Efficient Paths and Dense Rewards: Probabilistic Flow Reasoning for Large Language Models
作者: Yan Liu, Feng Zhang, Zhanyu Ma, Jun Xu, Jiuchong Gao, Jinghua Hao, Renqing He, Han Liu, Yangdong Deng
分类: cs.AI
发布日期: 2026-01-14
💡 一句话要点
提出CoT-Flow,通过概率流推理提升大语言模型的推理效率和性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 思维链 概率流 推理效率 强化学习 信息增益 流引导解码
📋 核心要点
- 现有CoT方法缺乏对推理步骤的信息增益量化,导致推理过程冗余和效率低下。
- CoT-Flow将离散推理步骤视为连续概率流,量化每步对最终答案的贡献,指导推理。
- CoT-Flow通过流引导解码和流强化学习,在推理效率和性能上取得了平衡。
📝 摘要(中文)
高质量的思维链(Chain-of-Thought, CoT)已展现出释放大型语言模型推理能力的巨大潜力。然而,目前的范式通常将推理过程视为一个不可分割的序列,缺乏量化逐步信息增益的内在机制。这种粒度上的差距体现在两个局限性上:一是由于缺乏明确指导而导致的冗余探索造成的推理效率低下;二是由于稀疏的结果监督或昂贵的外部验证器造成的优化困难。在这项工作中,我们提出了CoT-Flow,一个将离散推理步骤重新概念化为连续概率流的框架,量化每个步骤对真实答案的贡献。基于此,CoT-Flow实现了两种互补的方法:流引导解码,它采用基于贪婪流的解码策略来提取信息高效的推理路径;以及基于流的强化学习,它构建了一个无需验证器的密集奖励函数。在具有挑战性的基准测试上的实验表明,CoT-Flow在推理效率和推理性能之间取得了卓越的平衡。
🔬 方法详解
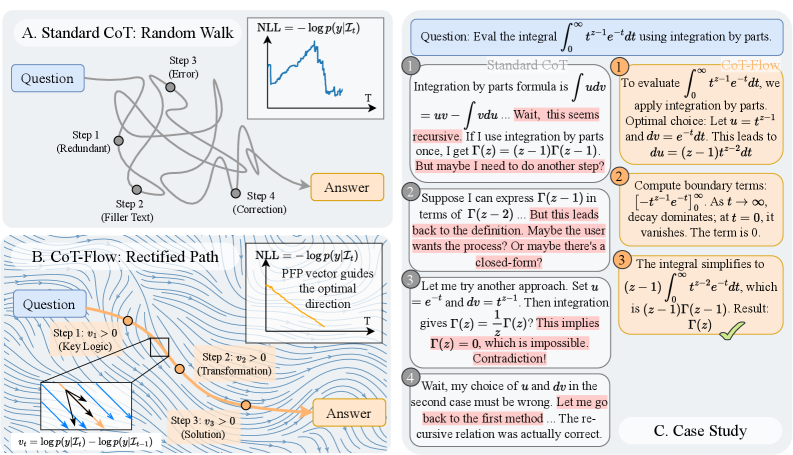
问题定义:现有的大语言模型推理方法,特别是基于思维链(CoT)的方法,通常将推理过程视为一个黑盒序列,缺乏对每个推理步骤贡献的细粒度理解。这导致两个主要问题:一是推理过程可能包含大量冗余步骤,浪费计算资源;二是由于缺乏对中间步骤的有效监督,模型训练困难,需要依赖昂贵的外部验证器或稀疏的最终结果奖励。
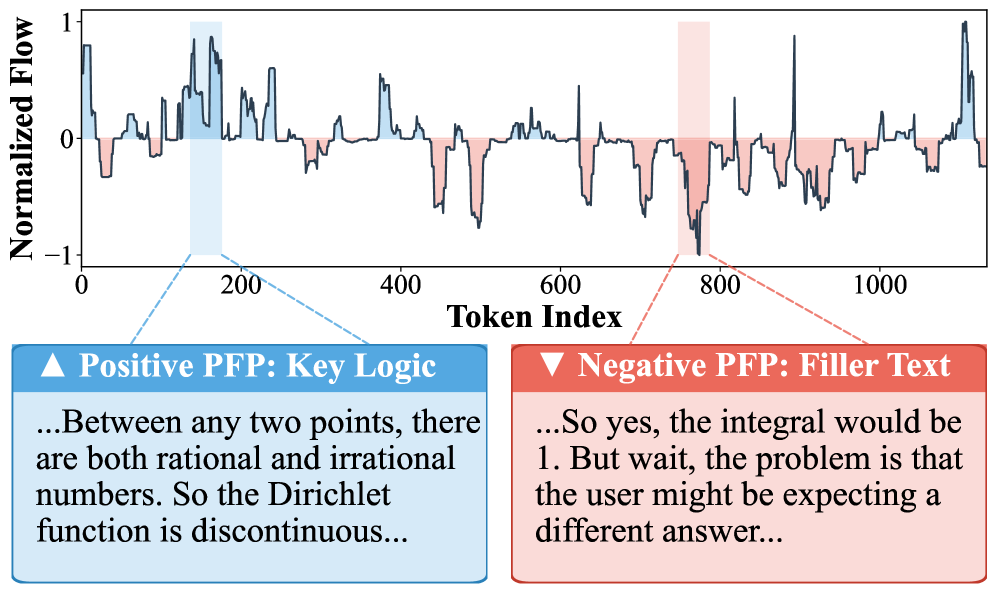
核心思路:CoT-Flow的核心思想是将离散的推理步骤建模为一个连续的概率流,每个步骤对最终答案的贡献可以通过概率流的大小来量化。通过这种方式,可以识别并优化信息增益最大的推理路径,从而提高推理效率和性能。同时,概率流的概念也为设计更有效的奖励函数提供了基础,避免了对外部验证器的依赖。
技术框架:CoT-Flow框架包含两个主要组成部分:流引导解码(Flow-Guided Decoding)和基于流的强化学习(Flow-Based Reinforcement Learning)。流引导解码利用概率流信息,采用贪婪策略选择信息增益最大的推理步骤,从而生成高效的推理路径。基于流的强化学习则利用概率流构建密集奖励函数,指导模型训练,无需外部验证器。
关键创新:CoT-Flow最重要的创新在于将离散推理步骤转化为连续概率流的建模方式。这种建模方式使得可以对每个推理步骤的贡献进行量化,从而为推理路径优化和奖励函数设计提供了新的视角。与传统的CoT方法相比,CoT-Flow能够更有效地利用信息,提高推理效率和性能。
