Large Artificial Intelligence Model Guided Deep Reinforcement Learning for Resource Allocation in Non Terrestrial Networks
作者: Abdikarim Mohamed Ibrahim, Rosdiadee Nordin
分类: cs.AI, eess.SY
发布日期: 2026-01-13
💡 一句话要点
提出基于大模型引导的深度强化学习方法,用于非地面网络资源分配。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 非地面网络 资源分配 深度强化学习 大型语言模型 智能优化
📋 核心要点
- 现有非地面网络资源分配方法泛化性不足,需要大量特定任务训练。
- 利用大型语言模型(LLM)作为高级协调器,生成文本指导,塑造DRL代理的奖励函数。
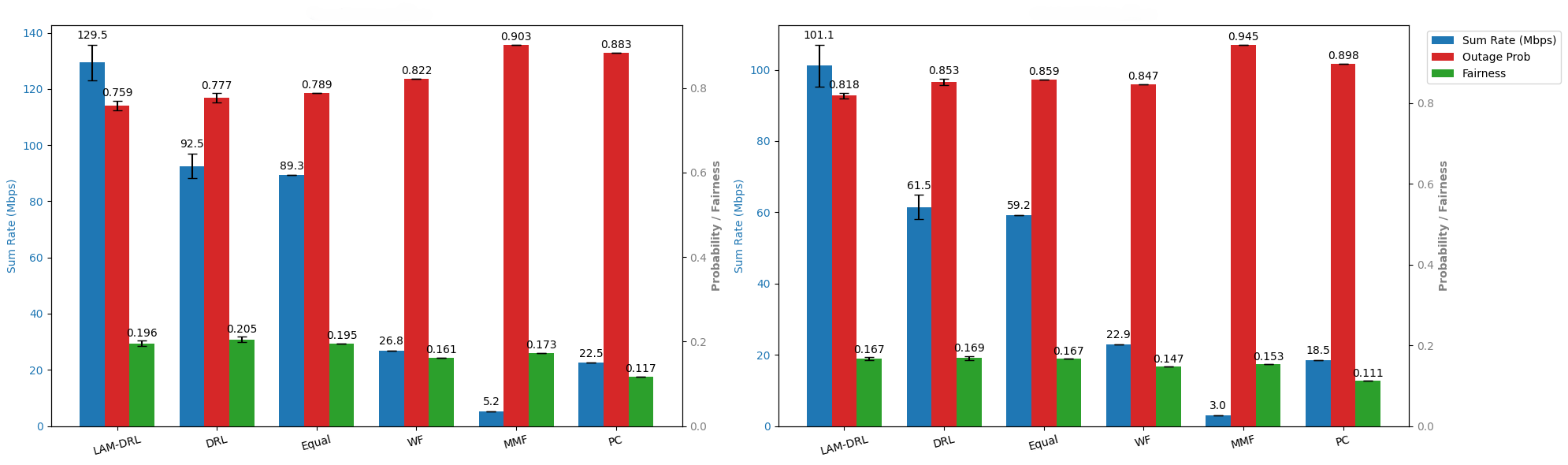
- 实验表明,所提出的LAM-DRL方法在吞吐量、公平性和中断概率方面显著优于传统DRL和启发式方法。
📝 摘要(中文)
本文提出了一种由大型语言模型(LLM)引导的深度强化学习(DRL)代理,用于非地面网络(NTN)中的资源分配。大型人工智能模型(LAM)已被提议应用于NTN,由于其强大的泛化能力和减少的特定任务训练,可以提供更好的性能。该LLM作为高级协调器,生成文本指导,从而在训练期间塑造DRL代理的奖励。结果表明,与启发式方法相比,在吞吐量、公平性和中断概率方面,LAM-DRL在正常天气情况下优于传统DRL 40%,在极端天气情况下优于传统DRL 64%。
🔬 方法详解
问题定义:论文旨在解决非地面网络(NTN)中资源分配的优化问题。现有方法,如传统DRL和启发式算法,在面对复杂多变的网络环境(如不同的天气条件)时,泛化能力较弱,需要针对特定场景进行大量训练,效率较低。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大泛化能力和知识储备,将其作为DRL代理的高级指导者。LLM能够根据当前的网络状态和目标,生成文本形式的指导信息,这些信息被用来调整DRL代理的奖励函数,从而引导代理学习更有效的资源分配策略。
技术框架:整体框架包含两个主要模块:LLM指导模块和DRL代理模块。LLM指导模块接收网络状态信息作为输入,输出文本形式的指导信息。DRL代理模块则是一个标准的DRL框架,但其奖励函数会受到LLM输出的文本指导的影响。具体流程是:首先,LLM根据当前网络状态生成指导文本;然后,DRL代理根据该指导文本和环境反馈,采取行动;最后,环境给出奖励,该奖励会被LLM的指导文本调整,用于更新DRL代理的策略。
关键创新:最重要的创新点在于将大型语言模型(LLM)引入到DRL框架中,利用LLM的知识和推理能力来指导DRL代理的训练。与传统的DRL方法相比,该方法能够更好地适应复杂多变的网络环境,提高资源分配的效率和公平性。本质区别在于,传统DRL依赖于预定义的奖励函数,而LAM-DRL的奖励函数是动态变化的,由LLM根据当前状态进行调整。
关键设计:论文中没有明确给出关键参数设置、损失函数和网络结构的具体细节,这些信息属于未知内容。但是,可以推测,LLM的prompt设计和DRL代理的奖励函数设计是两个关键的设计点。LLM的prompt需要能够有效地引导LLM生成有用的指导文本,而DRL代理的奖励函数需要能够有效地将LLM的指导文本转化为可学习的信号。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在正常天气情况下,LAM-DRL在吞吐量、公平性和中断概率方面优于传统DRL 40%,在极端天气情况下优于传统DRL 64%。这表明LAM-DRL方法具有更强的鲁棒性和泛化能力,能够更好地适应复杂多变的网络环境。
🎯 应用场景
该研究成果可应用于各种非地面网络场景,例如卫星通信、无人机网络等。通过利用大型语言模型的指导,可以实现更智能、更高效的资源分配,提高网络性能,改善用户体验。未来,该方法有望扩展到其他无线通信领域,例如蜂窝网络、物联网等,为构建智能化的无线通信系统提供新的思路。
📄 摘要(原文)
Large AI Model (LAM) have been proposed to applications of Non-Terrestrial Networks (NTN), that offer better performance with its great generalization and reduced task specific trainings. In this paper, we propose a Deep Reinforcement Learning (DRL) agent that is guided by a Large Language Model (LLM). The LLM operates as a high level coordinator that generates textual guidance that shape the reward of the DRL agent during training. The results show that the LAM-DRL outperforms the traditional DRL by 40% in nominal weather scenarios and 64% in extreme weather scenarios compared to heuristics in terms of throughput, fairness, and outage probability.