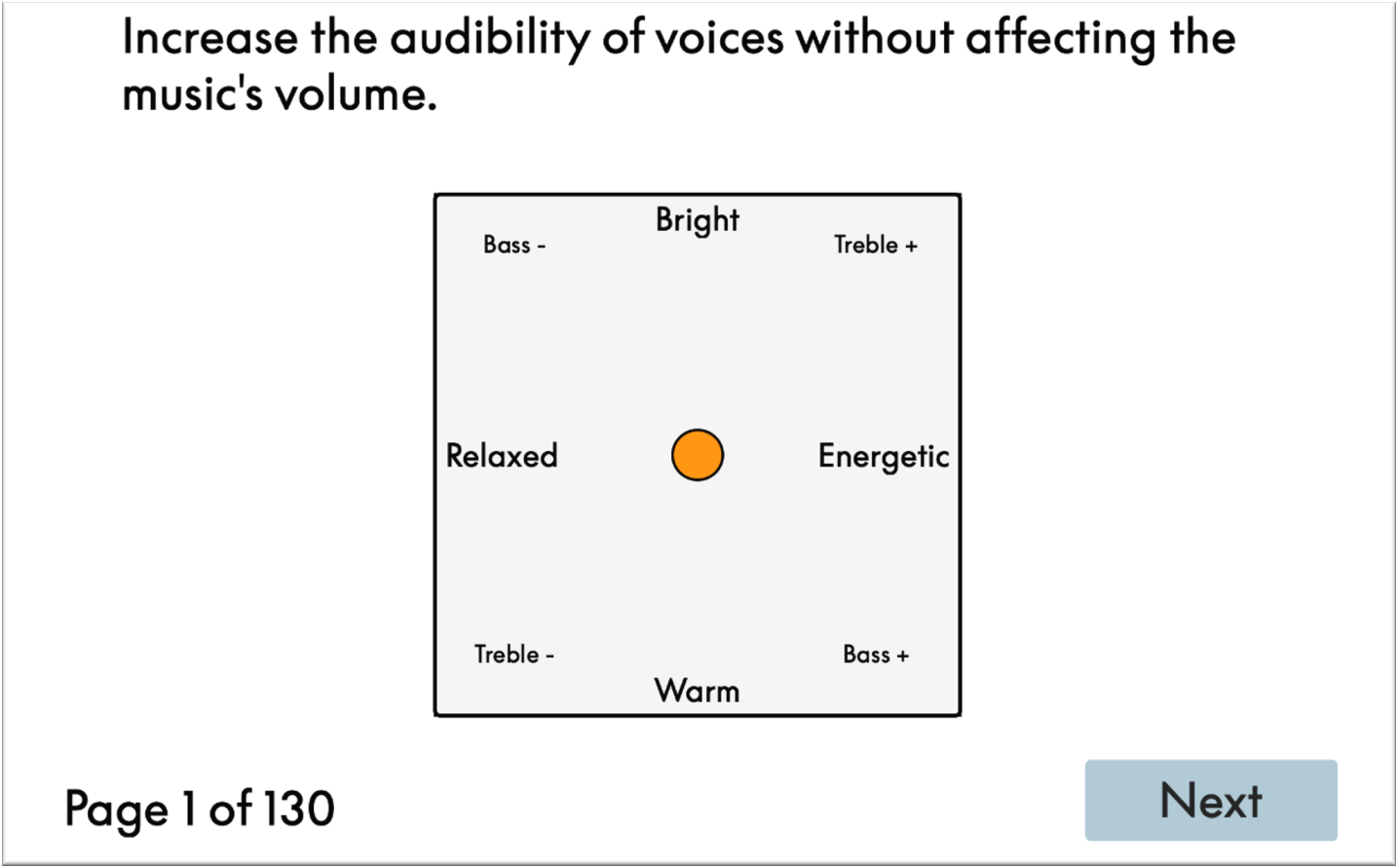
问题定义:传统音频均衡器需要手动调节,难以适应用户在不同情境下的个性化需求。现有方法缺乏智能化,无法根据用户的自然语言描述进行音效调整。
核心思路:利用大型语言模型(LLM)强大的自然语言理解和生成能力,将用户的自然语言指令映射到对应的音频均衡器参数。通过学习人群的偏好数据,使LLM能够预测用户在特定情境下的最佳均衡设置。
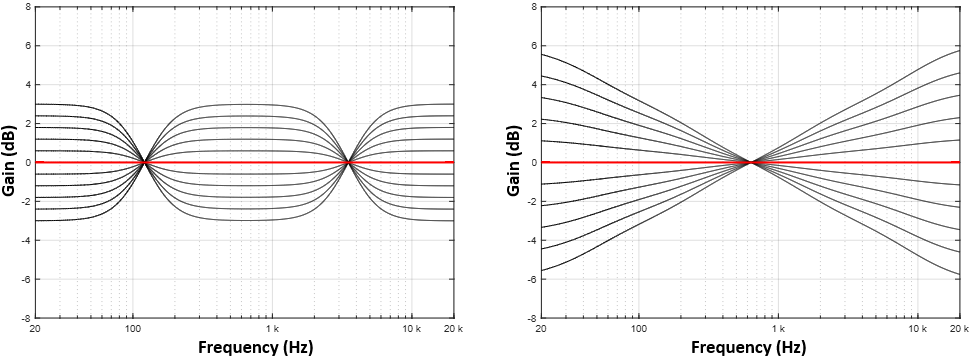
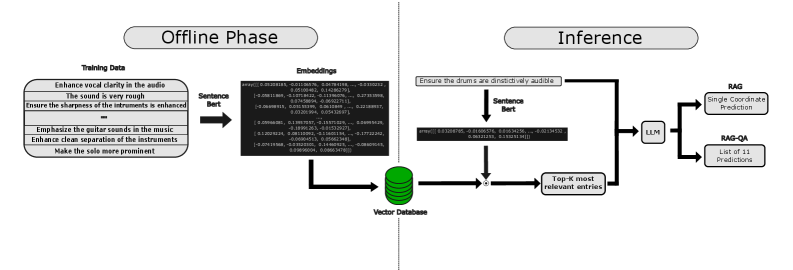
技术框架:该方法的核心是一个基于LLM的文本到均衡器参数的映射模型。首先,收集用户在不同情境下的音频均衡偏好数据。然后,利用这些数据对LLM进行微调,使其能够理解自然语言指令并生成相应的均衡器参数。最后,将生成的参数应用于音频信号,实现个性化的音效调整。
关键创新:该方法的核心创新在于将大型语言模型应用于音频均衡领域,实现了自然语言控制的音频调整。与传统的静态均衡器和手动调整方法相比,该方法更加智能化、个性化和易于使用。
关键设计:论文采用了参数高效的微调技术,以减少LLM的训练成本。同时,设计了基于分布度量的评估方法,以更全面地评估模型在捕捉用户不同偏好方面的性能。具体的损失函数和网络结构等技术细节在论文中进行了详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于LLM的音频均衡器在分布对齐方面显著优于随机抽样和静态预设基线。通过利用上下文学习和参数高效的微调技术,该模型能够可靠地与人群偏好的均衡设置对齐,为用户提供更加个性化的音频体验。具体的性能提升数据在论文中进行了详细展示。
🎯 应用场景
该研究成果可应用于智能音响、音乐播放器、音频编辑软件等领域,实现更加智能和个性化的音频体验。用户可以通过简单的自然语言指令,轻松调整音效,满足不同场景下的听音需求。未来,该技术有望应用于更广泛的音频处理领域,例如语音增强、音频修复等。
📄 摘要(原文)
Conventional audio equalization is a static process that requires manual and cumbersome adjustments to adapt to changing listening contexts (e.g., mood, location, or social setting). In this paper, we introduce a Large Language Model (LLM)-based alternative that maps natural language text prompts to equalization settings. This enables a conversational approach to sound system control. By utilizing data collected from a controlled listening experiment, our models exploit in-context learning and parameter-efficient fine-tuning techniques to reliably align with population-preferred equalization settings. Our evaluation methods, which leverage distributional metrics that capture users' varied preferences, show statistically significant improvements in distributional alignment over random sampling and static preset baselines. These results indicate that LLMs could function as "artificial equalizers," contributing to the development of more accessible, context-aware, and expert-level audio tuning methods.