LLMRouterBench: A Massive Benchmark and Unified Framework for LLM Routing
作者: Hao Li, Yiqun Zhang, Zhaoyan Guo, Chenxu Wang, Shengji Tang, Qiaosheng Zhang, Yang Chen, Biqing Qi, Peng Ye, Lei Bai, Zhen Wang, Shuyue Hu
分类: cs.AI
发布日期: 2026-01-12
🔗 代码/项目: GITHUB
💡 一句话要点
LLMRouterBench:大规模LLM路由基准测试与统一框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM路由 基准测试 大语言模型 模型选择 性能评估
📋 核心要点
- 现有LLM路由方法缺乏统一的评估标准,难以公平比较不同方法的优劣。
- LLMRouterBench提供大规模基准和统一框架,促进LLM路由算法的公平评估与分析。
- 实验表明,现有路由方法性能相似,与理想状态仍有差距,模型召回是主要瓶颈。
📝 摘要(中文)
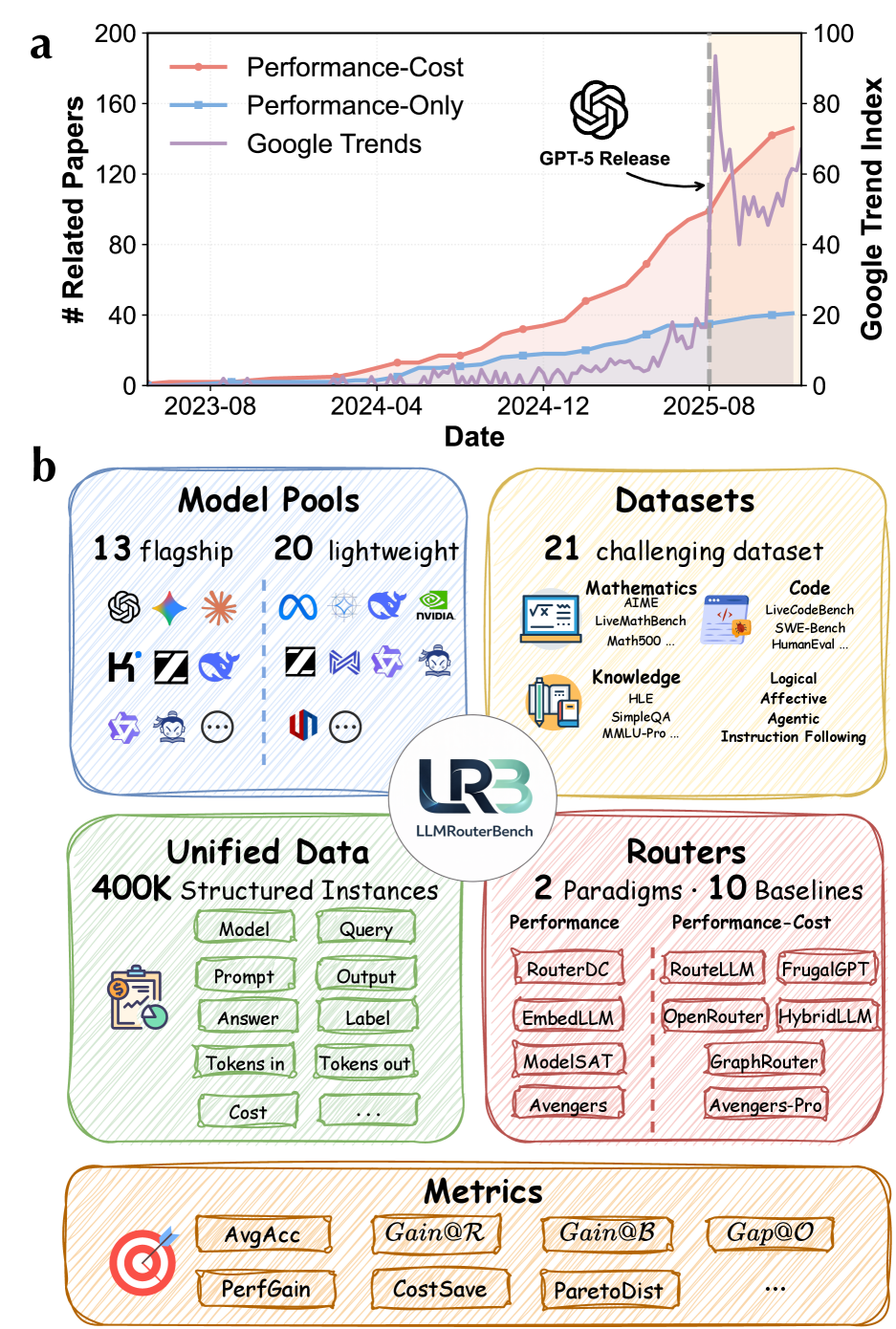
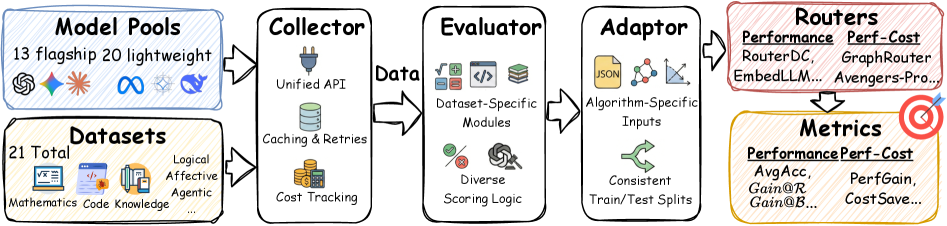
本文提出了LLMRouterBench,一个用于LLM路由的大规模基准测试和统一框架。它包含来自21个数据集的超过40万个实例和33个模型。此外,它为面向性能的路由和性能-成本权衡路由提供了全面的指标,并集成了10个具有代表性的路由基线。使用LLMRouterBench,我们系统地重新评估了该领域。在确认强大的模型互补性(LLM路由的核心前提)的同时,我们发现许多路由方法在统一评估下表现出相似的性能,并且包括商业路由器在内的一些最新方法未能可靠地优于简单的基线。同时,与Oracle相比仍然存在很大的差距,这主要是由于持续存在的模型召回失败所致。我们进一步表明,骨干嵌入模型的影响有限,与仔细的模型管理相比,更大的集成表现出收益递减,并且该基准测试还支持延迟感知分析。所有代码和数据均可在https://github.com/ynulihao/LLMRouterBench获得。
🔬 方法详解
问题定义:LLM路由旨在将每个查询分配给集成中最合适的模型。现有方法的痛点在于缺乏统一的评估标准,导致不同方法之间的比较不公平,并且难以准确评估各种路由策略的有效性。此外,商业路由器的实际性能也缺乏充分的验证。
核心思路:LLMRouterBench的核心思路是构建一个大规模、多样化的基准测试,并提供统一的评估框架,以便对各种LLM路由方法进行公平、全面的评估。通过系统性的实验,揭示现有方法的优势与不足,并为未来的研究方向提供指导。
技术框架:LLMRouterBench包含以下主要组成部分:1) 大规模数据集:包含来自21个数据集的超过40万个实例,覆盖多种任务类型。2) 多样化模型集合:包含33个不同的LLM模型,涵盖不同规模和架构。3) 统一评估指标:提供面向性能和性能-成本权衡的全面指标。4) 路由基线:集成10个具有代表性的路由基线,方便比较。5) 延迟感知分析:支持考虑模型推理延迟的路由策略评估。
关键创新:LLMRouterBench的关键创新在于其大规模、多样化的数据集和统一的评估框架。它首次对LLM路由领域进行了系统性的重新评估,揭示了现有方法的性能瓶颈和潜在改进方向。此外,该基准测试还支持延迟感知分析,为实际应用场景下的LLM路由提供了更全面的评估。
