Active Context Compression: Autonomous Memory Management in LLM Agents
作者: Nikhil Verma
分类: cs.AI
发布日期: 2026-01-12
备注: 8 pages, 2 figures, 2 tables. IEEE conference format
💡 一句话要点
Focus:面向LLM Agent的主动上下文压缩,解决长程任务中的Context Bloat问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 上下文压缩 长程任务 自主学习 知识管理
📋 核心要点
- 现有LLM Agent在长程任务中受限于“Context Bloat”,导致计算成本高、延迟大、推理能力下降。
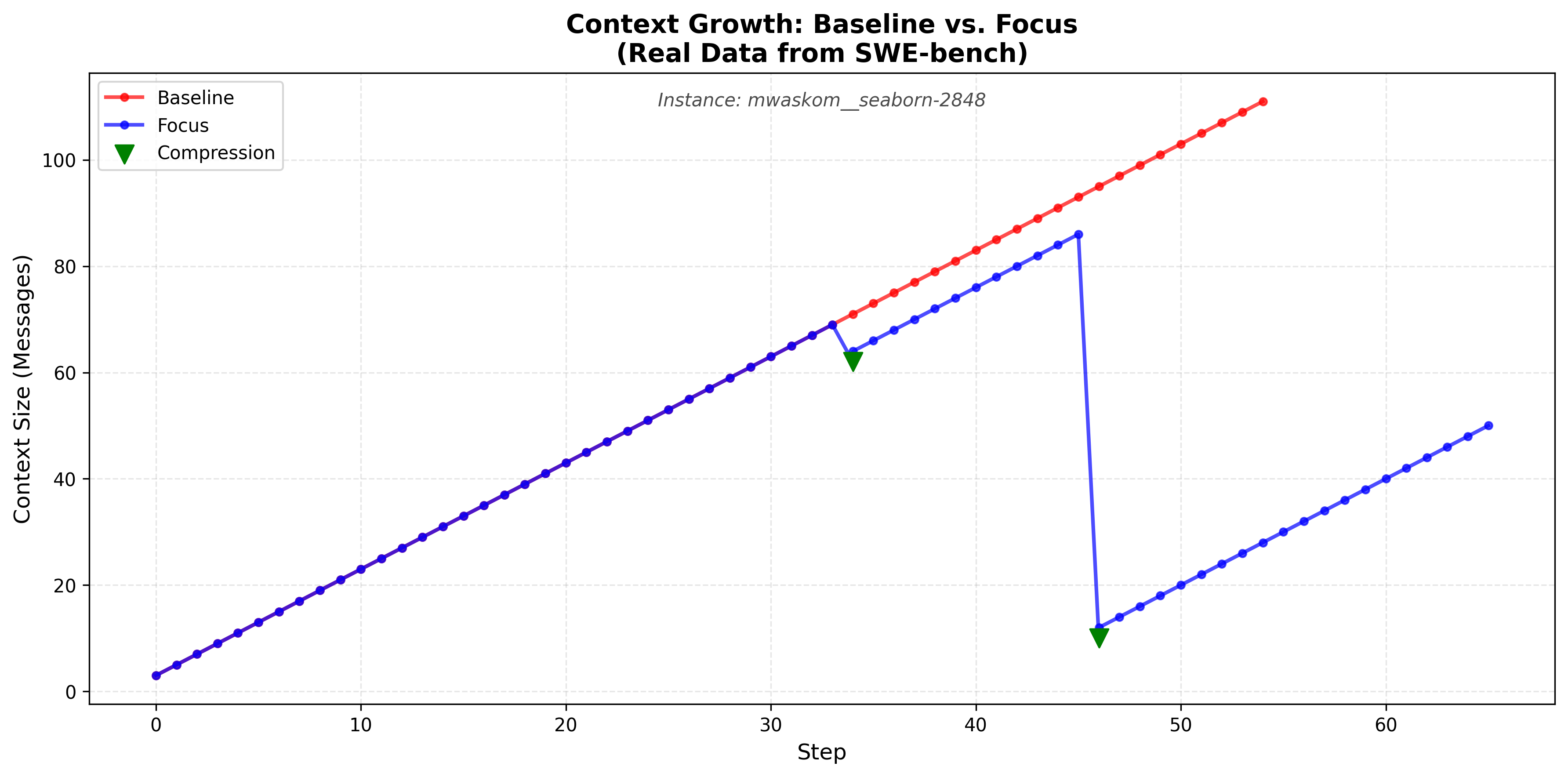
- Focus Agent借鉴生物灵感,自主决定何时将关键信息压缩到“知识”块,并修剪原始交互历史。
- 实验表明,Focus在保持任务准确率的同时,显著减少了token数量,降低了计算成本。
📝 摘要(中文)
大型语言模型(LLM)Agent在长程软件工程任务中面临“Context Bloat”问题。随着交互历史的增长,计算成本激增,延迟增加,并且由于不相关的历史错误分散注意力,推理能力下降。现有的解决方案通常依赖于被动的、外部的总结机制,Agent无法控制。本文提出了Focus,一种受多头绒泡菌(Physarum polycephalum)生物探索策略启发的、以Agent为中心的架构。Focus Agent自主决定何时将关键学习内容整合到持久的“知识”块中,并主动撤回(修剪)原始交互历史。在使用优化的、符合行业最佳实践的支架(持久的bash +字符串替换编辑器)的基础上,我们使用Claude Haiku 4.5在SWE-bench Lite中的N=5个上下文密集型实例上评估了Focus。通过鼓励频繁压缩的积极提示,Focus实现了22.7%的token减少(14.9M -> 11.5M tokens),同时保持了相同的准确率(3/5 = 60%)。Focus平均每个任务执行6.0次自主压缩,单个实例的token节省高达57%。我们证明,当给予适当的工具和提示时,有能力的模型可以自主调节其上下文,从而为不牺牲任务性能的、具有成本意识的Agent系统开辟了道路。
🔬 方法详解
问题定义:LLM Agent在执行长程软件工程任务时,由于上下文长度的限制,需要处理大量的交互历史。这些历史记录包含了大量的冗余和不相关信息,导致“Context Bloat”问题,具体表现为计算成本增加、推理速度变慢以及推理质量下降。现有的上下文管理方法通常是被动的,Agent无法主动控制上下文信息的选择和压缩。
核心思路:Focus的核心思路是赋予LLM Agent自主管理上下文的能力。Agent可以根据自身的需要,主动地将重要的信息提炼并压缩成“知识”块,并删除不相关的历史记录。这种主动的上下文管理方式可以有效地减少上下文长度,降低计算成本,并提高推理效率。该方法借鉴了多头绒泡菌的探索策略,模拟其在寻找食物时对路径进行优化和剪枝的过程。
技术框架:Focus Agent的整体架构包含以下几个主要模块:1) 交互模块:负责与环境进行交互,记录交互历史。2) 压缩决策模块:根据当前的任务状态和交互历史,决定是否需要进行上下文压缩。3) 知识提取模块:从交互历史中提取关键信息,形成“知识”块。4) 上下文更新模块:将“知识”块添加到上下文中,并删除不相关的历史记录。整个流程是一个循环迭代的过程,Agent不断地与环境交互,并根据需要进行上下文压缩。
关键创新:Focus的关键创新在于Agent的主动上下文管理能力。与传统的被动上下文管理方法不同,Focus Agent可以自主地决定何时进行上下文压缩,以及如何选择和压缩上下文信息。这种主动性使得Agent能够更好地适应不同的任务需求,并有效地利用有限的上下文资源。
