MirrorBench: An Extensible Framework to Evaluate User-Proxy Agents for Human-Likeness
作者: Ashutosh Hathidara, Julien Yu, Vaishali Senthil, Sebastian Schreiber, Anil Babu Ankisettipalli
分类: cs.AI, cs.LG
发布日期: 2026-01-13
🔗 代码/项目: GITHUB
💡 一句话要点
提出MirrorBench框架,用于评估用户代理生成类人对话的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 用户代理评估 人机对话 大型语言模型 基准测试框架 类人性 对话系统 用户行为模拟
📋 核心要点
- 现有方法直接使用LLM扮演用户进行对话,但生成内容往往冗长且不真实,缺乏对用户代理类人性的有效评估。
- MirrorBench框架通过解耦下游任务成功率,专注于评估用户代理生成类人对话语句的能力,提供更纯粹的类人性评估。
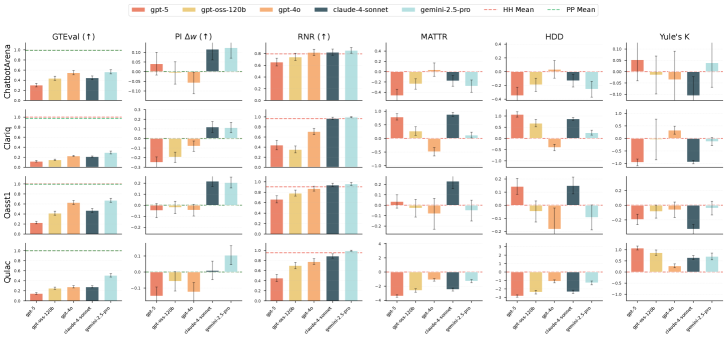
- 实验结果表明,MirrorBench揭示了现有用户代理与真实人类用户之间的差距,并提供了方差感知的评估结果。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被用作人类模拟器,用于评估对话系统和生成微调数据。然而,简单的“扮演用户”提示通常会产生冗长、不切实际的语句,这突显了对所谓用户代理进行原则性评估的需求。我们提出了MIRRORBENCH,这是一个可重现、可扩展的基准测试框架,它仅根据用户代理在各种对话任务中生成类人用户语句的能力来评估它们,并明确地与下游任务的成功解耦。MIRRORBENCH具有模块化的执行引擎,带有类型化接口、元数据驱动的注册表、多后端支持、缓存和强大的可观察性。该系统支持可插拔的用户代理、数据集、任务和指标,使研究人员能够在统一的、方差感知的框架下评估任意模拟器。我们包括三个词汇多样性指标(MATTR、YULE'S K和HD-D)和三个基于LLM-judge的指标(GTEval、Pairwise Indistinguishability和Rubric-and-Reason)。在四个开放数据集上,MIRRORBENCH产生了方差感知的实验结果,并揭示了用户代理与真实人类用户之间的系统性差距。该框架是开源的,包括一个简单的命令行界面,用于运行实验、管理配置和缓存以及生成报告。该框架可在https://github.com/SAP/mirrorbench访问。
🔬 方法详解
问题定义:现有方法在评估用户代理时,往往将用户代理的性能与下游任务的成功率混淆,无法准确衡量用户代理生成类人对话的能力。简单的“扮演用户”提示会导致生成冗长、不真实的语句,缺乏有效的评估手段。
核心思路:MirrorBench的核心思路是将用户代理的评估与下游任务的成功率解耦,专注于评估用户代理生成类人对话语句的能力。通过提供一个可扩展的基准测试框架,研究人员可以更纯粹地评估用户代理的类人性,从而更好地理解和改进用户代理的设计。
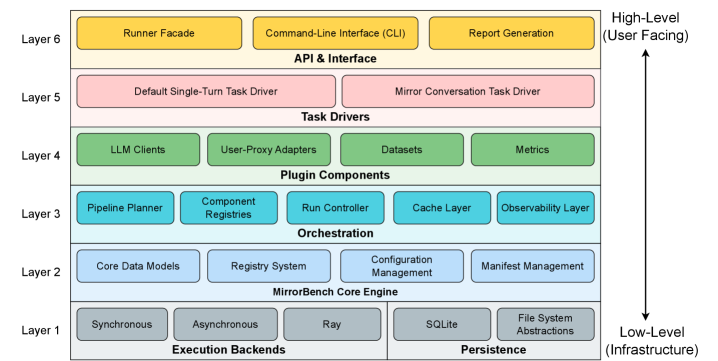
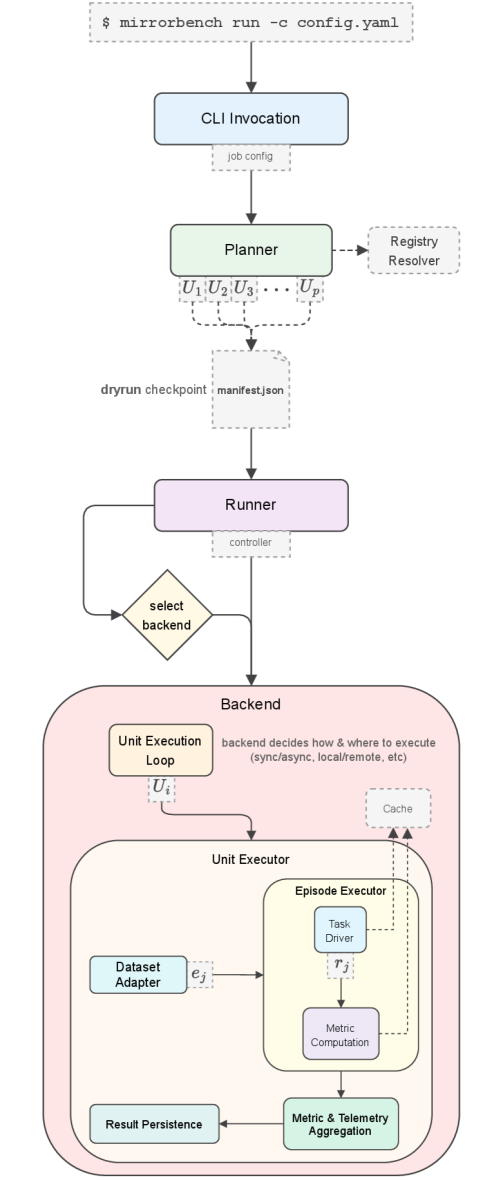
技术框架:MirrorBench框架包含以下主要模块:1) 模块化的执行引擎,带有类型化接口,用于管理和执行评估任务;2) 元数据驱动的注册表,用于管理可插拔的用户代理、数据集、任务和指标;3) 多后端支持,允许使用不同的LLM后端;4) 缓存机制,用于加速实验;5) 强大的可观察性,用于监控和调试实验。
关键创新:MirrorBench的关键创新在于其解耦评估方法,它允许研究人员专注于评估用户代理生成类人对话语句的能力,而无需考虑下游任务的成功率。此外,MirrorBench的可扩展性允许研究人员轻松地添加新的用户代理、数据集、任务和指标,从而促进了用户代理评估领域的研究。
