STaR: Sensitive Trajectory Regulation for Unlearning in Large Reasoning Models
作者: Jingjing Zhou, Gaoxiang Cong, Li Su, Liang Li
分类: cs.AI
发布日期: 2026-01-14
💡 一句话要点
提出STaR框架,用于大模型推理过程中敏感轨迹的擦除,保障隐私安全。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 隐私保护 可信AI 推理擦除 敏感信息 思维链 轨迹调节
📋 核心要点
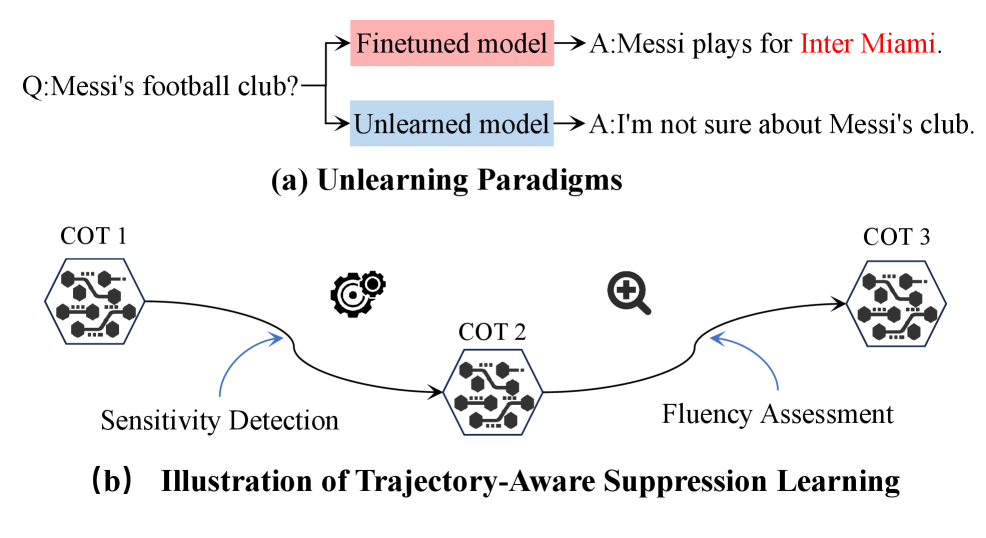
- 现有LLM擦除方法无法有效处理LRM中推理过程产生的敏感信息,导致隐私泄露。
- STaR框架通过语义感知检测、安全提示、轨迹感知抑制和令牌级过滤,实现推理全过程的隐私保护。
- 实验表明,STaR在R-TOFU基准上实现了全面且稳定的擦除,同时保持了较小的效用损失。
📝 摘要(中文)
大型推理模型(LRMs)在自动化多步推理方面取得了进展,但其生成复杂思维链(CoT)轨迹的能力带来了严重的隐私风险,因为敏感信息可能深层嵌入在整个推理过程中。现有的大型语言模型(LLMs)擦除方法通常只关注修改最终答案,对于LRMs来说是不够的,因为它们无法从中间步骤中删除敏感内容,导致持续的隐私泄露和安全性降低。为了解决这些挑战,我们提出了一种敏感轨迹调节(STaR)框架,这是一种无需参数、推理时的擦除框架,可在整个推理过程中实现强大的隐私保护。具体来说,我们首先通过语义感知检测识别敏感内容。然后,我们通过安全提示前缀注入全局安全约束。接下来,我们执行轨迹感知抑制,以动态阻止整个推理链中的敏感内容。最后,我们应用令牌级自适应过滤,以防止生成过程中出现精确和释义的敏感令牌。此外,为了克服现有评估协议的不足,我们引入了两个指标:多重解码一致性评估(MCS),用于衡量跨不同解码策略的擦除一致性;以及多粒度成员推理攻击(MIA)评估,用于量化答案和推理链级别的隐私保护。在R-TOFU基准上的实验表明,STaR实现了全面而稳定的擦除,同时最大限度地减少了效用损失,为LRMs中的隐私保护推理设定了新标准。
🔬 方法详解
问题定义:论文旨在解决大型推理模型(LRMs)在生成推理链(Chain-of-Thought, CoT)时,由于敏感信息可能嵌入在推理的中间步骤中,导致隐私泄露的问题。现有的大型语言模型(LLMs)擦除方法主要集中在修改最终答案,无法有效删除推理过程中的敏感内容,因此存在隐私保护不足的痛点。
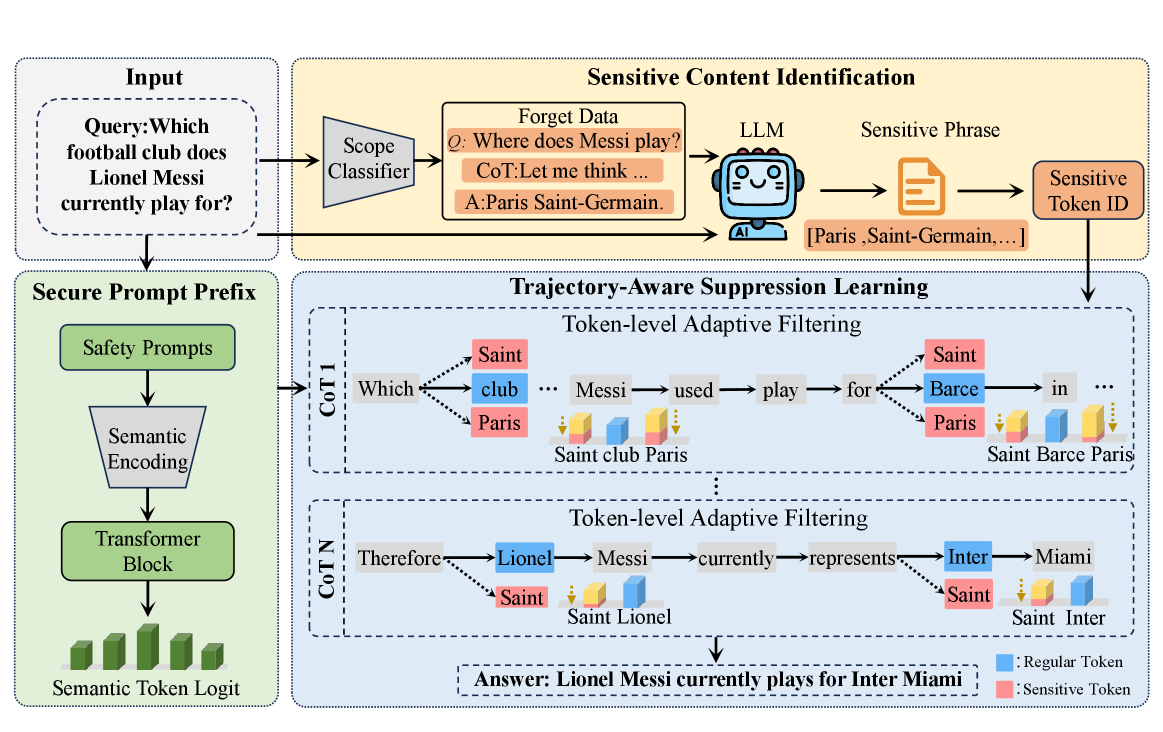
核心思路:论文的核心思路是在推理过程中对敏感轨迹进行调节,即Sensitive Trajectory Regulation (STaR)。通过在推理过程中动态地检测、抑制和过滤敏感内容,从而实现对整个推理链的隐私保护。这种方法无需修改模型参数,而是在推理时进行干预,降低了擦除的成本和风险。
技术框架:STaR框架包含四个主要模块:1) 语义感知检测:识别推理过程中的敏感内容;2) 安全提示前缀:通过在提示中加入安全约束,引导模型生成更安全的内容;3) 轨迹感知抑制:动态地阻止推理链中的敏感内容;4) 令牌级自适应过滤:防止生成过程中出现敏感的token,包括精确匹配和释义变体。
关键创新:STaR的关键创新在于其在推理过程中对敏感轨迹进行动态调节,而不仅仅是修改最终答案。这种方法能够更全面地保护隐私,因为它可以防止敏感信息在推理的中间步骤中泄露。此外,STaR是一种无需参数的擦除方法,降低了擦除的成本和风险。
关键设计:STaR的关键设计包括:1) 使用语义感知技术来检测敏感内容,提高了检测的准确性;2) 通过安全提示前缀来引导模型生成更安全的内容,降低了敏感信息生成的概率;3) 使用轨迹感知抑制来动态地阻止推理链中的敏感内容,确保敏感信息不会在推理过程中传播;4) 使用令牌级自适应过滤来防止生成过程中出现敏感的token,包括精确匹配和释义变体,提高了隐私保护的鲁棒性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,STaR框架在R-TOFU基准测试中取得了显著的性能提升,实现了全面且稳定的擦除,同时最大限度地减少了效用损失。此外,论文还提出了两个新的评估指标:多重解码一致性评估(MCS)和多粒度成员推理攻击(MIA)评估,为评估LLM的隐私保护能力提供了新的方法。
