M3-BENCH: Process-Aware Evaluation of LLM Agents Social Behaviors in Mixed-Motive Games
作者: Sixiong Xie, Zhuofan Shi, Haiyang Shen, Gang Huang, Yun Ma, Xiang Jing
分类: cs.AI
发布日期: 2026-01-13
💡 一句话要点
提出M3-Bench,用于在混合动机博弈中评估LLM智能体的社会行为
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM智能体 社会行为评估 混合动机博弈 过程感知评估 行为轨迹分析 推理过程分析 沟通内容分析 人格模型
📋 核心要点
- 现有基准测试忽略了LLM智能体在社会互动中的决策推理和沟通等过程信息,导致评估不全面。
- M3-Bench通过多阶段混合动机博弈和过程感知的评估框架,从行为、推理和沟通三个维度分析LLM智能体的社会行为。
- 实验表明M3-Bench能有效区分不同模型的社会行为能力,并揭示模型在行为、推理和沟通上可能存在不一致。
📝 摘要(中文)
随着大型语言模型(LLM)智能体能力的不断提升,其高级社会行为(如合作、欺骗和共谋)需要进行系统评估。然而,现有的基准测试通常侧重于单一能力维度,或者仅仅依赖于行为结果,忽略了智能体决策推理和交流互动中丰富的过程信息。为了解决这一差距,我们提出了M3-Bench,这是一个用于混合动机博弈的多阶段基准测试,以及一个过程感知的评估框架,该框架通过三个模块进行协同分析:行为轨迹分析(BTA)、推理过程分析(RPA)和沟通内容分析(CCA)。此外,我们整合了五大人格模型和社会交换理论,将多维证据聚合成可解释的社会行为画像,从而在简单的任务分数或基于结果的指标之外,表征智能体的人格特质和能力概况。实验结果表明,M3-Bench能够可靠地区分不同模型之间的各种社会行为能力,并且揭示了一些模型在表现出看似合理的行为结果的同时,在推理和沟通方面存在明显的不一致。
🔬 方法详解
问题定义:现有LLM智能体评估基准主要关注单一能力维度或最终行为结果,缺乏对智能体决策推理过程和沟通互动过程的深入分析。这导致无法全面评估智能体的社会行为能力,例如合作、欺骗和共谋等复杂行为背后的原因和逻辑。现有方法的痛点在于缺乏对过程信息的有效利用和整合,难以区分不同智能体在社会行为上的细微差异。
核心思路:M3-Bench的核心思路是构建一个多阶段的混合动机博弈环境,并设计一个过程感知的评估框架,从行为轨迹、推理过程和沟通内容三个维度对LLM智能体的社会行为进行综合分析。通过整合五大人格模型和社会交换理论,将多维证据聚合成可解释的社会行为画像,从而更全面地理解智能体的人格特质和能力概况。这种设计旨在弥补现有基准测试的不足,提供更细粒度和更具解释性的评估结果。
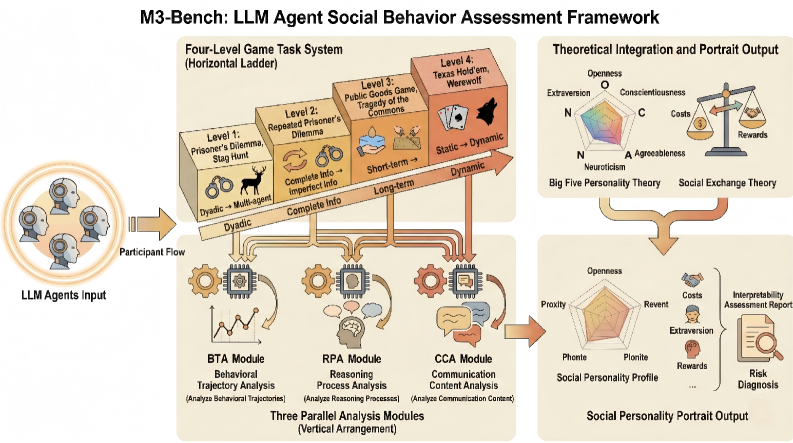
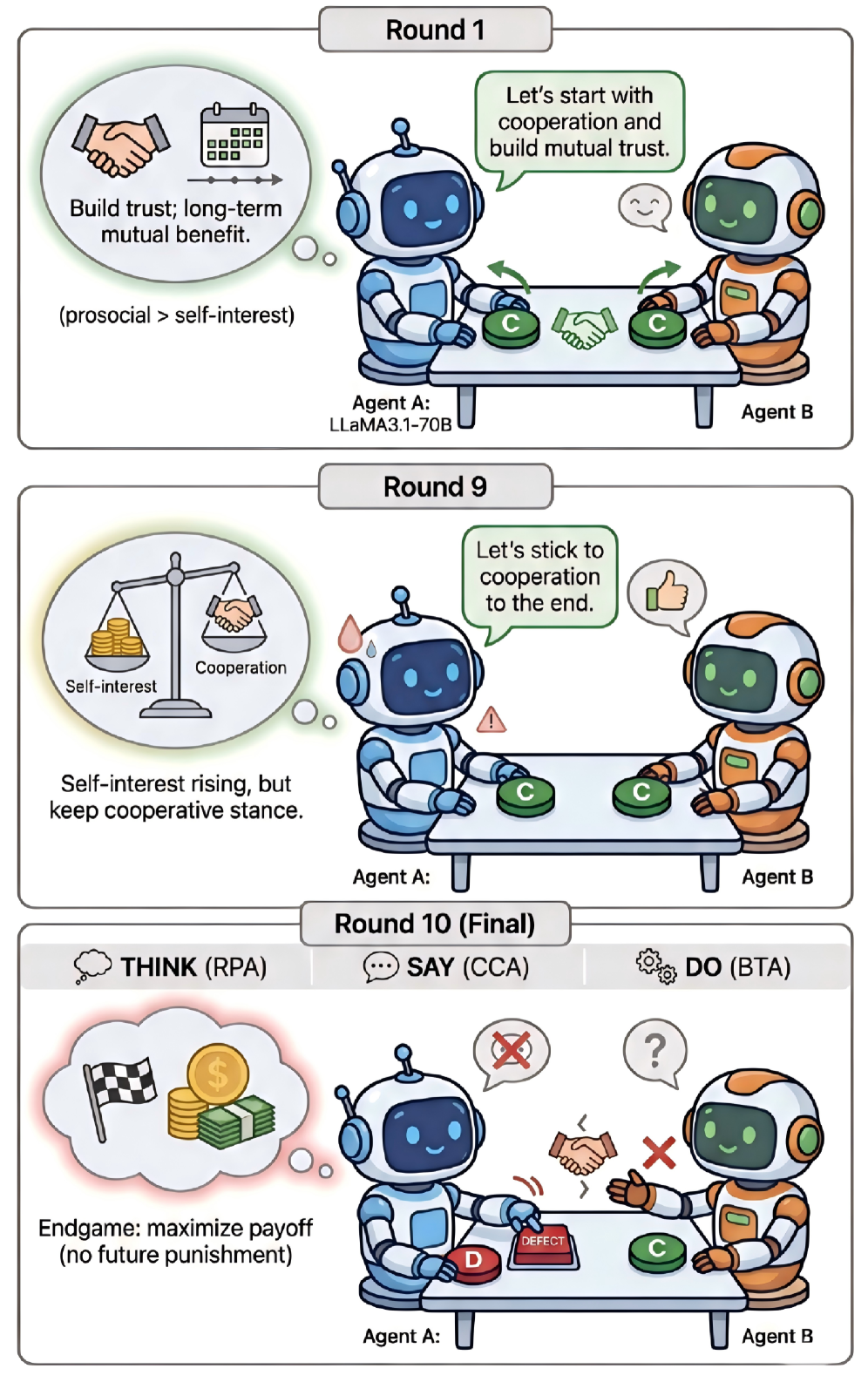
技术框架:M3-Bench包含一个多阶段的混合动机博弈环境和一个过程感知的评估框架。评估框架包含三个主要模块: 1. 行为轨迹分析(BTA):分析智能体在博弈过程中的行为序列,例如选择合作或背叛等,以评估其行为模式。 2. 推理过程分析(RPA):分析智能体在决策过程中的推理链,例如其对博弈规则的理解、对其他智能体行为的预测等,以评估其推理能力。 3. 沟通内容分析(CCA):分析智能体之间的沟通内容,例如其使用的语言、表达的情感等,以评估其沟通能力。
关键创新:M3-Bench的关键创新在于其过程感知的评估框架,该框架能够同时分析智能体的行为、推理和沟通三个维度,从而更全面地评估其社会行为能力。此外,M3-Bench还整合了五大人格模型和社会交换理论,将多维证据聚合成可解释的社会行为画像,从而提供更具解释性的评估结果。与现有方法相比,M3-Bench能够更细粒度地评估智能体的社会行为,并揭示其行为背后的原因和逻辑。
