Uncovering Political Bias in Large Language Models using Parliamentary Voting Records
作者: Jieying Chen, Karen de Jong, Andreas Poole, Jan Burakowski, Elena Elderson Nosti, Joep Windt, Chendi Wang
分类: cs.AI
发布日期: 2026-01-13
💡 一句话要点
提出PoliBias基准,揭示大型语言模型在议会投票记录中的政治偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 政治偏见 议会投票记录 基准数据集 意识形态分析
📋 核心要点
- 现有研究对LLM的政治偏见缺乏系统性分析,难以评估其对社会的影响。
- 论文提出一种通用方法,通过对比LLM的投票预测与真实议会投票记录,构建政治偏见基准。
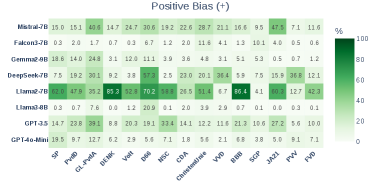
- 实验结果表明,主流LLM普遍存在左倾或中间派倾向,并对右翼保守党存在负面偏见。
📝 摘要(中文)
随着大型语言模型(LLMs)日益融入数字平台和决策系统,对其政治偏见的担忧日益增加。尽管大量工作研究了性别和种族等社会偏见,但对政治偏见的系统研究仍然有限,尽管其具有直接的社会影响。本文介绍了一种通用方法,通过将模型生成的投票预测与经过验证的议会投票记录对齐,来构建政治偏见基准。我们在三个国家案例研究中实例化了这种方法:PoliBiasNL(来自15个荷兰政党的2,701项荷兰议会动议和投票)、PoliBiasNO(来自9个挪威政党的10,584项动议和投票)和PoliBiasES(来自10个西班牙政党的2,480项动议和投票)。通过这些基准,我们评估了LLM行为中的意识形态倾向和政治实体偏见。作为评估框架的一部分,我们还提出了一种方法,通过将基于投票的立场与CHES维度联系起来,在共享的二维CHES(Chapel Hill Expert Survey)空间中可视化LLM和政党的意识形态,从而实现模型与现实世界政治参与者之间的直接且可解释的比较。我们的实验揭示了细粒度的意识形态差异:最先进的LLM始终表现出左倾或中间派倾向,以及对右翼保守党的明显负面偏见。这些发现突出了基于真实议会行为的透明、跨国评估对于理解和审计现代LLM中的政治偏见的价值。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中存在的政治偏见难以量化和评估的问题。现有方法主要关注社会偏见,而忽略了政治偏见对社会决策的潜在影响。缺乏系统性的政治偏见评估框架,使得无法有效识别和缓解LLM中的政治倾向。
核心思路:论文的核心思路是将LLM的投票预测与真实的议会投票记录进行对比,从而量化LLM的政治立场和偏见。通过构建包含多个国家议会投票数据的基准数据集,可以对LLM进行跨国评估,从而更全面地了解其政治倾向。这种方法基于LLM在模拟政治决策时的行为,直接反映了其潜在的政治偏见。
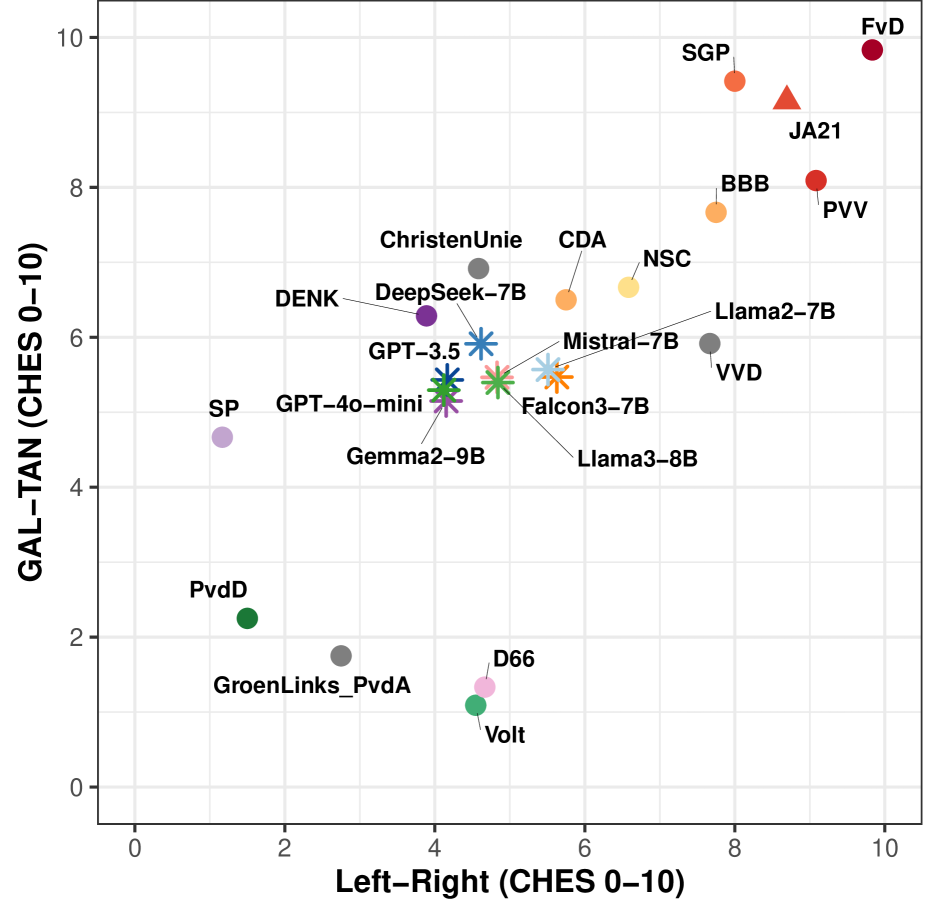
技术框架:该方法包含以下主要阶段:1) 构建政治偏见基准数据集,包括多个国家议会的投票记录和相关动议描述;2) 使用LLM对每个动议进行投票预测,生成LLM的投票记录;3) 将LLM的投票记录与真实议会投票记录进行对比,计算LLM与各政党之间的相似度;4) 使用CHES(Chapel Hill Expert Survey)数据,将LLM和政党的政治立场映射到二维空间,进行可视化分析。
关键创新:该方法的关键创新在于:1) 提出了一种通用的政治偏见评估框架,可以应用于不同国家和不同类型的LLM;2) 构建了包含多个国家议会投票数据的基准数据集,为政治偏见研究提供了数据基础;3) 提出了一种基于CHES数据的可视化方法,可以直观地展示LLM和政党的政治立场。
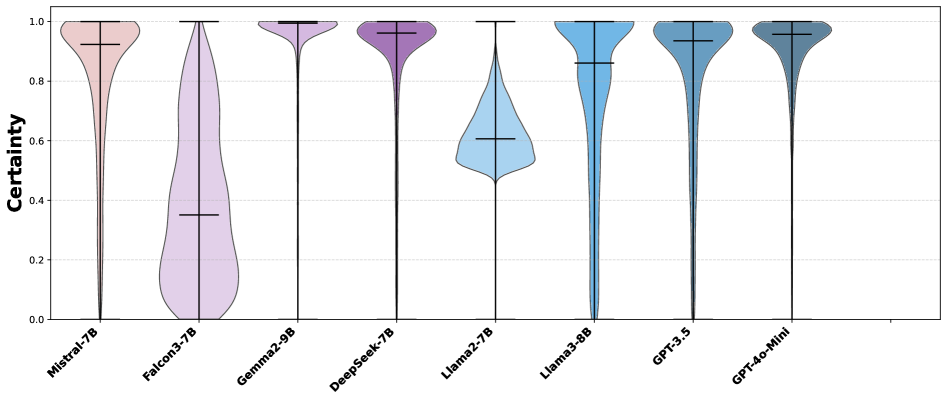
关键设计:在构建基准数据集时,需要确保数据的质量和代表性,包括选择合适的议会和政党,以及对动议描述进行清洗和预处理。在进行投票预测时,可以使用不同的提示工程技术来提高LLM的预测准确率。在计算相似度时,可以使用不同的距离度量方法,如余弦相似度或欧氏距离。在进行可视化分析时,需要选择合适的CHES维度,并对数据进行归一化处理。