关键设计:MirrorBench使用了多种指标来评估用户代理的类人性,包括三个词汇多样性指标(MATTR、YULE'S K和HD-D)和三个基于LLM-judge的指标(GTEval、Pairwise Indistinguishability和Rubric-and-Reason)。这些指标从不同的角度评估用户代理生成语句的质量,从而提供了更全面的评估结果。框架提供命令行界面,方便用户进行实验配置、缓存管理和报告生成。
🖼️ 关键图片
📊 实验亮点
MirrorBench在四个开放数据集上进行了实验,结果表明,现有用户代理与真实人类用户之间存在系统性差距。该框架提供了方差感知的评估结果,并揭示了不同用户代理在类人性方面的优缺点。实验结果验证了MirrorBench的有效性和实用性。
🎯 应用场景
MirrorBench可应用于对话系统开发、用户行为模拟、自动化测试等领域。通过评估和改进用户代理的类人性,可以提高对话系统的用户体验,更真实地模拟用户行为,并更有效地进行自动化测试。该框架有助于推动人机交互领域的发展。
📄 摘要(原文)
Large language models (LLMs) are increasingly used as human simulators, both for evaluating conversational systems and for generating fine-tuning data. However, naive "act-as-a-user" prompting often yields verbose, unrealistic utterances, underscoring the need for principled evaluation of so-called user proxy agents. We present MIRRORBENCH, a reproducible, extensible benchmarking framework that evaluates user proxies solely on their ability to produce human-like user utterances across diverse conversational tasks, explicitly decoupled from downstream task success. MIRRORBENCH features a modular execution engine with typed interfaces, metadata-driven registries, multi-backend support, caching, and robust observability. The system supports pluggable user proxies, datasets, tasks, and metrics, enabling researchers to evaluate arbitrary simulators under a uniform, variance-aware harness. We include three lexical-diversity metrics (MATTR, YULE'S K, and HD-D) and three LLM-judge-based metrics (GTEval, Pairwise Indistinguishability, and Rubric-and-Reason). Across four open datasets, MIRRORBENCH yields variance-aware results and reveals systematic gaps between user proxies and real human users. The framework is open source and includes a simple command-line interface for running experiments, managing configurations and caching, and generating reports. The framework can be accessed at https://github.com/SAP/mirrorbench.