The Agent's First Day: Benchmarking Learning, Exploration, and Scheduling in the Workplace Scenarios
作者: Daocheng Fu, Jianbiao Mei, Rong Wu, Xuemeng Yang, Jia Xu, Ding Wang, Pinlong Cai, Yong Liu, Licheng Wen, Botian Shi
分类: cs.AI
发布日期: 2026-01-13
🔗 代码/项目: GITHUB
💡 一句话要点
提出EvoEnv动态评估环境,解决多模态大模型在工作场景中的学习、探索和调度问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大模型 动态环境 主动探索 持续学习 任务调度 工作流程自动化 智能体评估
📋 核心要点
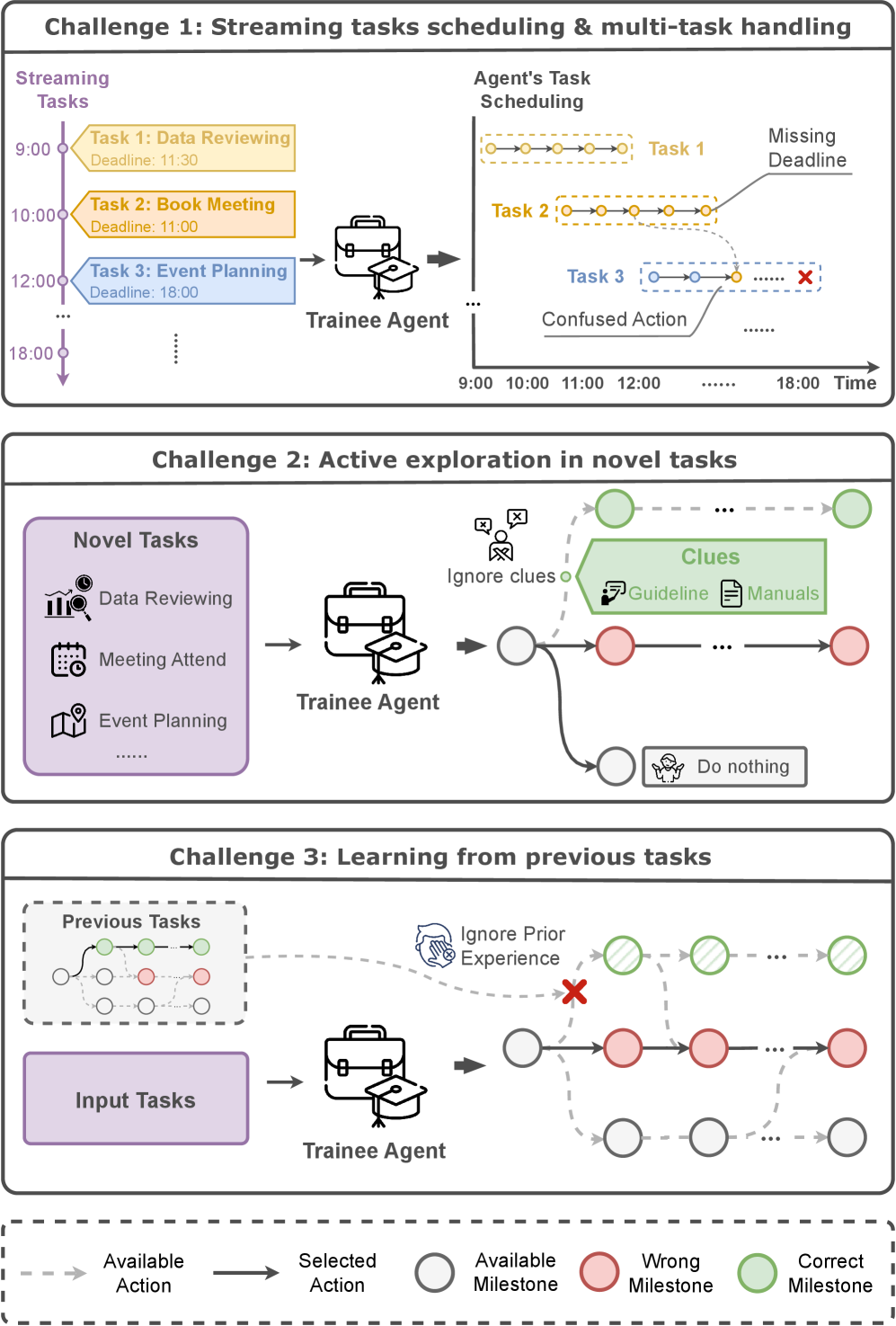
- 现有研究主要关注多模态大模型在静态环境中的性能上限,忽略了真实世界部署中动态任务调度、主动探索和持续学习的挑战。
- 论文提出了EvoEnv动态评估环境,模拟智能体在动态变化的工作场所场景中进行学习、探索和调度,更贴近实际应用。
- 实验表明,现有先进智能体在EvoEnv中面临主动探索和持续学习的挑战,验证了EvoEnv的有效性,并为未来研究指明方向。
📝 摘要(中文)
多模态大型语言模型(MLLM)的快速发展推动了工作流程自动化。然而,现有研究主要关注静态环境中的性能上限,忽略了随机真实世界部署的鲁棒性。我们确定了三个关键挑战:动态任务调度、不确定性下的主动探索以及从经验中持续学习。为了弥合这一差距,我们引入了EvoEnv,这是一个动态评估环境,模拟“实习生”智能体持续探索新环境。