Yes FLoReNce, I Will Do Better Next Time! Agentic Feedback Reasoning for Humorous Meme Detection
作者: Olivia Shanhong Liu, Pai Chet Ng, De Wen Soh, Konstantinos N. Plataniotis
分类: cs.AI
发布日期: 2026-01-12
备注: LaMAS@AAAI 2026 (Oral)
💡 一句话要点
提出FLoReNce框架,通过Agent反馈推理提升幽默Meme检测性能
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 幽默Meme检测 Agent反馈推理 多模态学习 Prompt工程 知识库 闭环学习
📋 核心要点
- 现有Meme幽默检测模型缺乏在预测后进行批判和改进推理的能力,导致理解深度不足。
- FLoReNce框架通过闭环学习,利用评判者的反馈来指导Agent的推理过程,提升模型理解能力。
- 实验表明,FLoReNce在PrideMM数据集上优于静态多模态基线,验证了反馈调节Prompt的有效性。
📝 摘要(中文)
幽默Meme融合了视觉和文本线索,通过反讽、讽刺或社会评论来传递信息,这对必须解释意图而非表面相关性的人工智能系统提出了独特的挑战。现有的多模态或基于Prompt的模型可以生成幽默解释,但以开环方式运行,缺乏在做出预测后批判或改进其推理的能力。我们提出了FLoReNce,一个Agent反馈推理框架,它将Meme理解视为学习过程中的闭环过程和推理过程中的开环过程。在闭环中,推理Agent受到评判者的批判;误差和语义反馈被转换为控制信号并存储在反馈知情的非参数知识库中。在推理时,模型从该知识库中检索类似的已评判经验,并使用它们来调节其Prompt,从而实现更好、自我对齐的推理,而无需微调。在PrideMM数据集上,FLoReNce提高了预测性能和解释质量,优于静态多模态基线,表明反馈调节的Prompt是自适应Meme幽默理解的可行途径。
