Learning to Trust the Crowd: A Multi-Model Consensus Reasoning Engine for Large Language Models
作者: Pranav Kallem
分类: cs.AI, cs.CL, cs.LG
发布日期: 2026-01-12
💡 一句话要点
提出多模型共识推理引擎,提升大语言模型在实例层面的可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模型共识 大语言模型 可靠性 元学习 图神经网络
📋 核心要点
- 现有大语言模型在实例层面表现不稳定,存在幻觉、易出错和置信度校准差等问题。
- 提出多模型共识推理引擎,通过学习多个异构LLM的输出来判断哪个答案最可靠。
- 实验表明,该方法在多个基准测试中显著提高了准确率,降低了幻觉,提升了可靠性。
📝 摘要(中文)
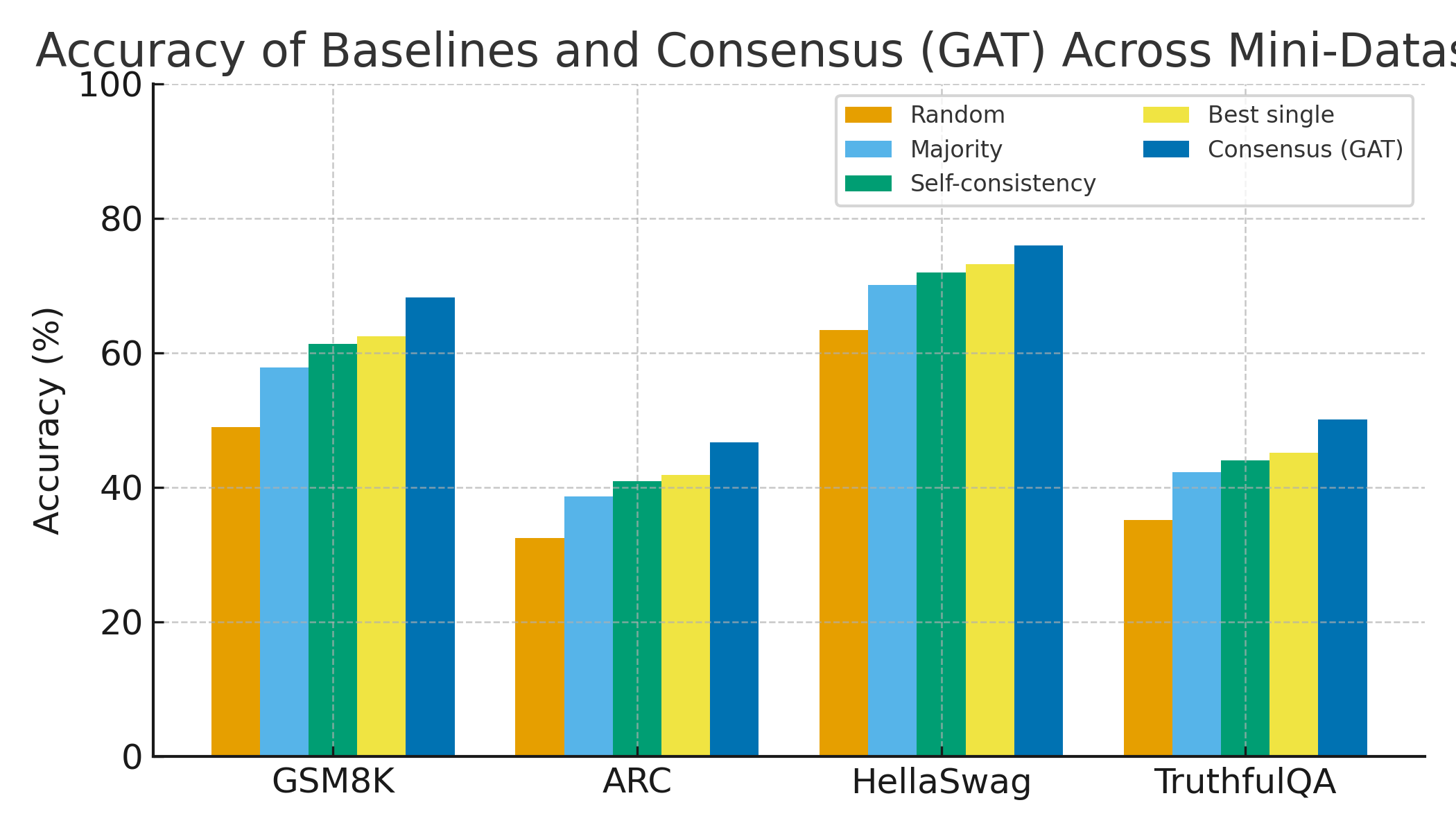
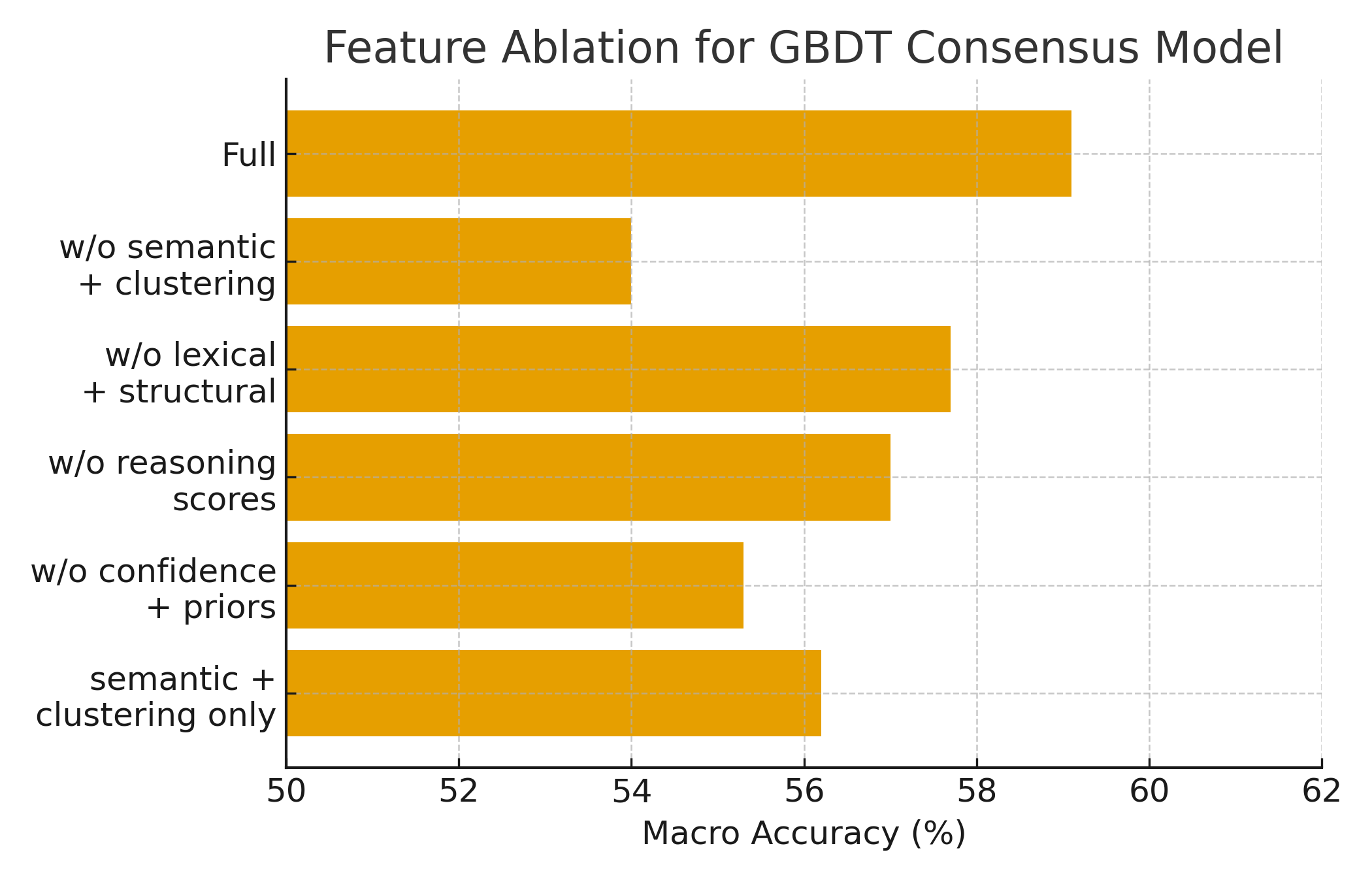
大型语言模型(LLMs)虽然平均性能强大,但在实例层面仍然不可靠,经常出现幻觉、脆弱的失败以及校准不良的置信度。本文从多模型共识的角度研究可靠性:给定来自多个异构LLM的响应,我们能否学习到哪个答案对于给定的查询最可能是正确的?我们引入了一个多模型共识推理引擎,它将LLM输出的集合作为监督元学习器的输入。该系统使用语义嵌入、成对相似性和聚类统计、词汇和结构线索、推理质量评分、置信度估计以及模型特定的先验,将自然语言响应映射到结构化特征,然后应用梯度提升树、列表排序和图神经网络来处理答案的相似性图。在使用三个开放权重LLM在GSM8K、ARC-Challenge、HellaSwag和TruthfulQA的紧凑、资源受限子集上进行评估后,我们最好的基于图注意力的共识模型在宏平均准确率上比最强的单个LLM提高了4.6个百分点,比多数投票提高了8.1个百分点,同时还产生了更低的Brier分数和更少的TruthfulQA幻觉。消融和特征重要性分析表明,语义一致性和聚类特征最具影响力,推理质量和模型先验特征提供了补充收益,这表明监督多模型共识是实现更可靠的LLM行为的实用途径,即使在适度的单机设置中也是如此。
