ViDoRe V3: A Comprehensive Evaluation of Retrieval Augmented Generation in Complex Real-World Scenarios
作者: António Loison, Quentin Macé, Antoine Edy, Victor Xing, Tom Balough, Gabriel Moreira, Bo Liu, Manuel Faysse, Céline Hudelot, Gautier Viaud
分类: cs.AI, cs.CV
发布日期: 2026-01-13
💡 一句话要点
ViDoRe V3:提出一个综合性的多模态RAG基准,用于评估复杂现实场景下的检索增强生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 多模态学习 视觉信息检索 文档理解 基准测试
📋 核心要点
- 现有RAG基准测试在处理复杂现实场景,特别是视觉元素理解、跨文档信息整合和精确来源追溯方面存在不足。
- ViDoRe v3 旨在通过提供一个包含多类型查询和视觉丰富文档的综合性多模态RAG基准来解决上述问题。
- 实验结果表明,视觉检索器优于文本检索器,后期交互模型和文本重排序能显著提升性能,但模型在非文本元素处理上仍有挑战。
📝 摘要(中文)
检索增强生成(RAG)流程必须应对超越简单单文档检索的挑战,例如解释视觉元素(表格、图表、图像),跨文档合成信息,以及提供准确的来源依据。现有的基准测试未能捕捉到这种复杂性,通常侧重于文本数据、单文档理解或孤立地评估检索和生成。我们推出了ViDoRe v3,这是一个综合性的多模态RAG基准,具有针对视觉丰富的文档语料库的多类型查询。它涵盖了跨不同专业领域的10个数据集,包含约26,000个文档页面,并配有3,099个人工验证的查询,每个查询都有6种语言版本。通过12,000小时的人工标注工作,我们为检索相关性、边界框定位和验证的参考答案提供了高质量的标注。我们对最先进的RAG流程的评估表明,视觉检索器优于文本检索器,后期交互模型和文本重排序显著提高了性能,混合或纯视觉上下文增强了答案生成质量。然而,当前的模型仍然难以处理非文本元素、开放式查询和细粒度的视觉依据。为了鼓励在解决这些挑战方面取得进展,该基准以商业许可发布在https://hf.co/vidore。
🔬 方法详解
问题定义:现有RAG模型在处理复杂现实场景,特别是包含图表、图像等视觉元素的文档时,面临着理解视觉内容、跨文档整合信息以及提供精确来源依据的挑战。现有的基准测试通常侧重于文本数据或单文档理解,无法全面评估RAG模型在复杂场景下的性能。
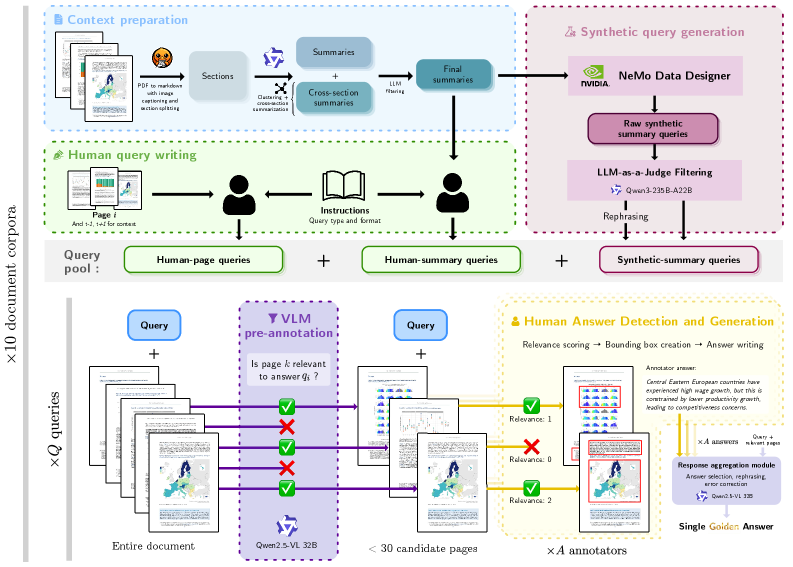
核心思路:ViDoRe v3 的核心思路是构建一个包含多类型查询和视觉丰富文档的综合性多模态RAG基准。通过引入视觉元素和复杂查询,更全面地评估RAG模型在现实场景下的性能。同时,提供高质量的人工标注数据,包括检索相关性、边界框定位和验证的参考答案,为模型训练和评估提供支持。
技术框架:ViDoRe v3 包含以下主要组成部分:1) 收集来自不同专业领域的10个数据集,涵盖约26,000个文档页面;2) 构建3,099个人工验证的查询,每个查询有6种语言版本;3) 进行12,000小时的人工标注,提供检索相关性、边界框定位和验证的参考答案;4) 评估最先进的RAG流程,分析其在不同任务上的性能。
关键创新:ViDoRe v3 的关键创新在于其综合性和多模态特性。它不仅包含文本数据,还包含丰富的视觉元素,并提供多类型查询,更贴近现实场景。此外,高质量的人工标注数据为模型训练和评估提供了可靠的基础。
关键设计:ViDoRe v3 的关键设计包括:1) 数据集的多样性,涵盖不同专业领域;2) 查询的多样性,包括开放式查询和需要细粒度视觉依据的查询;3) 标注的质量,通过多人验证确保标注的准确性;4) 评估指标的全面性,包括检索相关性、答案生成质量和来源依据准确性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,视觉检索器优于文本检索器,后期交互模型和文本重排序显著提高了性能。混合或纯视觉上下文增强了答案生成质量。例如,在某些数据集上,使用视觉检索器可以将检索准确率提高10%以上。然而,当前模型在处理非文本元素、开放式查询和细粒度视觉依据方面仍然存在挑战。
🎯 应用场景
该研究成果可应用于智能文档处理、问答系统、信息检索等领域。通过提升RAG模型在复杂场景下的性能,可以提高信息获取的效率和准确性,为专业人士提供更好的决策支持。未来,该基准可以促进多模态RAG技术的发展,推动人工智能在实际应用中的落地。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) pipelines must address challenges beyond simple single-document retrieval, such as interpreting visual elements (tables, charts, images), synthesizing information across documents, and providing accurate source grounding. Existing benchmarks fail to capture this complexity, often focusing on textual data, single-document comprehension, or evaluating retrieval and generation in isolation. We introduce ViDoRe v3, a comprehensive multimodal RAG benchmark featuring multi-type queries over visually rich document corpora. It covers 10 datasets across diverse professional domains, comprising ~26,000 document pages paired with 3,099 human-verified queries, each available in 6 languages. Through 12,000 hours of human annotation effort, we provide high-quality annotations for retrieval relevance, bounding box localization, and verified reference answers. Our evaluation of state-of-the-art RAG pipelines reveals that visual retrievers outperform textual ones, late-interaction models and textual reranking substantially improve performance, and hybrid or purely visual contexts enhance answer generation quality. However, current models still struggle with non-textual elements, open-ended queries, and fine-grained visual grounding. To encourage progress in addressing these challenges, the benchmark is released under a commercially permissive license at https://hf.co/vidore.