与传统基准不同,EvoEnv从三个维度评估智能体:(1)针对具有不同优先级的流式任务的上下文感知调度;(2)通过主动探索减少幻觉的谨慎信息获取;(3)通过从基于规则的动态生成任务中提取通用策略来实现持续进化。实验表明,最先进的智能体在动态环境中存在显著缺陷,尤其是在主动探索和持续学习方面。我们的工作建立了一个评估智能体可靠性的框架,将评估从静态测试转变为面向实际生产的场景。我们的代码可在https://github.com/KnowledgeXLab/EvoEnv获取。
🔬 方法详解
问题定义:现有方法主要在静态环境中评估多模态大模型的性能,忽略了真实工作场景的动态性和不确定性。这导致模型在实际部署中难以应对动态任务调度、信息不确定性以及持续学习的需求,从而影响其鲁棒性和可靠性。现有方法缺乏对智能体在动态环境中主动探索和持续学习能力的有效评估。
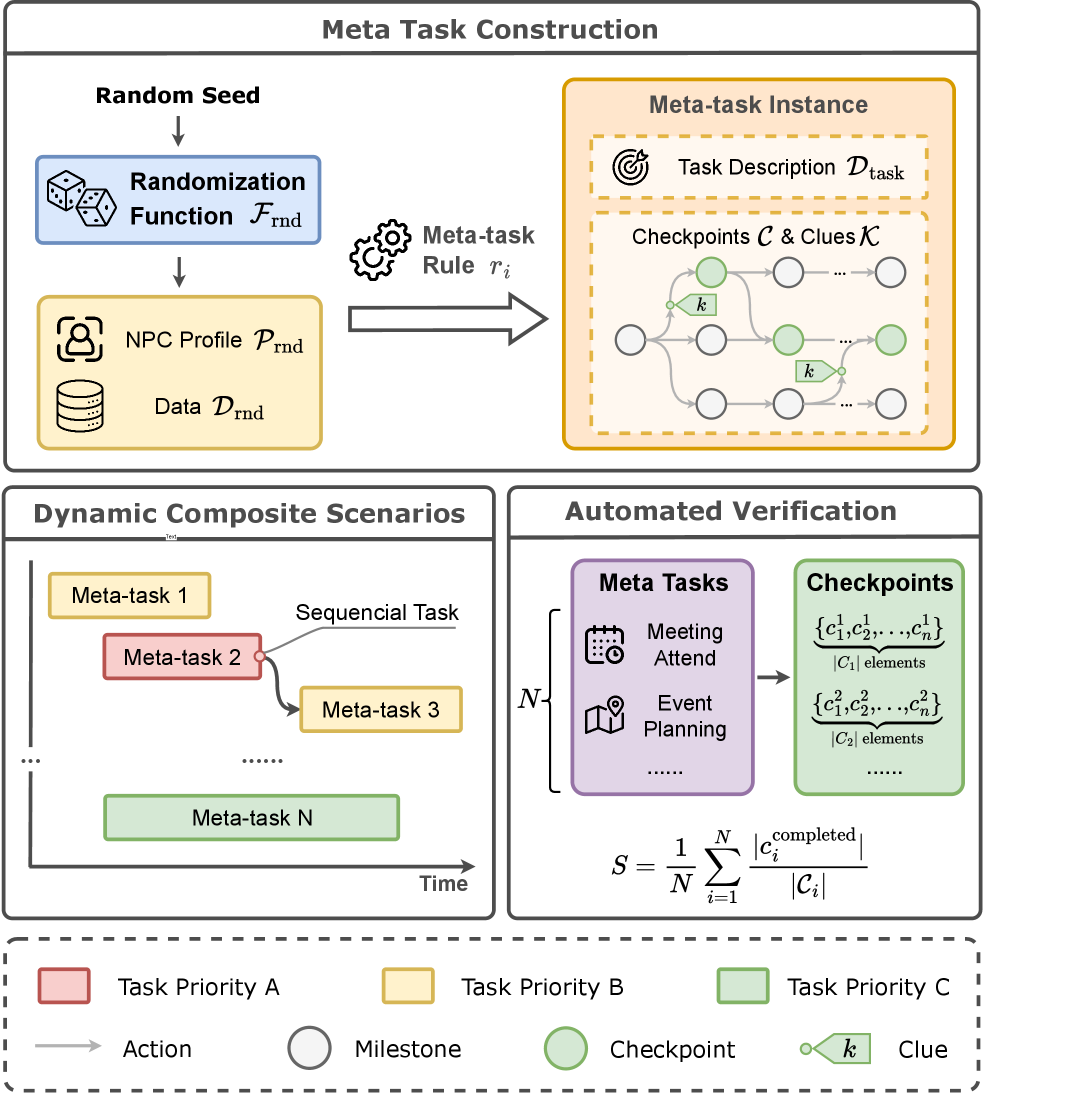
核心思路:论文的核心思路是构建一个动态评估环境EvoEnv,模拟真实工作场所场景,使智能体能够在一个动态变化的环境中进行学习、探索和调度。通过动态生成任务、引入不确定性和模拟持续学习过程,EvoEnv能够更全面地评估智能体在实际应用中的性能和可靠性。
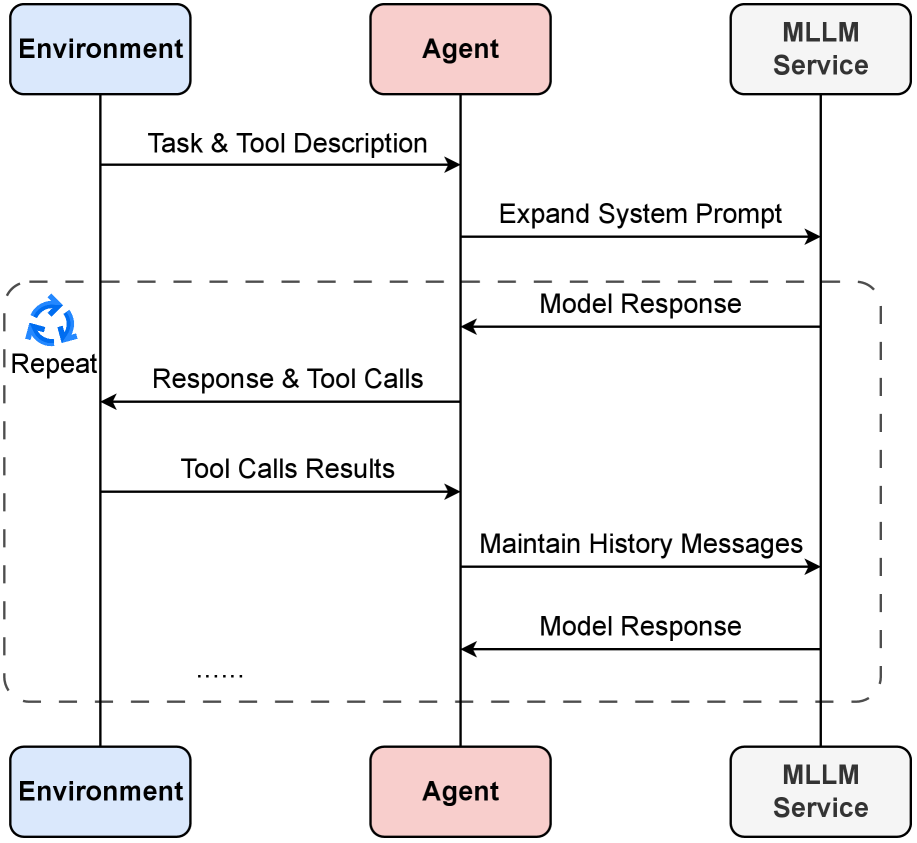
技术框架:EvoEnv包含以下主要模块:1) 任务生成器:动态生成具有不同优先级和依赖关系的流式任务;2) 环境模拟器:模拟真实工作场所场景,引入不确定性和噪声;3) 智能体接口:提供与智能体交互的接口,包括观察、行动和奖励;4) 评估指标:从上下文感知调度、主动探索和持续学习三个维度评估智能体的性能。
关键创新:EvoEnv的关键创新在于其动态性和真实性。与传统的静态基准相比,EvoEnv能够更真实地模拟真实工作场所场景,从而更全面地评估智能体在实际应用中的性能和可靠性。此外,EvoEnv还引入了主动探索和持续学习的评估指标,能够更准确地衡量智能体在动态环境中的适应能力。