🖼️ 关键图片
📊 实验亮点
实验结果表明,主流LLM在三个国家(荷兰、挪威、西班牙)的议会投票预测中普遍表现出左倾或中间派倾向,并对右翼保守党存在明显的负面偏见。通过CHES可视化分析,可以清晰地观察到LLM与不同政党之间的政治立场关系。该研究为LLM的政治偏见评估提供了有力的证据和方法。
🎯 应用场景
该研究成果可应用于LLM的政治偏见审计和风险评估,帮助开发者识别和缓解模型中的政治倾向,提高模型的公平性和透明度。此外,该方法还可以用于分析不同LLM之间的政治立场差异,为用户选择合适的模型提供参考。在政治决策辅助系统中,该研究有助于避免LLM的政治偏见对决策结果产生不良影响。
📄 摘要(原文)
As large language models (LLMs) become deeply embedded in digital platforms and decision-making systems, concerns about their political biases have grown. While substantial work has examined social biases such as gender and race, systematic studies of political bias remain limited, despite their direct societal impact. This paper introduces a general methodology for constructing political bias benchmarks by aligning model-generated voting predictions with verified parliamentary voting records. We instantiate this methodology in three national case studies: PoliBiasNL (2,701 Dutch parliamentary motions and votes from 15 political parties), PoliBiasNO (10,584 motions and votes from 9 Norwegian parties), and PoliBiasES (2,480 motions and votes from 10 Spanish parties). Across these benchmarks, we assess ideological tendencies and political entity bias in LLM behavior. As part of our evaluation framework, we also propose a method to visualize the ideology of LLMs and political parties in a shared two-dimensional CHES (Chapel Hill Expert Survey) space by linking their voting-based positions to the CHES dimensions, enabling direct and interpretable comparisons between models and real-world political actors. Our experiments reveal fine-grained ideological distinctions: state-of-the-art LLMs consistently display left-leaning or centrist tendencies, alongside clear negative biases toward right-conservative parties. These findings highlight the value of transparent, cross-national evaluation grounded in real parliamentary behavior for understanding and auditing political bias in modern LLMs.