🔬 方法详解
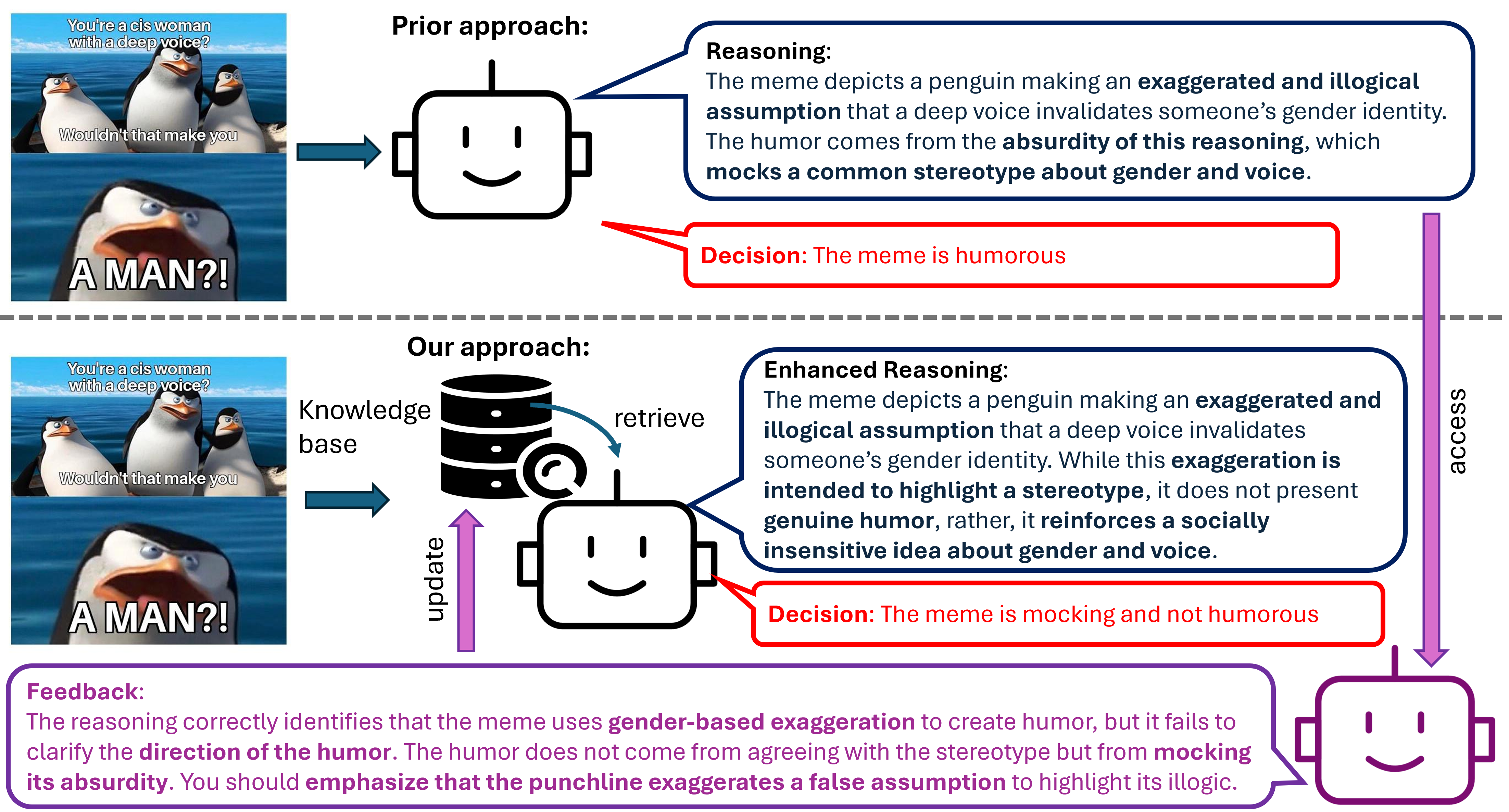
问题定义:论文旨在解决幽默Meme检测问题,现有方法主要依赖多模态特征融合或Prompt工程,但缺乏对模型推理过程的反馈和迭代优化机制,导致模型难以捕捉Meme中蕴含的深层语义和幽默感。这些方法通常是“一次性”的,无法根据预测结果进行自我修正和改进。
核心思路:论文的核心思路是将Meme理解过程建模为一个Agent与环境交互的闭环系统。Agent负责进行推理和预测,而环境(通过评判者模拟)提供反馈信号,指导Agent改进其推理策略。通过这种迭代学习的方式,模型能够逐步提升对幽默Meme的理解能力。
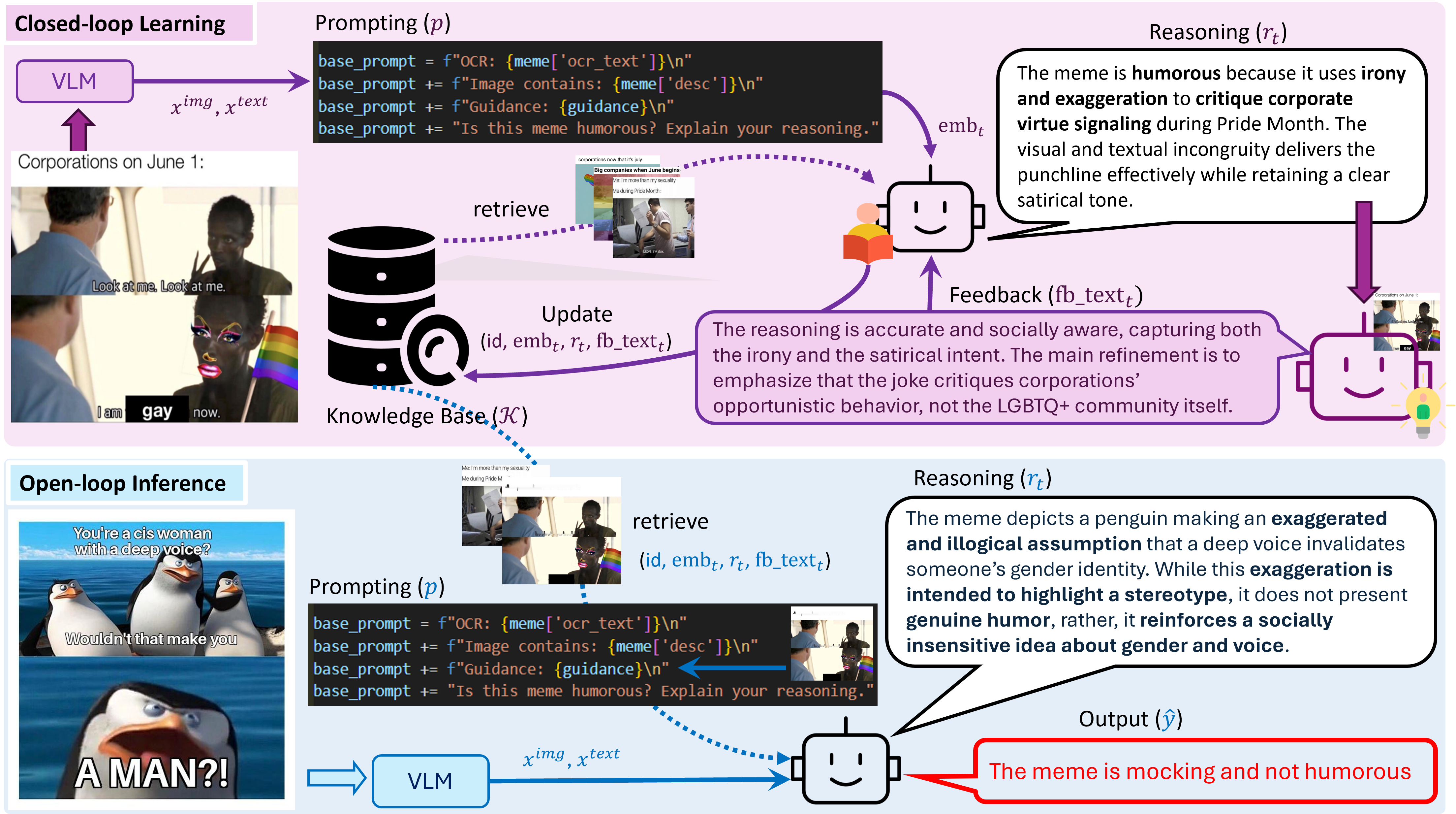
技术框架:FLoReNce框架包含三个主要模块:推理Agent、评判者和反馈知情的非参数知识库。推理Agent负责接收Meme输入,生成幽默解释和预测结果。评判者根据Agent的输出,提供误差和语义反馈。反馈信息被转换为控制信号,存储在知识库中。在推理阶段,模型从知识库中检索相似的已评判经验,并利用这些经验来调节Prompt,从而指导推理过程。
关键创新:该论文的关键创新在于引入了Agent反馈推理机制,将Meme理解视为一个闭环学习过程。与传统的开环方法相比,FLoReNce能够根据反馈信号动态调整推理策略,从而更好地捕捉Meme中的幽默感。此外,利用非参数知识库存储和检索经验,避免了对模型进行微调的需求。
