RISER: Orchestrating Latent Reasoning Skills for Adaptive Activation Steering
作者: Wencheng Ye, Liang Peng, Xiaoyang Yuan, Yi Bin, Pengpeng Zeng, Hengyu Jin, Heng Tao Shen
分类: cs.AI
发布日期: 2026-01-14
💡 一句话要点
提出RISER框架以解决复杂推理中的动态干预问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理增强 动态干预 激活引导 强化学习 可重用向量 智能系统
📋 核心要点
- 现有方法在复杂推理中采用静态干预,无法适应动态变化,导致推理效果不佳。
- RISER框架通过构建可重用的推理向量库和动态路由器,实现了激活空间中的自适应推理引导。
- 在七个基准测试中,RISER相较于基础模型提升了3.4-6.5%的零-shot准确率,并在token效率上表现出2-3倍的优势。
📝 摘要(中文)
近年来,针对特定领域推理的大型语言模型(LLMs)研究通常依赖于需要更新参数的训练密集型方法。尽管激活引导作为一种参数高效的替代方案逐渐兴起,但现有方法采用的静态手动干预无法适应复杂推理的动态特性。为了解决这一局限性,本文提出了RISER(可引导推理增强的路由干预框架),该框架能够在激活空间中自适应地引导LLM推理。RISER构建了一个可重用推理向量库,并通过轻量级路由器动态组合这些向量。路由器通过强化学习在任务级奖励下进行优化,以新兴和组合的方式激活潜在的认知原语。在七个不同基准测试中,RISER在基础模型上实现了3.4-6.5%的零-shot准确率提升,同时在token效率和准确性方面超越了CoT风格推理。
🔬 方法详解
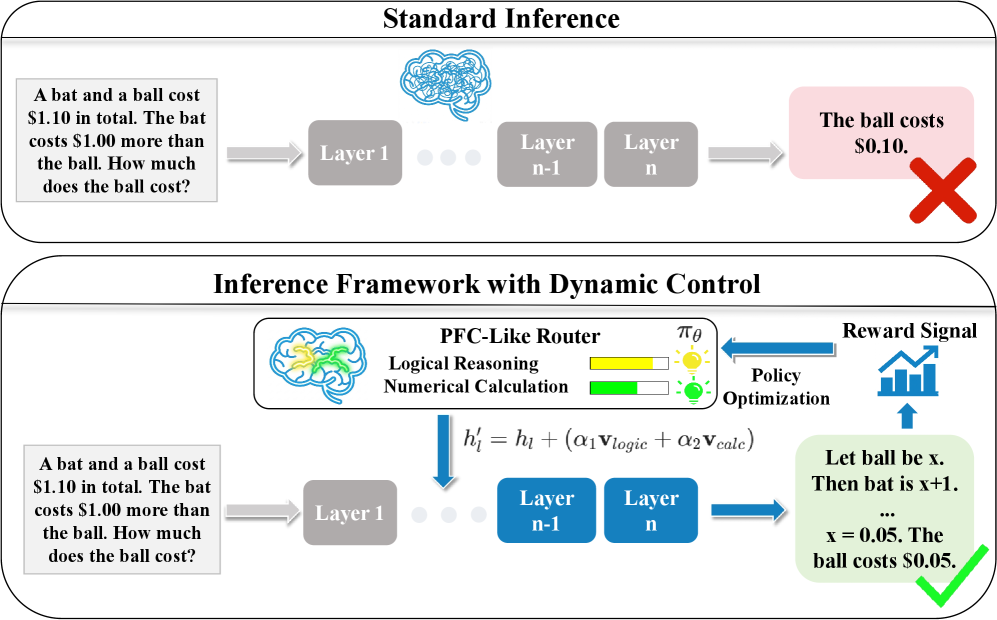
问题定义:本文旨在解决现有复杂推理方法中静态干预无法适应动态推理需求的问题。现有方法通常依赖于参数更新,导致训练成本高且灵活性不足。
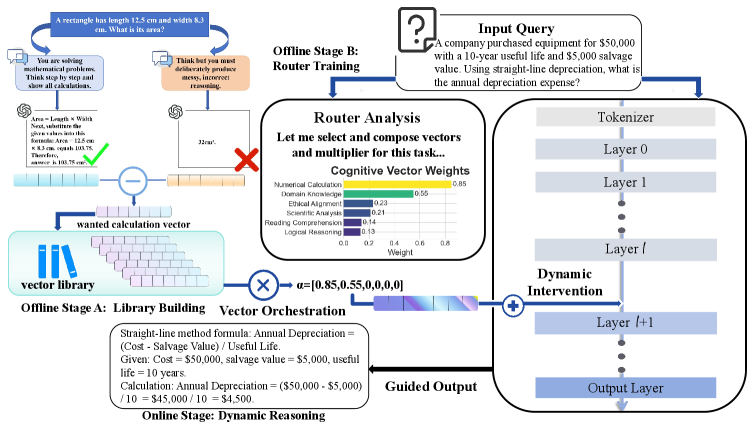
核心思路:RISER框架的核心思路是通过构建一个可重用的推理向量库,并利用轻量级路由器动态组合这些向量,从而实现对LLM推理的自适应引导。这样的设计使得推理过程更加灵活和高效。
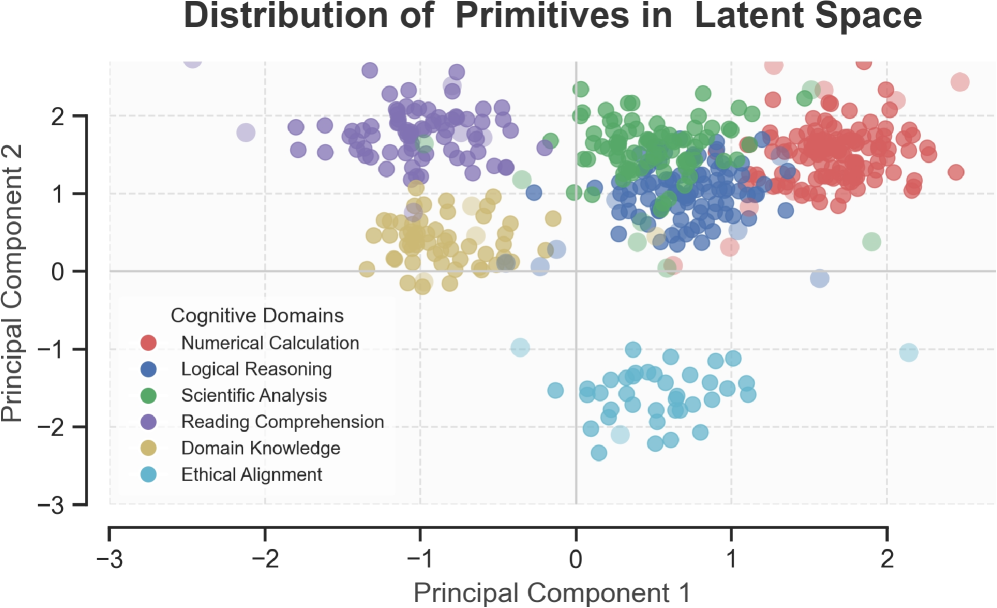
技术框架:RISER的整体架构包括推理向量库、路由器和强化学习优化模块。推理向量库存储可重用的认知原语,路由器负责根据输入动态选择和组合这些向量,强化学习模块则用于优化路由器的选择策略。
关键创新:RISER的主要创新在于其动态组合推理向量的能力,这与现有方法的静态干预形成鲜明对比。通过这种方式,RISER能够在推理过程中实现更高的灵活性和效率。
关键设计:在技术细节上,RISER采用了轻量级的路由器结构,结合强化学习的任务级奖励机制来优化向量组合策略。具体的损失函数和参数设置在实验中经过精心设计,以确保最佳性能。
🖼️ 关键图片
📊 实验亮点
在实验中,RISER在七个基准测试上实现了3.4-6.5%的零-shot准确率提升,且在token效率上超越了CoT风格推理,表现出2-3倍的优势。这些结果表明RISER在推理效率和准确性方面的显著改进。