🎯 应用场景
该研究成果可应用于需要进行复杂推理但又涉及敏感信息的场景,例如医疗诊断、金融风控、法律咨询等。通过STaR框架,可以在保证推理能力的同时,有效地保护用户隐私,降低数据泄露的风险。未来,该技术有望被集成到各种LLM应用中,提升整体的隐私保护水平。
📄 摘要(原文)
Large Reasoning Models (LRMs) have advanced automated multi-step reasoning, but their ability to generate complex Chain-of-Thought (CoT) trajectories introduces severe privacy risks, as sensitive information may be deeply embedded throughout the reasoning process. Existing Large Language Models (LLMs) unlearning approaches that typically focus on modifying only final answers are insufficient for LRMs, as they fail to remove sensitive content from intermediate steps, leading to persistent privacy leakage and degraded security. To address these challenges, we propose Sensitive Trajectory Regulation (STaR), a parameter-free, inference-time unlearning framework that achieves robust privacy protection throughout the reasoning process. Specifically, we first identify sensitive content via semantic-aware detection. Then, we inject global safety constraints through secure prompt prefix. Next, we perform trajectory-aware suppression to dynamically block sensitive content across the entire reasoning chain. Finally, we apply token-level adaptive filtering to prevent both exact and paraphrased sensitive tokens during generation. Furthermore, to overcome the inadequacies of existing evaluation protocols, we introduce two metrics: Multi-Decoding Consistency Assessment (MCS), which measures the consistency of unlearning across diverse decoding strategies, and Multi-Granularity Membership Inference Attack (MIA) Evaluation, which quantifies privacy protection at both answer and reasoning-chain levels. Experiments on the R-TOFU benchmark demonstrate that STaR achieves comprehensive and stable unlearning with minimal utility loss, setting a new standard for privacy-preserving reasoning in LRMs.