Stochastic CHAOS: Why Deterministic Inference Kills, and Distributional Variability Is the Heartbeat of Artifical Cognition
作者: Tanmay Joshi, Shourya Aggarwal, Anusa Saha, Aadi Pandey, Shreyash Dhoot, Vighnesh Rai, Raxit Goswami, Aman Chadha, Vinija Jain, Amitava Das
分类: cs.AI
发布日期: 2026-01-12
💡 一句话要点
反对LLM确定性推理:提出Stochastic CHAOS以提升模型不确定性建模与安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 确定性推理 随机性推理 不确定性建模 安全性评估
📋 核心要点
- 现有LLM推理过度依赖确定性,忽略了模型输出的内在不确定性,导致对模型能力和风险的评估失真。
- 论文提出Stochastic CHAOS,强调将分布变异性作为信号进行测量和控制,以更全面地理解LLM的行为。
- 实验表明,确定性推理低估了模型的能力和脆弱性,掩盖了涌现能力,降低了多路径推理的准确性,并低估了安全风险。
📝 摘要(中文)
确定性推理在传统软件中是一个令人安心的理想:相同的程序在相同的输入上应该总是产生相同的输出。随着大型语言模型进入实际部署,这种理想被完整地引入到推理栈中。本文对此持相反的观点,认为对于LLM来说,确定性推理会带来负面影响。它会扼杀模型不确定性建模的能力,抑制涌现能力,将推理简化为单一脆弱的路径,并通过隐藏尾部风险来削弱安全对齐。LLM实现的是输出上的条件分布,而不是固定的函数。将这些分布折叠成单一的规范补全可能看起来令人放心,但它系统地掩盖了对人工认知至关重要的属性。因此,我们提倡Stochastic CHAOS,将分布变异性视为一种需要测量和控制的信号。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)推理过程中过度依赖确定性方法所带来的问题。现有方法将LLM视为确定性函数,忽略了其输出的内在概率分布特性。这种确定性推理掩盖了模型的不确定性,导致对模型能力、脆弱性和安全风险的评估出现偏差。现有方法的痛点在于无法准确反映LLM的真实行为,可能导致在实际应用中出现意外情况。
核心思路:论文的核心思路是反对LLM的确定性推理,并提倡Stochastic CHAOS。Stochastic CHAOS的核心在于将LLM的输出视为一个概率分布,而不是一个单一的确定性结果。通过测量和控制这种分布的变异性,可以更全面地理解LLM的行为,从而更好地评估其能力、脆弱性和安全风险。这种思路强调了LLM的随机性和不确定性是其本质特征,而不是需要消除的缺陷。