关键设计:EvoEnv的关键设计包括:1) 任务生成器的参数设置,例如任务数量、优先级范围和依赖关系;2) 环境模拟器的噪声模型,例如传感器噪声和执行器误差;3) 奖励函数的设计,鼓励智能体进行主动探索和持续学习;4) 评估指标的定义,例如调度效率、信息获取准确性和学习速度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有最先进的智能体在EvoEnv中面临显著挑战,尤其是在主动探索和持续学习方面。例如,在主动探索任务中,智能体的性能比静态环境下降了20%。这表明现有智能体在动态环境中的适应能力仍然不足,需要进一步的研究和改进。
🎯 应用场景
该研究成果可应用于各种需要智能体在动态环境中进行学习、探索和调度的场景,例如智能制造、智能物流、智能仓储等。通过EvoEnv的评估,可以更好地选择和优化智能体,提高工作效率和可靠性,降低运营成本,并加速智能体的实际部署。
📄 摘要(原文)
The rapid evolution of Multi-modal Large Language Models (MLLMs) has advanced workflow automation; however, existing research mainly targets performance upper bounds in static environments, overlooking robustness for stochastic real-world deployment. We identify three key challenges: dynamic task scheduling, active exploration under uncertainty, and continuous learning from experience. To bridge this gap, we introduce \method{}, a dynamic evaluation environment that simulates a "trainee" agent continuously exploring a novel setting. Unlike traditional benchmarks, \method{} evaluates agents along three dimensions: (1) context-aware scheduling for streaming tasks with varying priorities; (2) prudent information acquisition to reduce hallucination via active exploration; and (3) continuous evolution by distilling generalized strategies from rule-based, dynamically generated tasks. Experiments show that cutting-edge agents have significant deficiencies in dynamic environments, especially in active exploration and continual learning. Our work establishes a framework for assessing agent reliability, shifting evaluation from static tests to realistic, production-oriented scenarios. Our codes are available at https://github.com/KnowledgeXLab/EvoEnv