Safe-FedLLM: Delving into the Safety of Federated Large Language Models
作者: Mingxiang Tao, Yu Tian, Wenxuan Tu, Yue Yang, Xue Yang, Xiangyan Tang
分类: cs.CR, cs.AI
发布日期: 2026-01-12
🔗 代码/项目: GITHUB
💡 一句话要点
Safe-FedLLM:提出一种基于探针的联邦LLM防御框架,提升对抗恶意客户端攻击的安全性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大型语言模型 安全性 恶意攻击防御 低秩适应 LoRA 探针检测
📋 核心要点
- 现有联邦学习LLM研究主要关注训练效率,忽略了开放环境中恶意客户端带来的安全威胁。
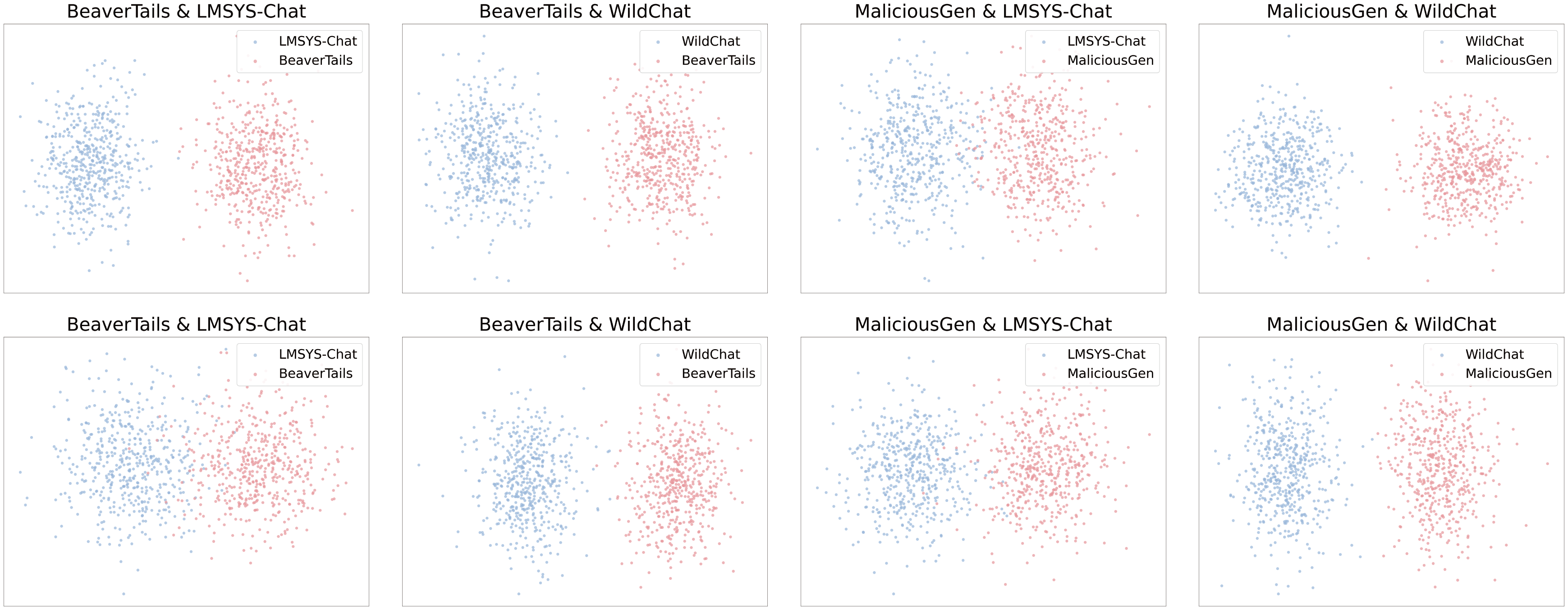
- Safe-FedLLM通过分析LoRA权重,利用其独特的行为模式,设计探针进行恶意客户端检测与防御。
- 实验证明Safe-FedLLM能有效防御恶意攻击,且不显著影响良性数据上的性能和训练速度。
📝 摘要(中文)
联邦学习(FL)解决了大型语言模型(LLM)中的数据隐私和孤岛问题。目前大多数工作集中在提高联邦LLM的训练效率上。然而,开放环境中的安全性被忽视,特别是针对恶意客户端的防御。为了研究FL中LLM的安全性,我们进行了初步实验,从低秩适应(LoRA)权重的角度分析了潜在的攻击面和可防御的特征。我们发现了FL的两个关键属性:1) LLM容易受到FL中恶意客户端的攻击;2) LoRA权重表现出可以通过简单分类器过滤的独特行为模式。基于这些属性,我们提出Safe-FedLLM,一个用于联邦LLM的基于探针的防御框架,构建了跨三个维度的防御:Step-Level、Client-Level和Shadow-Level。Safe-FedLLM的核心概念是对FL期间每个客户端本地训练的LoRA权重进行基于探针的判别,将其视为高维行为特征,并使用轻量级分类模型来确定它们是否具有恶意属性。大量实验表明,Safe-FedLLM有效地增强了联邦LLM的防御能力,而不会影响良性数据的性能。值得注意的是,我们的方法有效地抑制了恶意数据的影响,而不会对训练速度产生重大影响,并且即使在存在许多恶意客户端的情况下仍然有效。我们的代码可在https://github.com/dmqx/Safe-FedLLM获得。
🔬 方法详解
问题定义:论文旨在解决联邦学习场景下,大型语言模型容易受到恶意客户端攻击的安全问题。现有方法主要关注训练效率,缺乏有效的防御机制,导致模型容易受到投毒攻击等恶意行为的影响。恶意客户端可能通过上传精心设计的恶意更新来降低全局模型的性能或引入有害行为。
核心思路:论文的核心思路是利用LoRA(Low-Rank Adaptation)权重在训练过程中表现出的独特行为模式来识别和过滤恶意客户端。通过将LoRA权重视为高维行为特征,并使用轻量级分类模型进行判别,从而实现对恶意客户端的检测。这种方法的核心在于假设恶意客户端的LoRA权重会呈现出与良性客户端不同的统计特征。