🎯 应用场景
RISER框架在多个领域具有广泛的应用潜力,尤其是在需要复杂推理的任务中,如自然语言处理、智能问答和自动化决策等。通过提高推理的灵活性和效率,RISER能够为实际应用提供更强的支持,推动智能系统的发展。
📄 摘要(原文)
Recent work on domain-specific reasoning with large language models (LLMs) often relies on training-intensive approaches that require parameter updates. While activation steering has emerged as a parameter efficient alternative, existing methods apply static, manual interventions that fail to adapt to the dynamic nature of complex reasoning. To address this limitation, we propose RISER (Router-based Intervention for Steerable Enhancement of Reasoning), a plug-and-play intervention framework that adaptively steers LLM reasoning in activation space. RISER constructs a library of reusable reasoning vectors and employs a lightweight Router to dynamically compose them for each input. The Router is optimized via reinforcement learning under task-level rewards, activating latent cognitive primitives in an emergent and compositional manner. Across seven diverse benchmarks, RISER yields 3.4-6.5% average zero-shot accuracy improvements over the base model while surpassing CoT-style reasoning with 2-3x higher token efficiency and robust accuracy gains. Further analysis shows that RISER autonomously combines multiple vectors into interpretable, precise control strategies, pointing toward more controllable and efficient LLM reasoning.