OpenTinker: Separating Concerns in Agentic Reinforcement Learning
作者: Siqi Zhu, Jiaxuan You
分类: cs.AI, cs.DC
发布日期: 2026-01-12
💡 一句话要点
OpenTinker:面向Agent强化学习的关注点分离基础设施
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 Agent 关注点分离 模块化 资源调度 多Agent训练
📋 核心要点
- 现有Agent强化学习系统通常是单体式,缺乏模块化和灵活性,难以适应不同的Agent和环境。
- OpenTinker通过关注点分离,将Agent学习系统分解为可组合的组件,实现算法设计、执行和交互的解耦。
- 实验表明,OpenTinker能够有效支持各种RL用例,并可扩展到多Agent训练,提升了Agent学习的效率和灵活性。
📝 摘要(中文)
OpenTinker是一个用于大型语言模型(LLM)Agent强化学习(RL)的基础设施,其核心在于算法设计、执行和Agent-环境交互之间的关注点分离。它没有采用单体式的端到端RL流程,而是将Agent学习系统分解为轻量级、可组合的组件,并具有清晰定义的抽象边界。用户可以指定Agent、环境和交互协议,而推理和训练则委托给托管的执行运行时。OpenTinker引入了一个集中式调度器,用于管理训练和推理工作负载,包括基于LoRA的和全参数RL、监督微调和推理,并共享资源。此外,论文还讨论了将OpenTinker扩展到多Agent训练的设计原则。最后,论文展示了一系列RL用例,证明了该框架在实际Agent学习场景中的有效性。
🔬 方法详解
问题定义:现有Agent强化学习方法通常采用端到端的单体式架构,算法设计、执行和Agent-环境交互紧密耦合,导致系统难以维护、扩展和复用。针对不同的Agent和环境,需要重新设计和实现整个RL流程,开发成本高昂。此外,资源管理和调度也缺乏灵活性,难以充分利用计算资源。
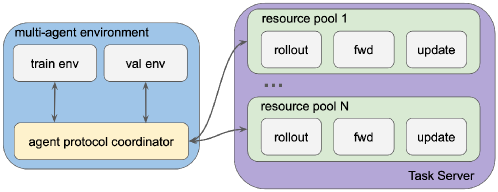
核心思路:OpenTinker的核心思路是将Agent强化学习系统分解为多个独立的、可组合的组件,每个组件负责特定的功能,例如Agent定义、环境定义、交互协议、训练算法和推理引擎。通过清晰定义的抽象边界,实现组件之间的解耦,从而提高系统的模块化、灵活性和可复用性。用户可以根据需要选择和组合不同的组件,快速构建定制化的Agent学习系统。
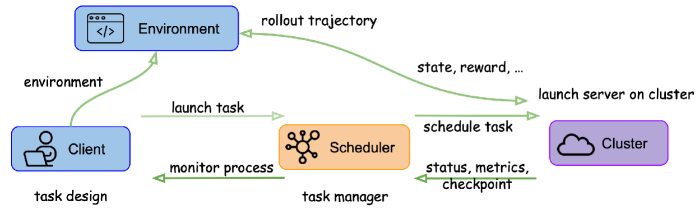
技术框架:OpenTinker的整体架构包括以下几个主要模块:Agent定义模块,用于定义Agent的行为策略和状态表示;环境定义模块,用于定义Agent所处的环境和交互规则;交互协议模块,用于定义Agent与环境之间的交互方式;执行运行时,负责执行Agent的训练和推理过程;集中式调度器,用于管理训练和推理工作负载,并进行资源调度。用户通过配置Agent、环境和交互协议,将训练和推理任务提交给执行运行时,由集中式调度器进行调度和管理。
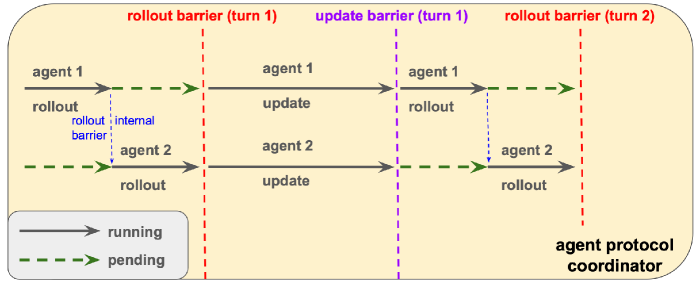
关键创新:OpenTinker最重要的技术创新在于关注点分离的设计理念,将Agent强化学习系统分解为多个独立的、可组合的组件,实现了算法设计、执行和Agent-环境交互的解耦。这种设计理念使得系统更加模块化、灵活和可复用,降低了开发成本,提高了开发效率。此外,集中式调度器的引入,实现了对训练和推理工作负载的统一管理和资源调度,提高了资源利用率。
关键设计:OpenTinker的关键设计包括:清晰定义的抽象边界,确保组件之间的解耦;可扩展的组件接口,支持用户自定义Agent、环境和交互协议;灵活的资源调度策略,充分利用计算资源;支持LoRA和全参数RL、监督微调和推理等多种训练方式。
🖼️ 关键图片
📊 实验亮点
论文通过一系列RL用例,验证了OpenTinker的有效性。实验结果表明,OpenTinker能够支持各种Agent和环境,并可扩展到多Agent训练。此外,OpenTinker的集中式调度器能够有效管理训练和推理工作负载,提高资源利用率。具体的性能数据和对比基线在论文中进行了详细描述。
🎯 应用场景
OpenTinker可应用于各种Agent强化学习场景,例如游戏AI、机器人控制、自然语言处理和推荐系统。通过提供一个模块化、灵活和可复用的Agent学习平台,OpenTinker可以加速Agent的开发和部署,并促进Agent强化学习技术在各个领域的应用。
📄 摘要(原文)
We introduce OpenTinker, an infrastructure for reinforcement learning (RL) of large language model (LLM) agents built around a separation of concerns across algorithm design, execution, and agent-environment interaction. Rather than relying on monolithic, end-to-end RL pipelines, OpenTinker decomposes agentic learning systems into lightweight, composable components with clearly defined abstraction boundaries. Users specify agents, environments, and interaction protocols, while inference and training are delegated to a managed execution runtime. OpenTinker introduces a centralized scheduler for managing training and inference workloads, including LoRA-based and full-parameter RL, supervised fine-tuning, and inference, over shared resources. We further discuss design principles for extending OpenTinker to multi-agent training. Finally, we present a set of RL use cases that demonstrate the effectiveness of the framework in practical agentic learning scenarios.