Owen-Shapley Policy Optimization (OSPO): A Principled RL Algorithm for Generative Search LLMs
作者: Abhijnan Nath, Alireza Bagheri Garakani, Tianchen Zhou, Fan Yang, Nikhil Krishnaswamy
分类: cs.AI
发布日期: 2026-01-13
💡 一句话要点
提出Owen-Shapley策略优化(OSPO),解决生成式搜索LLM中奖励稀疏和信用分配问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 奖励塑造 信用分配 Shapley值 个性化推荐 生成式搜索
📋 核心要点
- 现有强化学习方法在训练LLM进行个性化推荐时,面临奖励稀疏和信用分配难题,难以确定关键token。
- OSPO框架通过Shapley-Owen属性重新分配序列级别奖励,实现token级别的信用分配,无需额外的价值模型。
- 在Amazon ESCI和H&M Fashion数据集上的实验表明,OSPO优于现有基线方法,并具有更强的泛化能力。
📝 摘要(中文)
大型语言模型越来越多地通过强化学习进行训练,以用于个性化推荐任务,但像GRPO这样的标准方法依赖于稀疏的序列级别奖励,这会产生信用分配差距,从而模糊了哪些token驱动了成功。当模型必须从不明确的语言中推断潜在用户意图而没有ground truth标签时,这种差距尤其成问题,这种推理模式在预训练期间很少见到。我们引入了Owen-Shapley策略优化(OSPO),这是一个基于token对结果的边际贡献来重新分配序列级别优势的框架。与需要额外计算的基于价值模型的方法不同,OSPO通过Shapley-Owen属性采用基于势的奖励塑造,以分配段级别信用,同时保留最佳策略,直接从任务反馈中学习,而无需参数化价值模型。通过形成语义连贯单元(描述产品属性的短语或捕捉偏好的句子)的联盟,OSPO可以识别哪些响应部分驱动了性能。在Amazon ESCI和H&M Fashion数据集上的实验表明,相对于基线,OSPO具有持续的收益,并且在测试时对训练期间未见过的分布外检索器具有显著的鲁棒性。
🔬 方法详解
问题定义:现有基于强化学习的LLM训练方法,如GRPO,在处理个性化推荐任务时,依赖于稀疏的序列级别奖励。这种奖励机制导致信用分配问题,难以确定哪些token对最终结果贡献最大,尤其是在需要从不明确的用户输入中推断意图时,模型难以有效学习。
核心思路:OSPO的核心思想是利用Shapley-Owen值来评估每个token对最终奖励的边际贡献,并以此为基础重新分配序列级别的奖励。通过这种方式,OSPO能够将奖励细化到token级别,从而解决信用分配问题,并提高模型的学习效率。
技术框架:OSPO框架主要包含以下几个步骤:1) 使用LLM生成候选回复序列;2) 根据任务反馈计算序列级别的奖励;3) 使用Shapley-Owen值计算每个token对奖励的边际贡献;4) 基于token的贡献重新分配奖励,并使用策略梯度方法更新LLM的参数。该框架避免了使用额外的价值模型,直接从任务反馈中学习。
关键创新:OSPO的关键创新在于使用Shapley-Owen值进行奖励塑造,从而实现token级别的信用分配。与传统的基于价值模型的方法相比,OSPO无需训练额外的价值模型,降低了计算复杂度,并避免了价值模型带来的偏差。此外,OSPO通过形成语义连贯的单元(例如短语或句子)的联盟,更好地捕捉了token之间的依赖关系。
关键设计:OSPO的关键设计包括:1) 使用Shapley-Owen值作为奖励塑造的势函数;2) 定义合适的联盟结构,以捕捉token之间的语义关系;3) 使用策略梯度方法优化LLM的策略。具体而言,论文可能采用了某种特定的策略梯度算法(例如PPO或TRPO),并针对LLM的特点进行了调整。损失函数的设计需要考虑奖励的重新分配和策略的稳定性。
🖼️ 关键图片

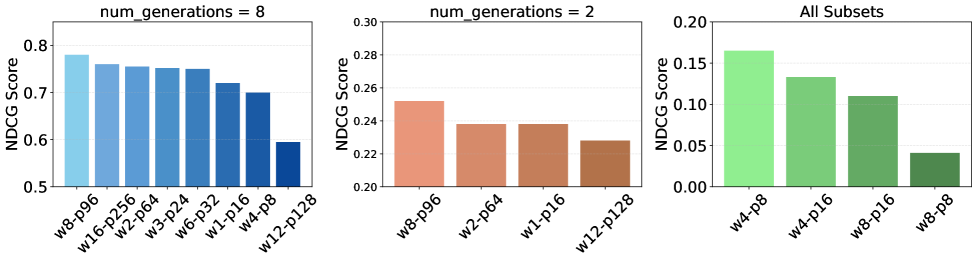
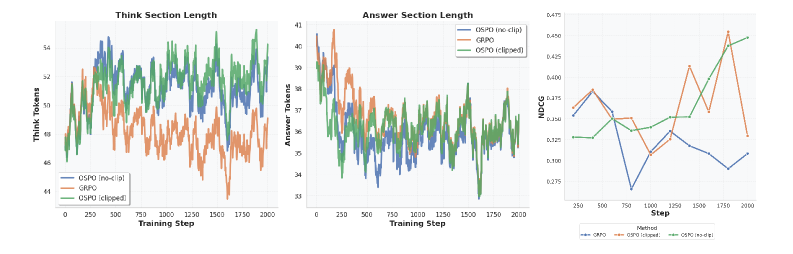
📊 实验亮点
实验结果表明,OSPO在Amazon ESCI和H&M Fashion数据集上均优于基线方法,取得了显著的性能提升。更重要的是,OSPO在测试时对训练期间未见过的分布外检索器表现出更强的鲁棒性,表明其具有更好的泛化能力。这些结果验证了OSPO在解决奖励稀疏和信用分配问题方面的有效性。
🎯 应用场景
OSPO可应用于各种生成式搜索和推荐系统,尤其是在需要从用户不明确的语言输入中推断意图的场景下。例如,它可以用于电商平台的个性化产品推荐、智能客服的对话生成以及搜索引擎的查询理解等领域。该方法能够提高推荐的准确性和用户满意度,并提升模型的泛化能力。
📄 摘要(原文)
Large language models are increasingly trained via reinforcement learning for personalized recommendation tasks, but standard methods like GRPO rely on sparse, sequence-level rewards that create a credit assignment gap, obscuring which tokens drive success. This gap is especially problematic when models must infer latent user intent from under-specified language without ground truth labels, a reasoning pattern rarely seen during pretraining. We introduce Owen-Shapley Policy Optimization (OSPO), a framework that redistributes sequence-level advantages based on tokens' marginal contributions to outcomes. Unlike value-model-based methods requiring additional computation, OSPO employs potential-based reward shaping via Shapley-Owen attributions to assign segment-level credit while preserving the optimal policy, learning directly from task feedback without parametric value models. By forming coalitions of semantically coherent units (phrases describing product attributes or sentences capturing preferences), OSPO identifies which response parts drive performance. Experiments on Amazon ESCI and H&M Fashion datasets show consistent gains over baselines, with notable test-time robustness to out-of-distribution retrievers unseen during training.