Enriching Semantic Profiles into Knowledge Graph for Recommender Systems Using Large Language Models
作者: Seokho Ahn, Sungbok Shin, Young-Duk Seo
分类: cs.IR, cs.AI, cs.LG
发布日期: 2026-01-13
备注: Accepted at KDD 2026
💡 一句话要点
提出SPiKE模型,利用大语言模型增强知识图谱推荐系统中的语义表示。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推荐系统 知识图谱 大型语言模型 用户画像 语义表示
📋 核心要点
- 现有推荐系统在构建和利用用户画像方面存在不足,缺乏统一的方法来有效捕获用户偏好。
- SPiKE模型利用LLM生成实体语义画像,并将其融入知识图谱,从而增强推荐系统的表示能力。
- 实验结果表明,SPiKE在真实数据集上显著优于现有的基于知识图谱和大型语言模型的推荐系统。
📝 摘要(中文)
为了提升推荐质量,丰富且信息量大的用户偏好建模至关重要。然而,如何构建和利用这些用户画像尚未达成共识。本文从四个维度重新审视了推荐系统中基于用户画像的方法:1) 知识库,2) 偏好指示器,3) 影响范围,4) 主题。我们认为,大型语言模型(LLM)擅长从各种知识源中提取压缩的理由,而知识图谱(KG)更适合传播这些用户画像以扩大其影响范围。基于此,我们提出了一种新的推荐模型SPiKE。SPiKE包含三个核心组件:i) 实体画像生成,使用LLM为所有KG实体生成语义画像;ii) 画像感知的KG聚合,将这些画像集成到KG中;iii) 成对画像偏好匹配,在训练期间对齐基于LLM和KG的表示。实验表明,SPiKE在真实场景中始终优于最先进的基于KG和LLM的推荐系统。
🔬 方法详解
问题定义:现有推荐系统难以充分利用知识图谱中的实体信息,用户画像构建不够丰富,无法准确捕捉用户偏好。同时,如何有效融合大型语言模型的推理能力和知识图谱的结构化信息也是一个挑战。
核心思路:利用大型语言模型从知识图谱的实体中提取语义信息,生成实体画像,然后将这些画像融入知识图谱中,从而增强知识图谱的表示能力。通过对齐LLM和KG的表示,实现二者的优势互补。
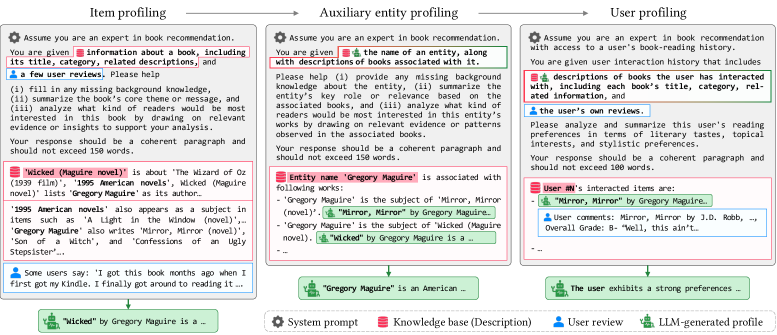
技术框架:SPiKE模型包含三个主要模块:1) 实体画像生成:使用LLM为知识图谱中的每个实体生成语义画像。2) 画像感知的KG聚合:将生成的实体画像融入知识图谱中,增强知识图谱的表示能力。3) 成对画像偏好匹配:在训练过程中,对齐基于LLM和KG的表示,使得模型能够同时利用LLM的推理能力和KG的结构化信息。
关键创新:SPiKE的关键创新在于将大型语言模型生成的语义画像融入知识图谱,从而增强了知识图谱的表示能力。与现有方法相比,SPiKE能够更有效地利用LLM的推理能力和KG的结构化信息,从而提升推荐性能。
关键设计:实体画像生成模块使用预训练的LLM(具体型号未知)对知识图谱中的实体进行编码,生成语义向量表示。画像感知的KG聚合模块使用图神经网络(GNN,具体类型未知)对知识图谱进行编码,并将实体画像融入GNN的节点表示中。成对画像偏好匹配模块使用对比学习损失函数,对齐LLM和KG的表示。
🖼️ 关键图片

📊 实验亮点
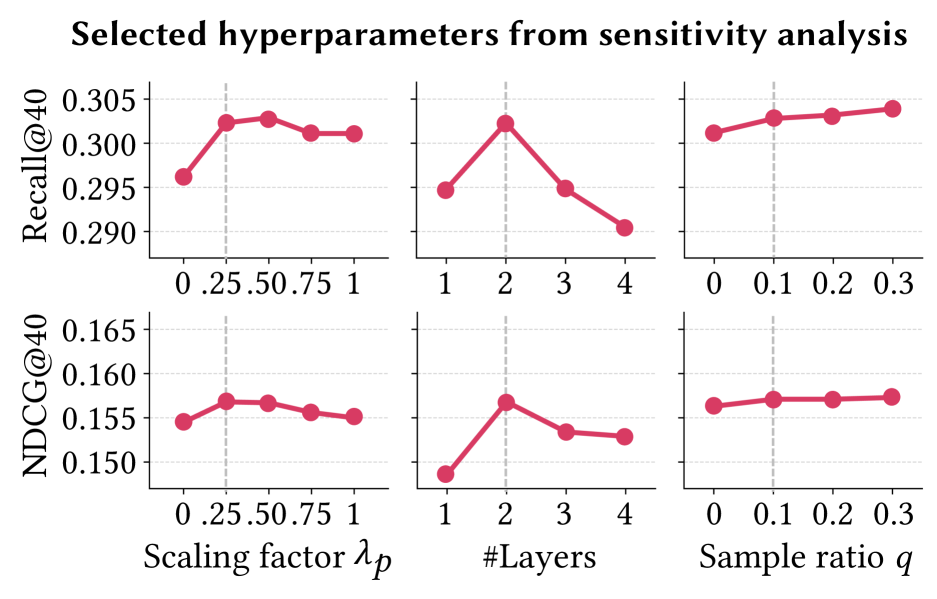
SPiKE模型在真实数据集上进行了实验,结果表明,SPiKE显著优于现有的基于知识图谱和大型语言模型的推荐系统。具体性能提升数据未知,但摘要强调了“consistently outperforms state-of-the-art”表明提升具有统计显著性。
🎯 应用场景
该研究成果可应用于各种推荐系统,例如电商推荐、电影推荐、音乐推荐等。通过更准确地捕捉用户偏好,可以显著提升推荐系统的性能,提高用户满意度和平台收益。未来,该方法还可以扩展到其他知识图谱相关的任务中,例如知识图谱补全、实体链接等。
📄 摘要(原文)
Rich and informative profiling to capture user preferences is essential for improving recommendation quality. However, there is still no consensus on how best to construct and utilize such profiles. To address this, we revisit recent profiling-based approaches in recommender systems along four dimensions: 1) knowledge base, 2) preference indicator, 3) impact range, and 4) subject. We argue that large language models (LLMs) are effective at extracting compressed rationales from diverse knowledge sources, while knowledge graphs (KGs) are better suited for propagating these profiles to extend their reach. Building on this insight, we propose a new recommendation model, called SPiKE. SPiKE consists of three core components: i) Entity profile generation, which uses LLMs to generate semantic profiles for all KG entities; ii) Profile-aware KG aggregation, which integrates these profiles into the KG; and iii) Pairwise profile preference matching, which aligns LLM- and KG-based representations during training. In experiments, we demonstrate that SPiKE consistently outperforms state-of-the-art KG- and LLM-based recommenders in real-world settings.