From Classical to Quantum Reinforcement Learning and Its Applications in Quantum Control: A Beginner's Tutorial
作者: Abhijit Sen, Sonali Panda, Mahima Arya, Subhajit Patra, Zizhan Zheng, Denys I. Bondar
分类: cs.AI, quant-ph
发布日期: 2026-01-13
💡 一句话要点
强化学习入门教程:从经典到量子,应用于量子控制
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 量子强化学习 教程 编程 量子控制
📋 核心要点
- 现有强化学习教程在理论与实践之间存在脱节,学生难以将概念知识转化为实际代码。
- 本教程通过提供大量示例和清晰解释,旨在弥合理论与实践的鸿沟,降低学习门槛。
- 通过动手实践,学生能够掌握强化学习的基础技能,并将其应用于实际场景中。
📝 摘要(中文)
本教程旨在通过清晰的、以实例驱动的解释,使强化学习(RL)更容易被本科生理解。它侧重于弥合强化学习理论与实际编码应用之间的差距,解决学生在从概念理解过渡到实现时面临的常见挑战。通过动手示例和易于理解的解释,本教程旨在使学生掌握在实际场景中自信地应用强化学习技术所需的基础技能。
🔬 方法详解
问题定义:现有强化学习教程往往侧重于理论推导,缺乏足够的实践指导,导致学生在尝试将理论知识应用于实际问题时遇到困难。学生难以理解如何将抽象的强化学习概念转化为可执行的代码,以及如何调试和优化强化学习算法。
核心思路:本教程的核心思路是通过提供大量精心设计的示例,引导学生逐步掌握强化学习的编程技巧。这些示例涵盖了强化学习的各个方面,从简单的环境到复杂的控制问题,帮助学生建立起理论与实践之间的桥梁。教程还注重解释常见的编程错误和调试技巧,帮助学生克服学习过程中的障碍。
技术框架:本教程采用循序渐进的方式,首先介绍经典的强化学习算法,如Q-learning和SARSA,然后逐步过渡到更高级的算法,如深度强化学习。每个算法都配有详细的代码示例和解释。此外,教程还介绍了如何使用常见的强化学习库,如OpenAI Gym和TensorFlow,以及如何将强化学习应用于量子控制等实际问题。
关键创新:本教程的关键创新在于其以示例驱动的教学方法。与传统的理论驱动的教程不同,本教程更加注重实践,通过大量的代码示例和动手练习,帮助学生快速掌握强化学习的编程技能。此外,本教程还涵盖了量子强化学习的内容,为学生提供了探索量子计算领域的机会。
关键设计:教程中的示例代码采用Python语言编写,并使用了常见的强化学习库。每个示例都包含详细的注释和解释,帮助学生理解代码的逻辑和实现细节。教程还提供了大量的练习题和项目,供学生巩固所学知识。在量子强化学习部分,教程介绍了量子比特、量子门等基本概念,并展示了如何使用量子计算机进行强化学习。
🖼️ 关键图片
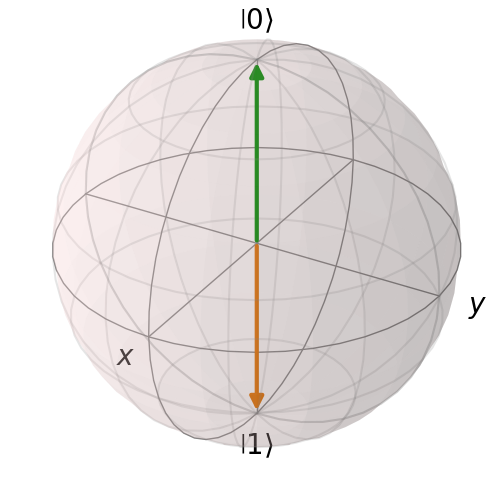
📊 实验亮点
本教程通过提供大量示例和清晰解释,降低了强化学习的学习门槛,使本科生也能轻松入门。教程涵盖了从经典强化学习到量子强化学习的内容,为学生提供了全面的学习资源。通过动手实践,学生能够掌握强化学习的基础技能,并将其应用于实际场景中。
🎯 应用场景
该教程旨在帮助学生掌握强化学习的基础知识和编程技能,为他们将来从事人工智能、机器人、控制工程等领域的研究和开发工作打下坚实的基础。特别是,教程中关于量子强化学习的内容,为学生提供了探索量子计算在人工智能领域应用的机会,具有重要的前瞻性。
📄 摘要(原文)
This tutorial is designed to make reinforcement learning (RL) more accessible to undergraduate students by offering clear, example-driven explanations. It focuses on bridging the gap between RL theory and practical coding applications, addressing common challenges that students face when transitioning from conceptual understanding to implementation. Through hands-on examples and approachable explanations, the tutorial aims to equip students with the foundational skills needed to confidently apply RL techniques in real-world scenarios.