🔬 方法详解
问题定义:现有的大语言模型虽然在平均水平上表现出色,但在具体实例上却经常出现错误,例如产生幻觉、对输入变化过于敏感、置信度评估不准确等。这些问题限制了它们在实际应用中的可靠性。论文旨在解决如何利用多个大语言模型的输出来提高单个实例的预测准确性和可靠性的问题。
核心思路:论文的核心思想是将多个大语言模型的输出视为一个“群体智慧”,通过学习不同模型之间的共识来提高预测的准确性。具体来说,它训练一个元学习器,该学习器以多个LLM的输出作为输入,并学习如何选择或组合这些输出以获得更可靠的答案。这种方法借鉴了集成学习的思想,但更侧重于利用LLM输出之间的语义关系和一致性。
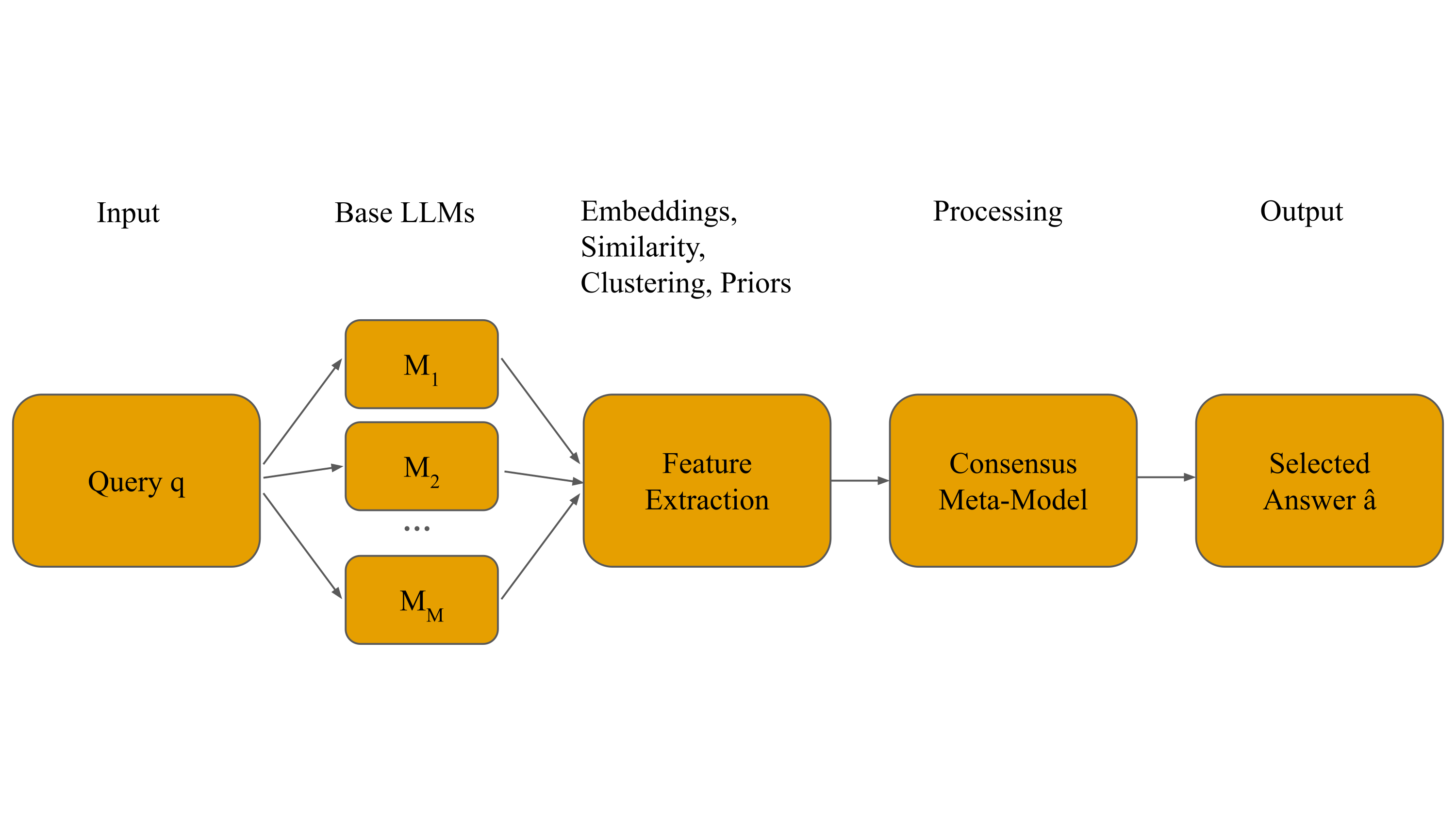
技术框架:该方法包含以下几个主要模块:1) 特征提取:将每个LLM的自然语言响应转换为结构化特征,包括语义嵌入、成对相似性、聚类统计、词汇和结构线索、推理质量评分、置信度估计以及模型特定的先验。2) 共识建模:使用不同的机器学习模型(梯度提升树、列表排序、图神经网络)来学习如何基于提取的特征选择或组合LLM的输出。图神经网络用于建模答案之间的相似性关系。3) 预测:基于共识模型输出最终的预测结果。
关键创新:该方法的主要创新在于:1) 将多模型共识问题形式化为一个监督学习问题,并设计了一系列有效的特征来表示LLM输出之间的关系。2) 探索了多种机器学习模型来学习共识,包括图神经网络,能够有效利用答案之间的相似性信息。3) 证明了即使在资源有限的情况下,该方法也能显著提高LLM的可靠性。
关键设计:论文中一些关键的设计包括:1) 使用预训练的语义嵌入模型来提取LLM输出的语义特征。2) 使用不同的聚类算法来分析答案之间的相似性。3) 使用图注意力网络来建模答案之间的关系,并学习每个答案的重要性。4) 实验中使用了三个开源的大语言模型,并在多个基准测试数据集上进行了评估。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于图注意力的共识模型在宏平均准确率上比最强的单个LLM提高了4.6个百分点,比多数投票提高了8.1个百分点。同时,该模型还降低了Brier分数,减少了TruthfulQA数据集上的幻觉。消融实验表明,语义一致性和聚类特征对性能提升贡献最大。