关键设计:LLMRouterBench在数据集构建方面,注重覆盖不同任务类型和数据分布,以保证评估的全面性。在评估指标方面,除了传统的准确率等性能指标外,还考虑了模型推理成本和延迟,以支持性能-成本权衡的路由策略评估。此外,该基准测试还提供了易于使用的API和工具,方便研究人员进行实验和分析。
🖼️ 关键图片
📊 实验亮点
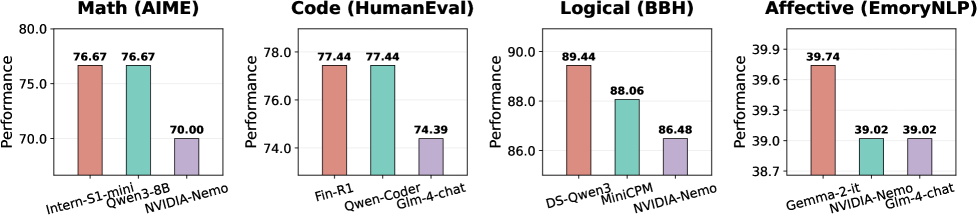
实验结果表明,许多路由方法在统一评估下表现出相似的性能,一些商业路由器未能可靠地优于简单的基线。与Oracle相比仍然存在较大的性能差距,主要原因是模型召回失败。此外,实验还发现骨干嵌入模型的影响有限,并且更大的模型集成相比于精心挑选的模型,收益递减。
🎯 应用场景
LLMRouterBench可应用于各种需要高效利用LLM资源的场景,例如智能客服、内容生成、代码生成等。通过选择最合适的LLM模型来处理不同的查询,可以提高服务质量、降低计算成本,并提升用户体验。该基准测试还有助于推动LLM路由算法的进一步发展,为构建更智能、更高效的AI系统提供支持。
📄 摘要(原文)
Large language model (LLM) routing assigns each query to the most suitable model from an ensemble. We introduce LLMRouterBench, a large-scale benchmark and unified framework for LLM routing. It comprises over 400K instances from 21 datasets and 33 models. Moreover, it provides comprehensive metrics for both performance-oriented routing and performance-cost trade-off routing, and integrates 10 representative routing baselines. Using LLMRouterBench, we systematically re-evaluate the field. While confirming strong model complementarity-the central premise of LLM routing-we find that many routing methods exhibit similar performance under unified evaluation, and several recent approaches, including commercial routers, fail to reliably outperform a simple baseline. Meanwhile, a substantial gap remains to the Oracle, driven primarily by persistent model-recall failures. We further show that backbone embedding models have limited impact, that larger ensembles exhibit diminishing returns compared to careful model curation, and that the benchmark also enables latency-aware analysis. All code and data are available at https://github.com/ynulihao/LLMRouterBench.