关键设计:CoT-Flow的关键设计包括:1) 如何定义和计算推理步骤之间的概率流;2) 如何利用概率流信息指导解码过程,例如,设计贪婪策略选择概率流最大的步骤;3) 如何利用概率流构建密集奖励函数,例如,将概率流的大小作为奖励信号。具体的参数设置、损失函数和网络结构等细节取决于具体的应用场景和模型选择,论文中可能提供了更详细的描述。
🖼️ 关键图片
📊 实验亮点
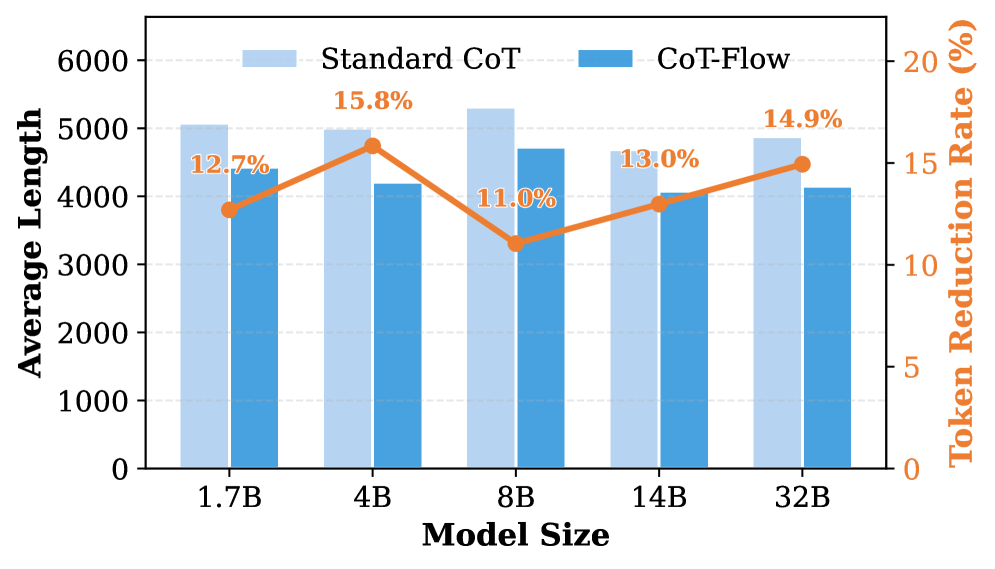
实验结果表明,CoT-Flow在多个具有挑战性的基准测试上取得了显著的性能提升。具体来说,CoT-Flow在推理效率和推理性能之间取得了更好的平衡,能够在保证性能的同时,显著减少推理所需的步骤数。论文中可能提供了具体的性能数据和对比基线,例如准确率、推理时间、步骤数等。
🎯 应用场景
CoT-Flow具有广泛的应用前景,可以应用于各种需要复杂推理的大语言模型任务,例如数学问题求解、常识推理、代码生成等。通过提高推理效率和性能,CoT-Flow可以降低大语言模型的部署成本,并使其能够处理更复杂的任务。此外,CoT-Flow的概率流建模思想也可以应用于其他序列生成任务,例如机器翻译、文本摘要等。
📄 摘要(原文)
High-quality chain-of-thought has demonstrated strong potential for unlocking the reasoning capabilities of large language models. However, current paradigms typically treat the reasoning process as an indivisible sequence, lacking an intrinsic mechanism to quantify step-wise information gain. This granularity gap manifests in two limitations: inference inefficiency from redundant exploration without explicit guidance, and optimization difficulty due to sparse outcome supervision or costly external verifiers. In this work, we propose CoT-Flow, a framework that reconceptualizes discrete reasoning steps as a continuous probabilistic flow, quantifying the contribution of each step toward the ground-truth answer. Built on this formulation, CoT-Flow enables two complementary methodologies: flow-guided decoding, which employs a greedy flow-based decoding strategy to extract information-efficient reasoning paths, and flow-based reinforcement learning, which constructs a verifier-free dense reward function. Experiments on challenging benchmarks demonstrate that CoT-Flow achieves a superior balance between inference efficiency and reasoning performance.