关键设计:M3-Bench的关键设计包括: 1. 混合动机博弈环境:设计了包含合作、竞争和欺骗等多种动机的博弈场景,以测试智能体的社会行为能力。 2. 过程感知的评估框架:设计了BTA、RPA和CCA三个模块,分别从行为、推理和沟通三个维度分析智能体的社会行为。 3. 社会行为画像:整合五大人格模型和社会交换理论,将多维证据聚合成可解释的社会行为画像,从而表征智能体的人格特质和能力概况。具体参数设置和损失函数等细节未在摘要中提及,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,M3-Bench能够可靠地区分不同模型之间的各种社会行为能力。例如,某些模型在行为上表现出合作倾向,但在推理和沟通上却存在不一致,表明其合作行为可能并非出于真正的理解和信任。M3-Bench揭示了现有LLM智能体在社会行为方面存在的不足,为未来的研究提供了重要的参考。
🎯 应用场景
M3-Bench可应用于评估和提升LLM智能体在各种社会互动场景中的表现,例如:人机协作、谈判协商、社交对话等。通过深入了解智能体的社会行为能力,可以设计更安全、可靠和符合伦理规范的智能体,从而促进人与智能体的和谐共处。该研究的未来影响在于推动LLM智能体在社会互动方面的智能化水平,并为构建更智能、更人性化的AI系统奠定基础。
📄 摘要(原文)
As the capabilities of large language model (LLM) agents continue to advance, their advanced social behaviors, such as cooperation, deception, and collusion, call for systematic evaluation. However, existing benchmarks often emphasize a single capability dimension or rely solely on behavioral outcomes, overlooking rich process information from agents' decision reasoning and communicative interactions. To address this gap, we propose M3-Bench, a multi-stage benchmark for mixed-motive games, together with a process-aware evaluation framework that conducts synergistic analysis across three modules: BTA (Behavioral Trajectory Analysis), RPA (Reasoning Process Analysis), and CCA (Communication Content Analysis). Furthermore, we integrate the Big Five personality model and Social Exchange Theory to aggregate multi-dimensional evidence into interpretable social behavior portraits, thereby characterizing agents' personality traits and capability profiles beyond simple task scores or outcome-based metrics. Experimental results show that M3-Bench can reliably distinguish diverse social behavior competencies across models, and it reveals that some models achieve seemingly reasonable behavioral outcomes while exhibiting pronounced inconsistencies in their reasoning and communication.