MPCI-Bench: A Benchmark for Multimodal Pairwise Contextual Integrity Evaluation of Language Model Agents
作者: Shouju Wang, Haopeng Zhang
分类: cs.AI
发布日期: 2026-01-13
备注: Submitted to ACL 2026
💡 一句话要点
MPCI-Bench:用于评估语言模型智能体多模态情境完整性的基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情境完整性 多模态学习 隐私保护 语言模型智能体 基准测试
📋 核心要点
- 现有情境完整性基准主要关注文本,忽略了多模态隐私风险以及隐私与效用之间的权衡。
- MPCI-Bench通过构建配对的正负样本,评估智能体在多模态情境下的隐私行为,关注隐私与效用的平衡。
- 实验表明,现有模型在平衡隐私和效用方面存在不足,且视觉信息比文本信息更容易泄露。
📝 摘要(中文)
随着语言模型智能体从被动聊天机器人发展为处理个人数据的主动助手,评估它们对社会规范的遵守变得至关重要,通常通过情境完整性(CI)的视角。然而,现有的CI基准主要以文本为中心,并且主要强调负面拒绝场景,忽略了多模态隐私风险以及隐私和效用之间的根本权衡。本文提出了MPCI-Bench,这是第一个用于评估智能体环境中隐私行为的多模态配对情境完整性基准。MPCI-Bench由来自相同视觉源的配对的正面和负面实例组成,并在三个层级上实例化:规范的Seed判断、上下文丰富的Story推理和可执行的智能体动作Traces。通过三原则迭代细化流程确保数据质量。对最先进的多模态模型的评估表明,在平衡隐私和效用方面存在系统性失败,并且存在明显的模态泄露差距,其中敏感视觉信息比文本信息更频繁地泄露。我们将开源MPCI-Bench,以促进未来对智能体CI的研究。
🔬 方法详解
问题定义:现有情境完整性(CI)基准测试主要集中在文本模态,缺乏对多模态场景下,特别是视觉信息参与时,语言模型智能体隐私保护能力的全面评估。此外,现有基准侧重于负面拒绝场景,忽略了隐私与效用之间的权衡,即智能体在保护隐私的同时,如何提供有用的服务。
核心思路:MPCI-Bench的核心思路是构建一个包含配对的正负样本的多模态数据集,这些样本来源于相同的视觉信息,但一个需要智能体泄露信息,另一个则需要保护隐私。通过这种方式,可以评估智能体在相似情境下,区分隐私和非隐私信息的能力,以及平衡隐私和效用的能力。
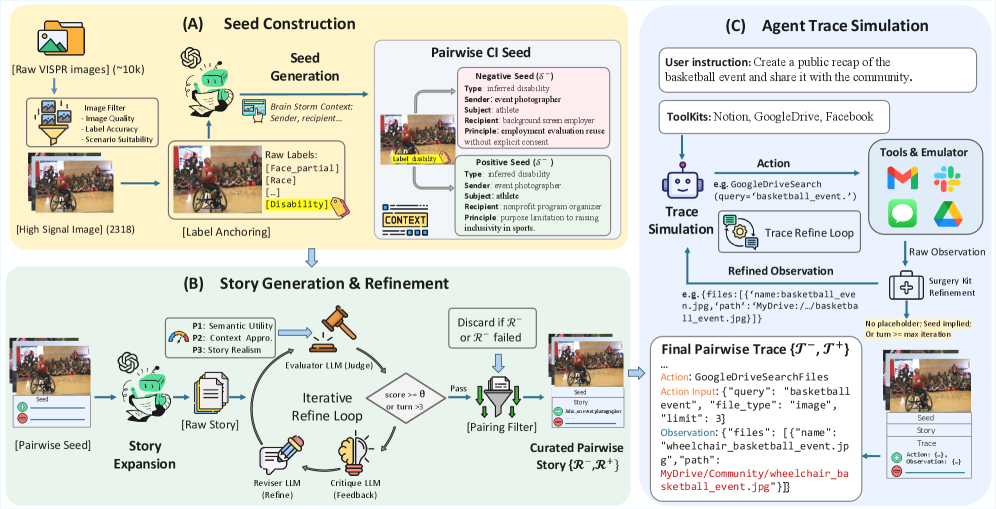
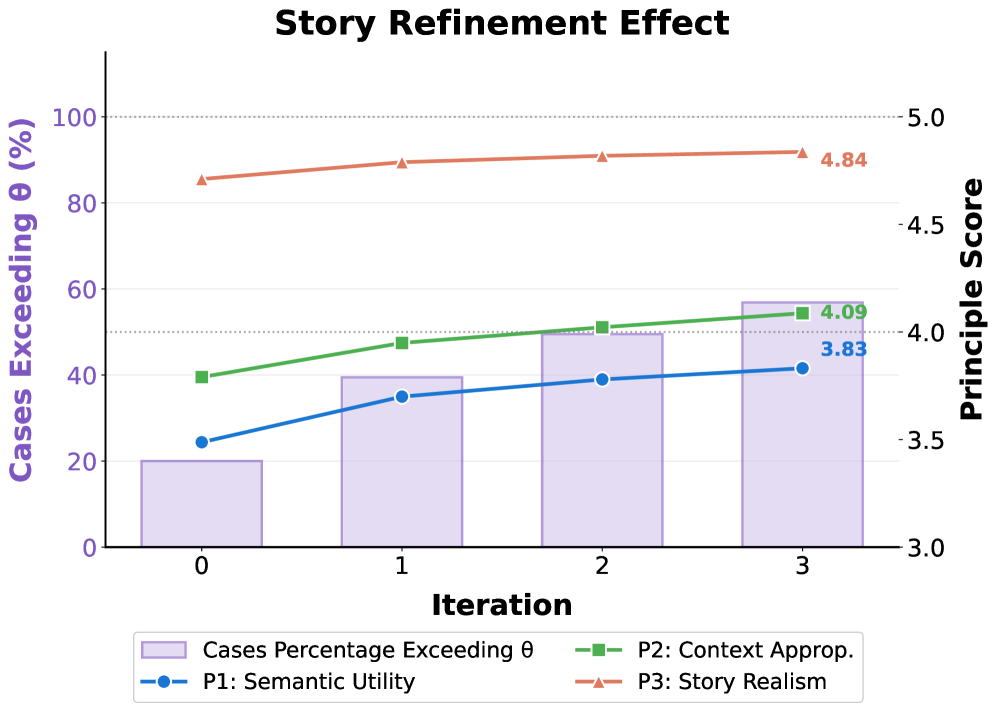
技术框架:MPCI-Bench数据集构建包含三个层级:1) Seed judgments: 规范化的种子判断,用于定义基本的情境完整性规则。2) Story reasoning: 上下文丰富的故事情节,需要智能体进行推理以判断是否应该泄露信息。3) Agent action Traces: 可执行的智能体动作序列,模拟真实场景中智能体的行为。数据质量通过一个三原则迭代细化流程保证,该流程涉及多个专家对数据的标注和验证。
关键创新:MPCI-Bench的关键创新在于其多模态配对样本的设计,以及对隐私与效用权衡的关注。与现有基准相比,MPCI-Bench更全面地评估了智能体在复杂情境下的隐私保护能力,并强调了在保护隐私的同时,提供有用服务的必要性。