技术框架:论文并没有提出一个具体的模型架构或训练方法,而是提供了一种评估和理解LLM的新视角。其技术框架主要体现在实验设计和分析方法上。论文通过设计一系列实验,比较了确定性推理和随机性推理在评估LLM能力、脆弱性、多路径推理和安全风险方面的差异。这些实验旨在揭示确定性推理的局限性,并证明随机性推理的必要性。
关键创新:论文最重要的技术创新点在于其对LLM推理范式的重新思考。它挑战了将LLM视为确定性函数的传统观念,并提出了将LLM的输出视为概率分布的Stochastic CHAOS框架。这种框架为评估和理解LLM的行为提供了一种更全面、更准确的方法。与现有方法的本质区别在于,它不再试图消除LLM的随机性,而是将其视为一种有价值的信息来源。
关键设计:论文的关键设计体现在实验设计上。例如,为了评估确定性推理对模型能力的影响,论文比较了贪婪解码和多样本评估在揭示涌现能力方面的差异。为了评估确定性推理对安全风险的影响,论文比较了单样本评估和多样本评估在发现罕见但危险行为方面的差异。这些实验设计旨在突出确定性推理的局限性,并证明随机性推理的优势。
🖼️ 关键图片

📊 实验亮点
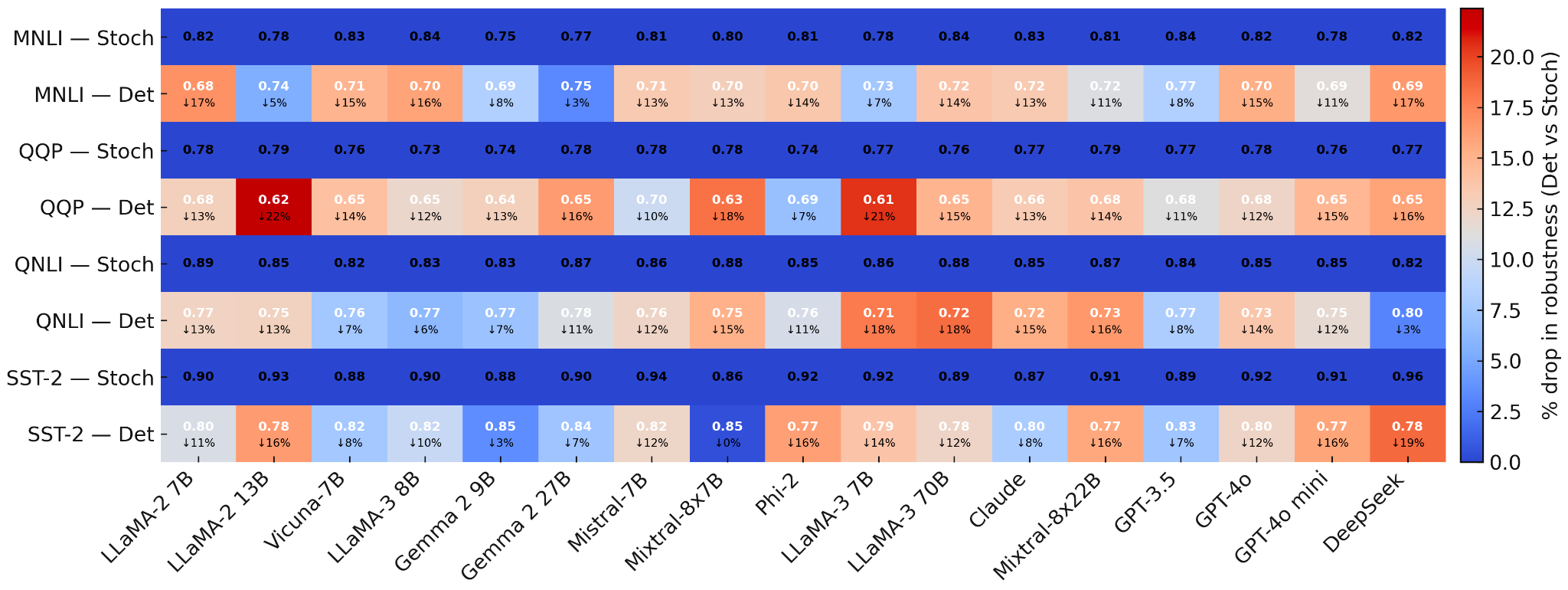
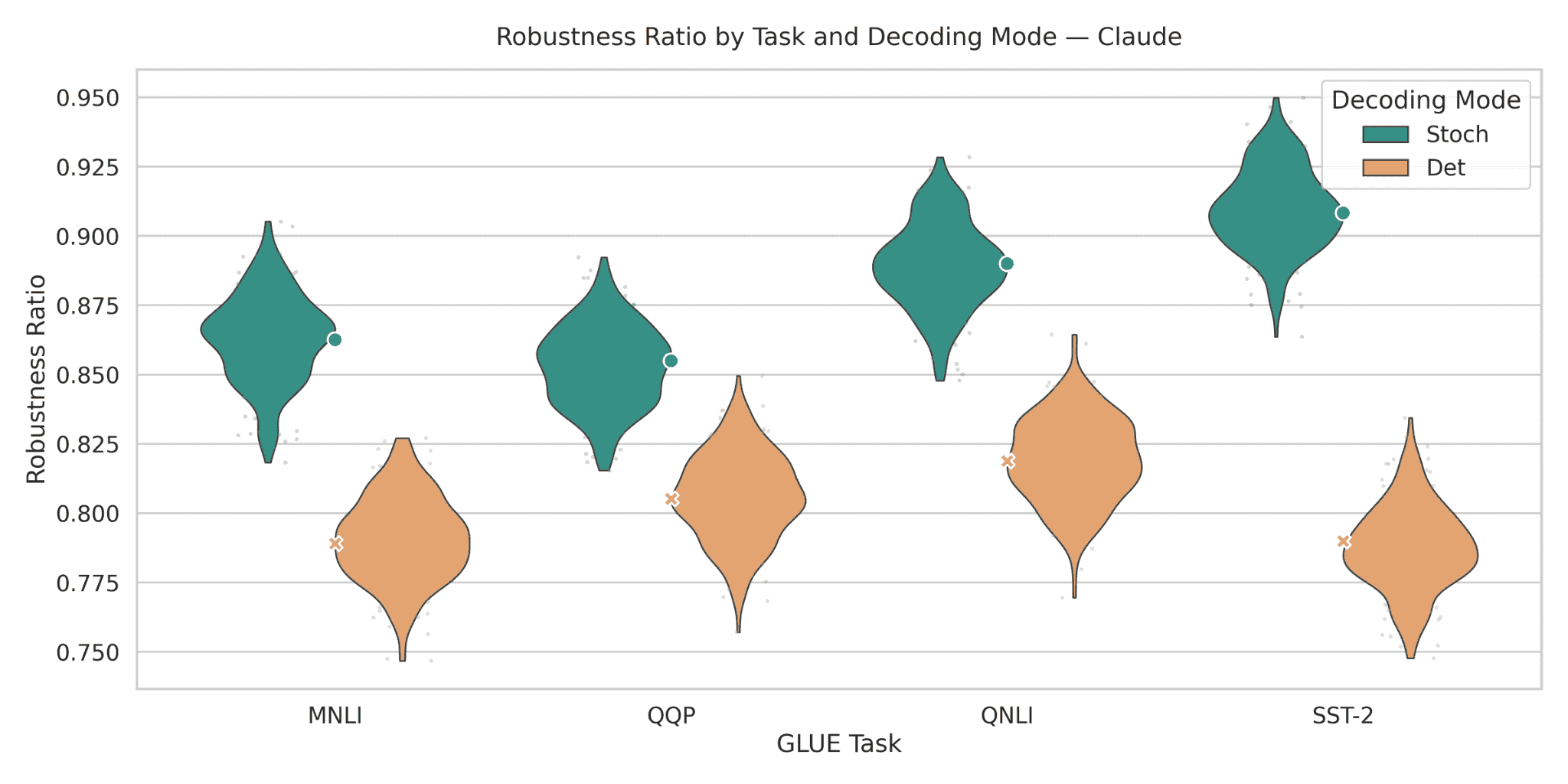
研究表明,确定性推理低估了LLM的能力和脆弱性,掩盖了涌现能力,降低了多路径推理的准确性,并低估了安全风险。例如,贪婪解码会使与涌现能力相关的阶段性转变消失。此外,单样本确定性评估会低估安全风险,无法发现多样本评估才能揭示的罕见但危险的行为。
🎯 应用场景
该研究成果可应用于LLM的安全性评估、风险控制和能力提升。通过更准确地评估LLM的不确定性,可以更好地预测和避免潜在的安全问题,并提高LLM在复杂任务中的表现。此外,该研究还可以指导LLM的训练和优化,使其更好地适应真实世界的应用场景。
📄 摘要(原文)
Deterministic inference is a comforting ideal in classical software: the same program on the same input should always produce the same output. As large language models move into real-world deployment, this ideal has been imported wholesale into inference stacks. Recent work from the Thinking Machines Lab has presented a detailed analysis of nondeterminism in LLM inference, showing how batch-invariant kernels and deterministic attention can enforce bitwise-identical outputs, positioning deterministic inference as a prerequisite for reproducibility and enterprise reliability. In this paper, we take the opposite stance. We argue that, for LLMs, deterministic inference kills. It kills the ability to model uncertainty, suppresses emergent abilities, collapses reasoning into a single brittle path, and weakens safety alignment by hiding tail risks. LLMs implement conditional distributions over outputs, not fixed functions. Collapsing these distributions to a single canonical completion may appear reassuring, but it systematically conceals properties central to artificial cognition. We instead advocate Stochastic CHAOS, treating distributional variability as a signal to be measured and controlled. Empirically, we show that deterministic inference is systematically misleading. Single-sample deterministic evaluation underestimates both capability and fragility, masking failure probability under paraphrases and noise. Phase-like transitions associated with emergent abilities disappear under greedy decoding. Multi-path reasoning degrades when forced onto deterministic backbones, reducing accuracy and diagnostic insight. Finally, deterministic evaluation underestimates safety risk by hiding rare but dangerous behaviors that appear only under multi-sample evaluation.