关键设计:评判者的设计至关重要,需要能够提供准确的误差和语义反馈。知识库的设计需要考虑如何有效地存储和检索经验,以便在推理阶段能够找到最相关的指导信息。Prompt的调节策略也需要精心设计,以确保反馈信息能够有效地指导推理过程。具体的参数设置、损失函数和网络结构等技术细节在论文中应该有详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
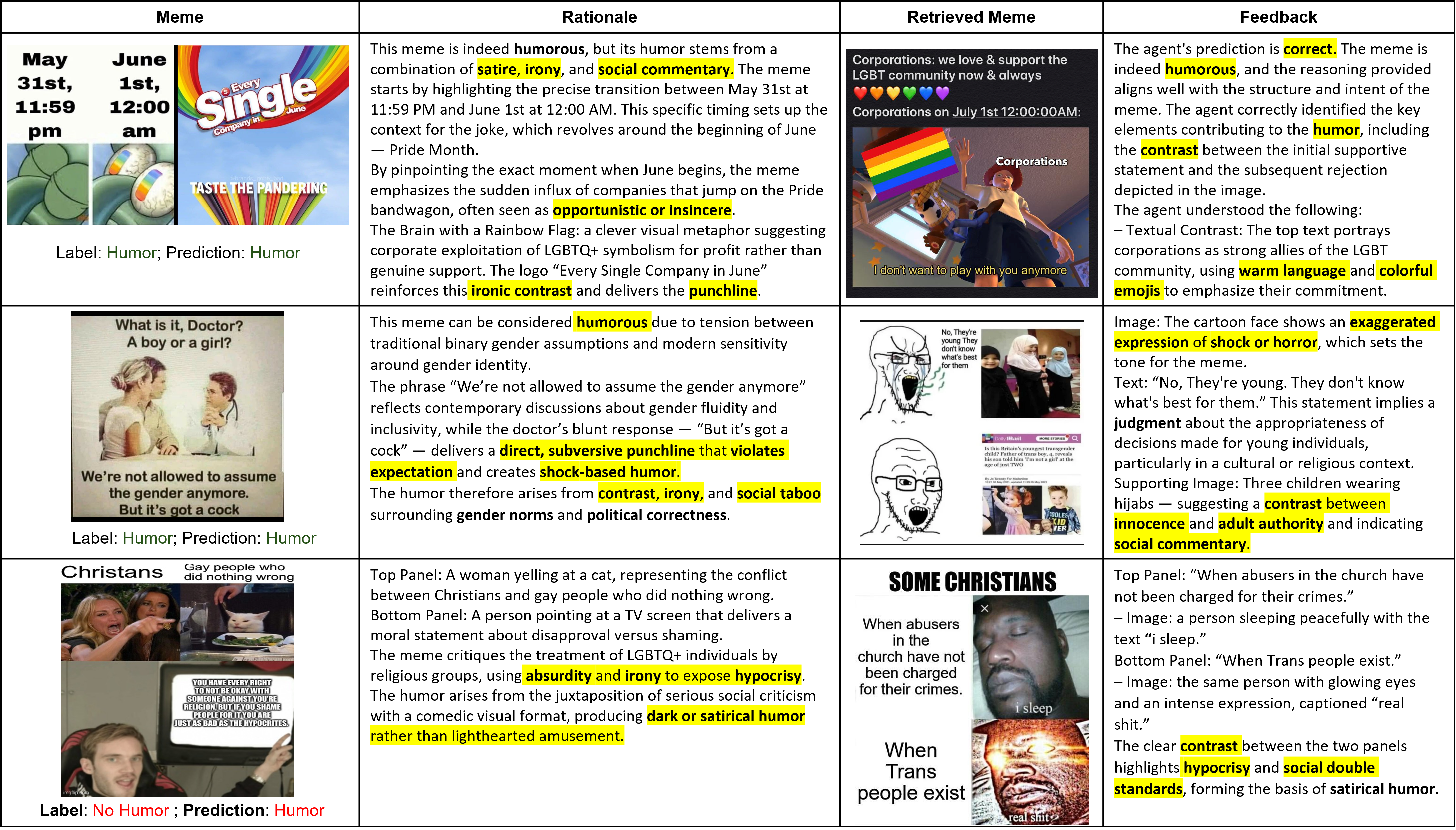
FLoReNce在PrideMM数据集上取得了显著的性能提升,证明了反馈调节Prompt的有效性。具体的数据指标和对比基线在论文中应该有详细描述(未知),但摘要中明确指出FLoReNce优于静态多模态基线,并且提高了预测性能和解释质量。
🎯 应用场景
该研究成果可应用于社交媒体内容审核、智能推荐系统和人机交互等领域。通过提升AI系统对幽默Meme的理解能力,可以更有效地过滤不良信息,提高推荐内容的质量,并改善人机对话的流畅性和趣味性。未来,该方法有望扩展到其他需要深度语义理解的任务中。
📄 摘要(原文)
Humorous memes blend visual and textual cues to convey irony, satire, or social commentary, posing unique challenges for AI systems that must interpret intent rather than surface correlations. Existing multimodal or prompting-based models generate explanations for humor but operate in an open loop,lacking the ability to critique or refine their reasoning once a prediction is made. We propose FLoReNce, an agentic feedback reasoning framework that treats meme understanding as a closed-loop process during learning and an open-loop process during inference. In the closed loop, a reasoning agent is critiqued by a judge; the error and semantic feedback are converted into control signals and stored in a feedback-informed, non-parametric knowledge base. At inference, the model retrieves similar judged experiences from this KB and uses them to modulate its prompt, enabling better, self-aligned reasoning without finetuning. On the PrideMM dataset, FLoReNce improves both predictive performance and explanation quality over static multimodal baselines, showing that feedback-regulated prompting is a viable path to adaptive meme humor understanding.