关键设计:Focus使用了Claude Haiku 4.5作为基础模型,并采用了一种优化的支架,包括持久的bash环境和字符串替换编辑器。在提示工程方面,采用了积极的提示策略,鼓励Agent频繁地进行上下文压缩。具体的压缩策略和知识提取方法是未知的,论文中没有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Focus在SWE-bench Lite数据集上实现了22.7%的token减少(14.9M -> 11.5M tokens),同时保持了相同的准确率(3/5 = 60%)。Focus平均每个任务执行6.0次自主压缩,单个实例的token节省高达57%。这些结果表明,Focus能够有效地管理上下文,降低计算成本,并提升Agent的性能。
🎯 应用场景
Focus具有广泛的应用前景,可以应用于各种需要长程推理和决策的LLM Agent任务,例如软件开发、机器人控制、对话系统等。通过自主管理上下文,Focus可以有效地降低计算成本,提高推理效率,并提升Agent的整体性能。该研究为构建更智能、更高效的Agent系统提供了新的思路。
📄 摘要(原文)
Large Language Model (LLM) agents struggle with long-horizon software engineering tasks due to "Context Bloat." As interaction history grows, computational costs explode, latency increases, and reasoning capabilities degrade due to distraction by irrelevant past errors. Existing solutions often rely on passive, external summarization mechanisms that the agent cannot control. This paper proposes Focus, an agent-centric architecture inspired by the biological exploration strategies of Physarum polycephalum (slime mold). The Focus Agent autonomously decides when to consolidate key learnings into a persistent "Knowledge" block and actively withdraws (prunes) the raw interaction history. Using an optimized scaffold matching industry best practices (persistent bash + string-replacement editor), we evaluated Focus on N=5 context-intensive instances from SWE-bench Lite using Claude Haiku 4.5. With aggressive prompting that encourages frequent compression, Focus achieves 22.7% token reduction (14.9M -> 11.5M tokens) while maintaining identical accuracy (3/5 = 60% for both agents). Focus performed 6.0 autonomous compressions per task on average, with token savings up to 57% on individual instances. We demonstrate that capable models can autonomously self-regulate their context when given appropriate tools and prompting, opening pathways for cost-aware agentic systems without sacrificing task performance.