🎯 应用场景
该研究成果可应用于需要高可靠性的大语言模型应用场景,例如智能客服、医疗诊断辅助、金融风险评估等。通过提高LLM的准确性和鲁棒性,可以减少错误决策带来的风险,并提升用户体验。未来,该方法可以扩展到更多类型的LLM和更复杂的任务中。
📄 摘要(原文)
Large language models (LLMs) achieve strong aver- age performance yet remain unreliable at the instance level, with frequent hallucinations, brittle failures, and poorly calibrated confidence. We study reliability through the lens of multi-model consensus: given responses from several heterogeneous LLMs, can we learn which answer is most likely correct for a given query? We introduce a Multi-Model Consensus Reasoning Engine that treats the set of LLM outputs as input to a supervised meta-learner. The system maps natural language responses into structured features using semantic embeddings, pairwise similarity and clustering statistics, lexical and structural cues, reasoning-quality scores, confidence estimates, and model-specific priors, and then applies gradient-boosted trees, listwise ranking, and graph neural networks over similarity graphs of answers. Using three open-weight LLMs evaluated on compact, resource- constrained subsets of GSM8K, ARC-Challenge, HellaSwag, and TruthfulQA, our best graph-attention-based consensus model improves macro-average accuracy by 4.6 percentage points over the strongest single LLM and by 8.1 points over majority vote, while also yielding lower Brier scores and fewer TruthfulQA hal- lucinations. Ablation and feature-importance analyses show that semantic agreement and clustering features are most influential, with reasoning-quality and model-prior features providing com- plementary gains, suggesting supervised multi-model consensus is a practical route toward more reliable LLM behavior, even in a modest single-machine setup.