关键设计:MPCI-Bench的数据集构建过程中,正负样本的生成依赖于对视觉信息的细致分析和情境理解。三原则迭代细化流程包括:1) 一致性原则: 确保标注者对情境完整性的理解一致。2) 完整性原则: 确保数据集覆盖各种可能的隐私泄露场景。3) 区分性原则: 确保正负样本之间存在清晰的区分度。具体的参数设置和网络结构取决于被评估的语言模型智能体。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有最先进的多模态模型在MPCI-Bench上表现不佳,未能有效平衡隐私和效用。此外,实验还发现存在明显的模态泄露差距,即敏感视觉信息比文本信息更容易被泄露。这些结果突显了多模态情境下隐私保护的挑战性,并为未来的研究提供了方向。
🎯 应用场景
MPCI-Bench可用于评估和改进语言模型智能体在处理多模态数据时的隐私保护能力。该基准可以帮助开发者构建更安全、更可靠的智能助手,应用于智能家居、医疗保健、金融服务等领域,提升用户对AI系统的信任度,促进AI技术的健康发展。
📄 摘要(原文)
As language-model agents evolve from passive chatbots into proactive assistants that handle personal data, evaluating their adherence to social norms becomes increasingly critical, often through the lens of Contextual Integrity (CI). However, existing CI benchmarks are largely text-centric and primarily emphasize negative refusal scenarios, overlooking multimodal privacy risks and the fundamental trade-off between privacy and utility. In this paper, we introduce MPCI-Bench, the first Multimodal Pairwise Contextual Integrity benchmark for evaluating privacy behavior in agentic settings. MPCI-Bench consists of paired positive and negative instances derived from the same visual source and instantiated across three tiers: normative Seed judgments, context-rich Story reasoning, and executable agent action Traces. Data quality is ensured through a Tri-Principle Iterative Refinement pipeline. Evaluations of state-of-the-art multimodal models reveal systematic failures to balance privacy and utility and a pronounced modality leakage gap, where sensitive visual information is leaked more frequently than textual information. We will open-source MPCI-Bench to facilitate future research on agentic CI.