From "Thinking" to "Justifying": Aligning High-Stakes Explainability with Professional Communication Standards
作者: Chen Qian, Yimeng Wang, Yu Chen, Lingfei Wu, Andreas Stathopoulos
分类: cs.AI
发布日期: 2026-01-12
💡 一句话要点
提出结构化解释框架以提升高风险领域的可解释性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可解释人工智能 结构化解释 高风险领域 信任与验证 专业沟通标准
📋 核心要点
- 现有的思维链方法在高风险领域的推理过程中存在逻辑缺口,导致结论与理由不一致,影响可解释性和可靠性。
- 本文提出了“结果 -> 解释”的方法,要求在给出结构化解释之前先明确结论,从而增强输出的可验证性。
- 实验结果显示,结构化可解释性框架(SEF)在多个任务中表现优异,准确率达到83.9%,显著优于传统方法。
📝 摘要(中文)
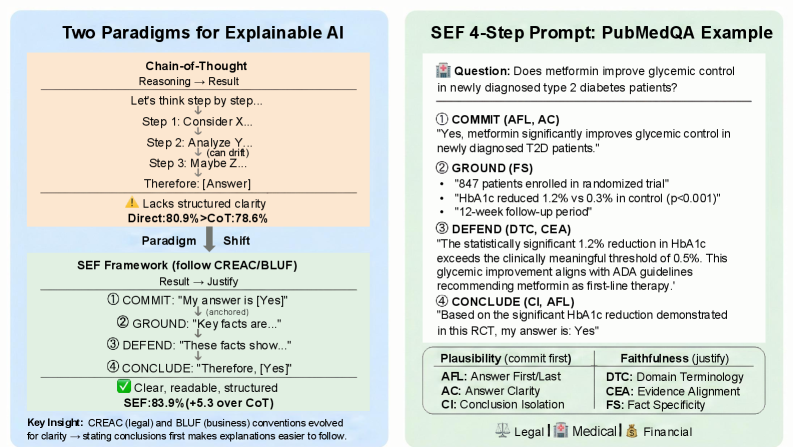
高风险领域的可解释人工智能(XAI)应帮助利益相关者信任和验证系统输出。然而,现有的思维链方法在得出结论之前进行推理,可能导致逻辑缺口或幻觉,从而使结论与其理由不一致。为此,本文提出“结果 -> 解释”的方法,要求输出在结构化解释之前先给出结论。我们引入结构化可解释性框架(SEF),通过六个结构和基础度量标准来实现专业惯例(如CREAC、BLUF)。在三个领域的四项任务中的实验验证了该方法:所有六个度量与正确性相关(r=0.20-0.42; p<0.001),SEF的准确率达到83.9%(比思维链方法提高5.3%)。这些结果表明,结构化解释可以提高可验证性,并可能改善可靠性。
🔬 方法详解
问题定义:本文旨在解决高风险领域中可解释人工智能(XAI)输出的可靠性和可验证性问题。现有的思维链方法在推理过程中可能出现逻辑缺口,导致结论与其理由不一致,影响用户的信任。
核心思路:论文提出“结果 -> 解释”的方法,要求在输出时首先给出结论,然后再进行结构化的理由解释。这种设计旨在增强输出的可验证性,使利益相关者能够更容易地理解和信任系统的决策。
技术框架:整体架构包括两个主要模块:首先是结论生成模块,其次是结构化解释模块。结论生成模块负责快速得出结果,而结构化解释模块则根据专业惯例(如CREAC、BLUF)提供详细的解释。
关键创新:最重要的技术创新在于引入了结构化可解释性框架(SEF),通过六个度量标准来评估输出的结构和基础性。这一框架与现有方法的本质区别在于强调了结论优先的输出方式,从而提高了可验证性。
关键设计:在设计中,采用了六个度量标准来评估结构化解释的有效性,并通过实验验证了这些标准与输出正确性之间的相关性。此外,SEF的准确率达到了83.9%,比传统思维链方法提高了5.3%。
🖼️ 关键图片
📊 实验亮点
实验结果表明,结构化可解释性框架(SEF)在四项任务中取得了83.9%的准确率,比传统的思维链方法提高了5.3%。所有六个度量标准与输出的正确性均存在显著相关性(r=0.20-0.42; p<0.001),验证了结构化解释的有效性。
🎯 应用场景
该研究的潜在应用领域包括医疗、金融和法律等高风险行业。在这些领域,决策的透明性和可解释性至关重要,结构化解释框架能够帮助专业人士更好地理解和验证AI系统的输出,从而提升决策的信任度和可靠性。未来,该框架可能会被广泛应用于各种需要高可解释性的AI系统中。
📄 摘要(原文)
Explainable AI (XAI) in high-stakes domains should help stakeholders trust and verify system outputs. Yet Chain-of-Thought methods reason before concluding, and logical gaps or hallucinations can yield conclusions that do not reliably align with their rationale. Thus, we propose "Result -> Justify", which constrains the output communication to present a conclusion before its structured justification. We introduce SEF (Structured Explainability Framework), operationalizing professional conventions (e.g., CREAC, BLUF) via six metrics for structure and grounding. Experiments across four tasks in three domains validate this approach: all six metrics correlate with correctness (r=0.20-0.42; p<0.001), and SEF achieves 83.9% accuracy (+5.3 over CoT). These results suggest structured justification can improve verifiability and may also improve reliability.