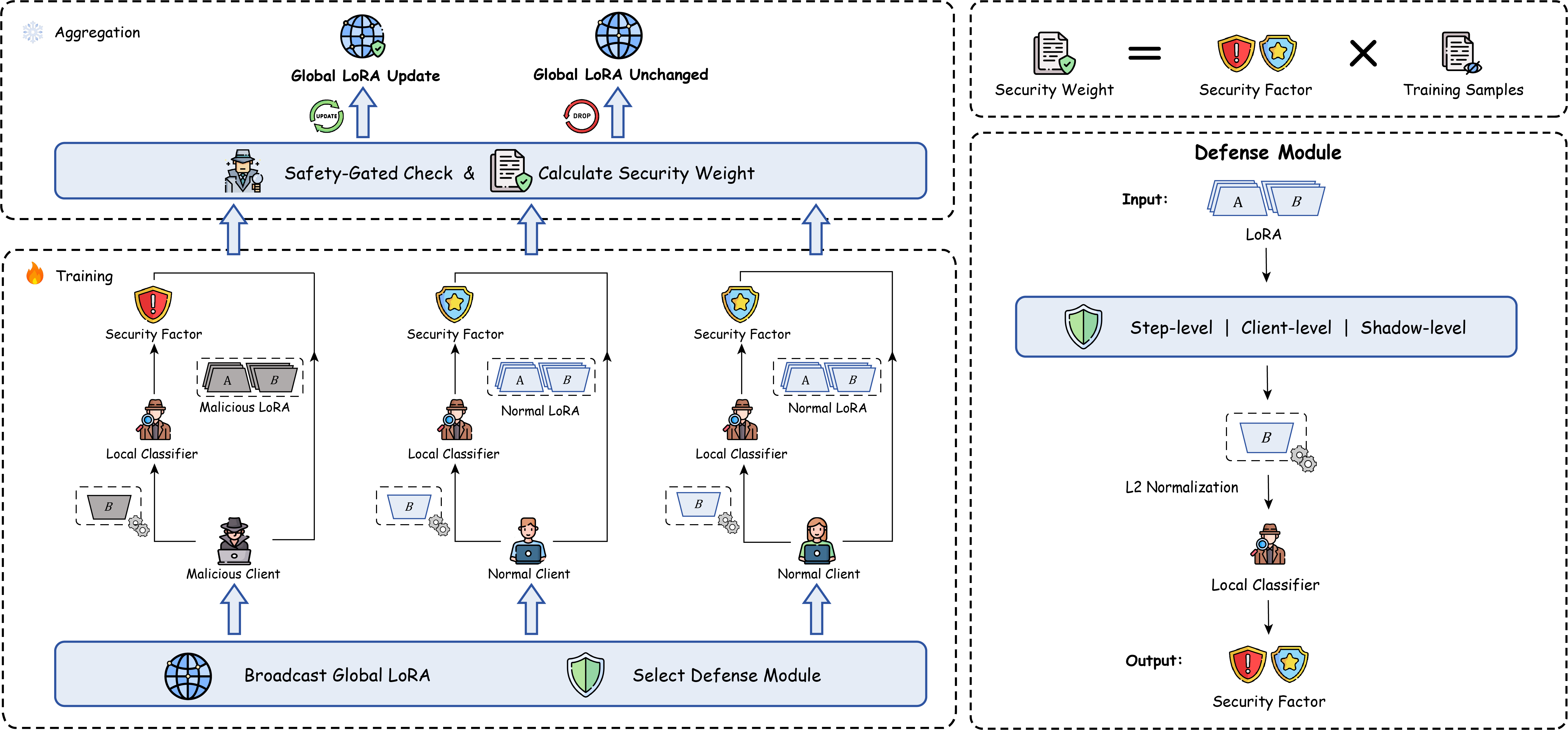
技术框架:Safe-FedLLM框架包含三个主要防御维度:Step-Level、Client-Level和Shadow-Level。Step-Level防御在每个训练步骤中检测恶意更新;Client-Level防御评估每个客户端的整体恶意程度;Shadow-Level防御则通过维护一个影子模型来进一步验证和缓解潜在的攻击。整体流程包括:1) 客户端本地训练LoRA权重;2) 服务器接收LoRA权重并进行探针检测;3) 根据检测结果进行权重聚合或过滤;4) 更新全局模型。
关键创新:Safe-FedLLM的关键创新在于将LoRA权重作为一种行为特征,并利用轻量级分类模型进行恶意客户端检测。与传统的基于梯度的防御方法相比,该方法更加高效且易于实现。此外,Safe-FedLLM提出的三维防御框架能够更全面地应对不同类型的攻击。
关键设计:Safe-FedLLM的关键设计包括:1) 选择合适的探针(分类模型)来区分恶意和良性LoRA权重;2) 设计有效的特征提取方法,将LoRA权重转化为可用于分类的特征向量;3) 确定合适的阈值来判断客户端是否恶意;4) 平衡防御强度和模型性能,避免过度过滤导致模型性能下降。具体的分类模型可以是简单的线性模型或决策树,特征提取方法可以包括统计特征(如均值、方差)或更复杂的表示学习方法。损失函数的设计需要考虑恶意客户端的比例和攻击类型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Safe-FedLLM能够有效防御恶意客户端的攻击,且不会显著影响良性数据上的模型性能。即使在存在多个恶意客户端的情况下,Safe-FedLLM仍然能够保持较高的防御效果。此外,该方法对训练速度的影响较小,具有良好的实用性。具体性能数据未知,但摘要强调了其有效性和效率。
🎯 应用场景
Safe-FedLLM可应用于各种需要联邦学习的大型语言模型场景,例如医疗健康、金融服务等。该方法能够有效提升联邦学习系统的安全性,保护用户数据隐私,并防止恶意攻击对模型性能造成损害。未来可进一步扩展到其他联邦学习任务和模型类型,具有广阔的应用前景。
📄 摘要(原文)
Federated learning (FL) addresses data privacy and silo issues in large language models (LLMs). Most prior work focuses on improving the training efficiency of federated LLMs. However, security in open environments is overlooked, particularly defenses against malicious clients. To investigate the safety of LLMs during FL, we conduct preliminary experiments to analyze potential attack surfaces and defensible characteristics from the perspective of Low-Rank Adaptation (LoRA) weights. We find two key properties of FL: 1) LLMs are vulnerable to attacks from malicious clients in FL, and 2) LoRA weights exhibit distinct behavioral patterns that can be filtered through simple classifiers. Based on these properties, we propose Safe-FedLLM, a probe-based defense framework for federated LLMs, constructing defenses across three dimensions: Step-Level, Client-Level, and Shadow-Level. The core concept of Safe-FedLLM is to perform probe-based discrimination on the LoRA weights locally trained by each client during FL, treating them as high-dimensional behavioral features and using lightweight classification models to determine whether they possess malicious attributes. Extensive experiments demonstrate that Safe-FedLLM effectively enhances the defense capability of federated LLMs without compromising performance on benign data. Notably, our method effectively suppresses malicious data impact without significant impact on training speed, and remains effective even with many malicious clients. Our code is available at: https://github.com/dmqx/Safe-FedLLM.