YaPO: Learnable Sparse Activation Steering Vectors for Domain Adaptation
作者: Abdelaziz Bounhar, Rania Hossam Elmohamady Elbadry, Hadi Abdine, Preslav Nakov, Michalis Vazirgiannis, Guokan Shang
分类: cs.AI
发布日期: 2026-01-13
🔗 代码/项目: GITHUB
💡 一句话要点
YaPO:通过可学习的稀疏激活引导向量实现领域自适应
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 领域自适应 稀疏自编码器 引导向量 文化对齐
📋 核心要点
- 现有密集引导向量方法因神经元多语义性,在细粒度领域自适应任务中表现受限,难以区分密切相关的价值观和行为。
- YaPO通过在稀疏自编码器的潜在空间中学习稀疏引导向量,实现了解耦、可解释和高效的引导方向。
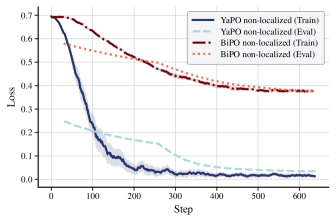
- 实验表明,YaPO相比密集引导基线,收敛更快,性能更强,训练更稳定,且能泛化到多种对齐相关行为,同时保持通用知识。
📝 摘要(中文)
通过激活干预引导大型语言模型(LLMs)已成为微调之外的一种轻量级替代方案,用于对齐和个性化。双向偏好优化(BiPO)的最新研究表明,可以从直接偏好优化(DPO)中的偏好数据直接学习密集引导向量,从而实现对真实性、幻觉和安全行为的控制。然而,由于神经元的多语义性,密集引导向量通常会纠缠多个潜在因素,从而限制了它们在文化对齐等细粒度环境中的有效性和稳定性,在这些环境中,必须区分密切相关的价值观和行为(例如,中东文化之间)。在本文中,我们提出了一种名为YaPO(Yet another Policy Optimization)的 extit{无参考}方法,该方法在稀疏自编码器(SAE)的潜在空间中学习 extit{稀疏引导向量}。通过优化稀疏代码,YaPO产生了解耦、可解释和高效的引导方向。实验结果表明,与密集引导基线相比,YaPO收敛速度更快,性能更强,并且表现出更高的训练稳定性。除了文化对齐之外,YaPO还可以推广到一系列与对齐相关的行为,包括幻觉、寻富、越狱和权力寻租。重要的是,YaPO保留了一般知识,在MMLU上没有可衡量的退化。总的来说,我们的结果表明,YaPO为LLM的高效、稳定和细粒度对齐提供了一个通用的方法,具有广泛的可控性和领域自适应应用。相关的代码和数据已公开发布。
🔬 方法详解
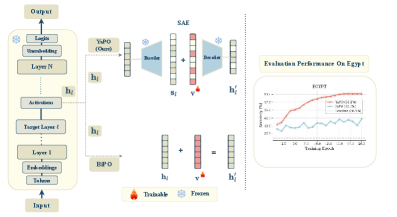
问题定义:论文旨在解决大型语言模型(LLMs)在领域自适应,特别是细粒度文化对齐任务中的挑战。现有方法,如基于密集引导向量的BiPO,由于神经元的多语义性,导致引导向量纠缠多个潜在因素,限制了其在区分密切相关价值观和行为方面的有效性。因此,需要一种能够产生解耦、可解释和高效引导方向的方法。
核心思路:YaPO的核心思路是在稀疏自编码器(SAE)的潜在空间中学习稀疏引导向量。通过优化稀疏代码,YaPO能够产生解耦的引导方向,从而更好地控制LLM的行为。稀疏性促进了引导向量的解释性,并提高了效率。这种方法避免了密集向量的纠缠问题,使得模型能够更精确地调整LLM在特定领域或文化中的行为。
技术框架:YaPO的技术框架主要包括以下几个阶段:首先,使用稀疏自编码器(SAE)对LLM的激活空间进行编码,得到稀疏的潜在表示。然后,通过优化稀疏代码,学习稀疏引导向量。这个优化过程是无参考的,即不需要显式的偏好数据。最后,将学习到的稀疏引导向量应用于LLM,以控制其行为。整个框架旨在实现高效、稳定和细粒度的LLM对齐。
关键创新:YaPO最重要的技术创新点在于使用稀疏自编码器学习稀疏引导向量。与现有基于密集向量的方法相比,YaPO的稀疏性促进了解耦,提高了可解释性和效率。此外,YaPO是一种无参考方法,不需要显式的偏好数据,降低了数据收集的成本。这种稀疏引导向量的方法能够更精确地控制LLM的行为,特别是在细粒度领域自适应任务中。
关键设计:YaPO的关键设计包括:1) 使用稀疏自编码器(SAE)来提取LLM激活空间的稀疏表示。SAE的目标是最小化重构误差,同时鼓励稀疏性。2) 优化稀疏代码以学习稀疏引导向量。这个优化过程可以使用各种优化算法,例如梯度下降。3) 将学习到的稀疏引导向量应用于LLM,以控制其行为。具体的应用方式取决于LLM的架构和任务。
🖼️ 关键图片

📊 实验亮点
YaPO在实验中表现出显著的优势。与密集引导基线相比,YaPO收敛速度更快,性能更强,训练更稳定。在文化对齐任务中,YaPO能够更精确地控制LLM的行为。此外,YaPO还能够泛化到一系列与对齐相关的行为,包括幻觉、寻富、越狱和权力寻租。重要的是,YaPO在保持通用知识方面表现出色,在MMLU上没有可衡量的退化。
🎯 应用场景
YaPO具有广泛的应用前景,包括文化对齐、个性化定制、安全策略调整等。它可以用于开发更符合特定文化价值观的LLM,也可以用于根据用户的个性化需求定制LLM的行为。此外,YaPO还可以用于提高LLM的安全性,例如防止LLM生成有害或不当的内容。该研究对于推动LLM在各个领域的应用具有重要的实际价值和未来影响。
📄 摘要(原文)
Steering Large Language Models (LLMs) through activation interventions has emerged as a lightweight alternative to fine-tuning for alignment and personalization. Recent work on Bi-directional Preference Optimization (BiPO) shows that dense steering vectors can be learned directly from preference data in a Direct Preference Optimization (DPO) fashion, enabling control over truthfulness, hallucinations, and safety behaviors. However, dense steering vectors often entangle multiple latent factors due to neuron multi-semanticity, limiting their effectiveness and stability in fine-grained settings such as cultural alignment, where closely related values and behaviors (e.g., among Middle Eastern cultures) must be distinguished. In this paper, we propose Yet another Policy Optimization (YaPO), a \textit{reference-free} method that learns \textit{sparse steering vectors} in the latent space of a Sparse Autoencoder (SAE). By optimizing sparse codes, YaPO produces disentangled, interpretable, and efficient steering directions. Empirically, we show that YaPO converges faster, achieves stronger performance, and exhibits improved training stability compared to dense steering baselines. Beyond cultural alignment, YaPO generalizes to a range of alignment-related behaviors, including hallucination, wealth-seeking, jailbreak, and power-seeking. Importantly, YaPO preserves general knowledge, with no measurable degradation on MMLU. Overall, our results show that YaPO provides a general recipe for efficient, stable, and fine-grained alignment of LLMs, with broad applications to controllability and domain adaptation. The associated code and data are publicly available\footnote{https://github.com/MBZUAI-Paris/YaPO}.