Defenses Against Prompt Attacks Learn Surface Heuristics
作者: Shawn Li, Chenxiao Yu, Zhiyu Ni, Hao Li, Charith Peris, Chaowei Xiao, Yue Zhao
分类: cs.CR, cs.AI
发布日期: 2026-01-12
💡 一句话要点
提出对抗提示攻击的新防御方法以解决现有模型的安全性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对抗攻击 大型语言模型 安全性 监督微调 捷径行为 性能评估 自然语言处理
📋 核心要点
- 现有的防御方法在处理对抗性输入时,容易导致安全输入被错误拒绝,影响模型的实际应用。
- 论文通过引入受控诊断数据集,系统评估不同防御管道的有效性,揭示了现有方法的局限性。
- 实验结果显示,模型在防御微调后出现了高达90%的错误拒绝率,且在测试时准确率下降幅度可达40%。
📝 摘要(中文)
随着大型语言模型(LLMs)在安全敏感应用中的广泛部署,它们必须遵循系统或开发者指定的指令,以定义预期的任务行为,同时完成用户的良性请求。然而,当用户查询或外部检索内容中出现对抗性指令时,模型可能会覆盖预期逻辑。现有的防御方法依赖于带有良性和恶意标签的监督微调,尽管这些方法实现了高攻击拒绝率,但研究发现它们依赖于防御数据中的狭窄相关性,而非有害意图,导致安全输入的系统性拒绝。本文分析了三种由防御微调引发的常见捷径行为,并提出了受控的诊断数据集和系统评估,突显了监督微调在可靠LLM安全性方面的局限性。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在面对对抗性提示时的安全性问题,现有方法在防御过程中容易误拒绝安全输入,导致模型性能下降。
核心思路:论文提出通过受控诊断数据集来分析和评估防御微调的效果,重点关注模型在处理不同类型输入时的表现,以识别和缓解防御中的捷径行为。
技术框架:整体架构包括数据收集、模型微调和性能评估三个主要阶段。首先,构建受控数据集以涵盖多种输入类型;其次,对模型进行微调以增强其对抗性;最后,通过系统评估不同防御策略的有效性。
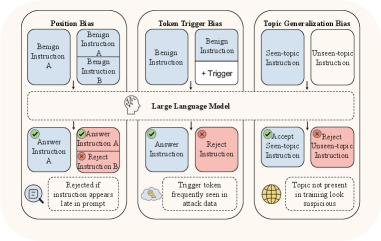
关键创新:最重要的技术创新在于识别出防御微调过程中引发的三种捷径行为(位置偏差、触发标记偏差和主题泛化偏差),并通过受控实验揭示其对模型性能的影响。
关键设计:在微调过程中,采用了特定的损失函数和参数设置,以确保模型能够在不同输入上下文中保持较高的准确性,同时避免对安全输入的误拒绝。
🖼️ 关键图片

📊 实验亮点
实验结果显示,防御微调后模型在处理后缀任务时的拒绝率从10%上升至90%,而插入单个触发标记导致的错误拒绝率增加高达50%。此外,模型在测试时的准确率下降幅度可达40%,突显了现有方法的局限性。
🎯 应用场景
该研究的潜在应用领域包括安全敏感的自然语言处理任务,如金融、医疗和法律等行业的智能助手。通过提高大型语言模型的安全性,能够更好地保护用户数据和隐私,增强模型在实际应用中的可靠性。
📄 摘要(原文)
Large language models (LLMs) are increasingly deployed in security-sensitive applications, where they must follow system- or developer-specified instructions that define the intended task behavior, while completing benign user requests. When adversarial instructions appear in user queries or externally retrieved content, models may override intended logic. Recent defenses rely on supervised fine-tuning with benign and malicious labels. Although these methods achieve high attack rejection rates, we find that they rely on narrow correlations in defense data rather than harmful intent, leading to systematic rejection of safe inputs. We analyze three recurring shortcut behaviors induced by defense fine-tuning. \emph{Position bias} arises when benign content placed later in a prompt is rejected at much higher rates; across reasoning benchmarks, suffix-task rejection rises from below \textbf{10\%} to as high as \textbf{90\%}. \emph{Token trigger bias} occurs when strings common in attack data raise rejection probability even in benign contexts; inserting a single trigger token increases false refusals by up to \textbf{50\%}. \emph{Topic generalization bias} reflects poor generalization beyond the defense data distribution, with defended models suffering test-time accuracy drops of up to \textbf{40\%}. These findings suggest that current prompt-injection defenses frequently respond to attack-like surface patterns rather than the underlying intent. We introduce controlled diagnostic datasets and a systematic evaluation across two base models and multiple defense pipelines, highlighting limitations of supervised fine-tuning for reliable LLM security.