AscendKernelGen: A Systematic Study of LLM-Based Kernel Generation for Neural Processing Units
作者: Xinzi Cao, Jianyang Zhai, Pengfei Li, Zhiheng Hu, Cen Yan, Bingxu Mu, Guanghuan Fang, Bin She, Jiayu Li, Yihan Su, Dongyang Tao, Xiansong Huang, Fan Xu, Feidiao Yang, Yao Lu, Chang-Dong Wang, Yutong Lu, Weicheng Xue, Bin Zhou, Yonghong Tian
分类: cs.AI, cs.LG
发布日期: 2026-01-12
备注: 33 pages,7 figures,16 tables
💡 一句话要点
AscendKernelGen:面向昇腾NPU的LLM内核生成系统性研究
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: NPU内核生成 大型语言模型 领域自适应 思维链 强化学习 昇腾 代码生成
📋 核心要点
- 现有方法难以利用通用LLM为NPU生成高性能内核,因为NPU编程具有严格约束和数据稀缺性。
- AscendKernelGen框架通过构建高质量数据集Ascend-CoT和领域自适应模型KernelGen-LM来解决NPU内核生成问题。
- 实验表明,该方法显著提高了复杂内核的编译成功率和功能正确性,证明了领域特定推理的重要性。
📝 摘要(中文)
为了满足日益增长的计算效率需求,神经处理单元(NPU)在现代人工智能基础设施中变得至关重要。然而,充分发挥其潜力需要使用特定于供应商的领域特定语言(DSL)开发高性能计算内核,这是一项需要深厚硬件专业知识且劳动密集型的任务。虽然大型语言模型(LLM)在通用代码生成方面显示出前景,但它们在NPU领域中面临严格的约束和稀缺的训练数据。初步研究表明,最先进的通用LLM无法为昇腾NPU生成功能性复杂内核,成功率接近于零。为了应对这些挑战,我们提出了AscendKernelGen,一个用于NPU内核生成的集成生成-评估框架。我们引入了Ascend-CoT,一个高质量数据集,其中包含源自真实内核实现的思维链推理,以及KernelGen-LM,一个通过监督微调和强化学习与执行反馈进行训练的领域自适应模型。此外,我们设计了NPUKernelBench,一个用于评估不同复杂程度下的编译、正确性和性能的综合基准。实验结果表明,我们的方法显著弥合了通用LLM和硬件特定编码之间的差距。具体而言,复杂Level-2内核的编译成功率从0%提高到95.5%(Pass@10),而功能正确性达到64.3%,而基线完全失败。这些结果突出了领域特定推理和严格评估在自动化加速器感知代码生成中的关键作用。
🔬 方法详解
问题定义:论文旨在解决通用LLM在昇腾NPU内核生成上的失败问题。现有方法难以生成功能正确的复杂内核,因为NPU编程依赖于特定厂商的DSL,需要深厚的硬件知识,且缺乏足够的训练数据。这导致通用LLM在面对NPU的严格约束时表现不佳。
核心思路:论文的核心思路是构建一个集生成和评估于一体的框架,并利用领域特定的数据和训练方法来提升LLM在NPU内核生成上的能力。通过引入高质量的思维链数据集和领域自适应模型,使LLM能够更好地理解和生成符合NPU规范的代码。
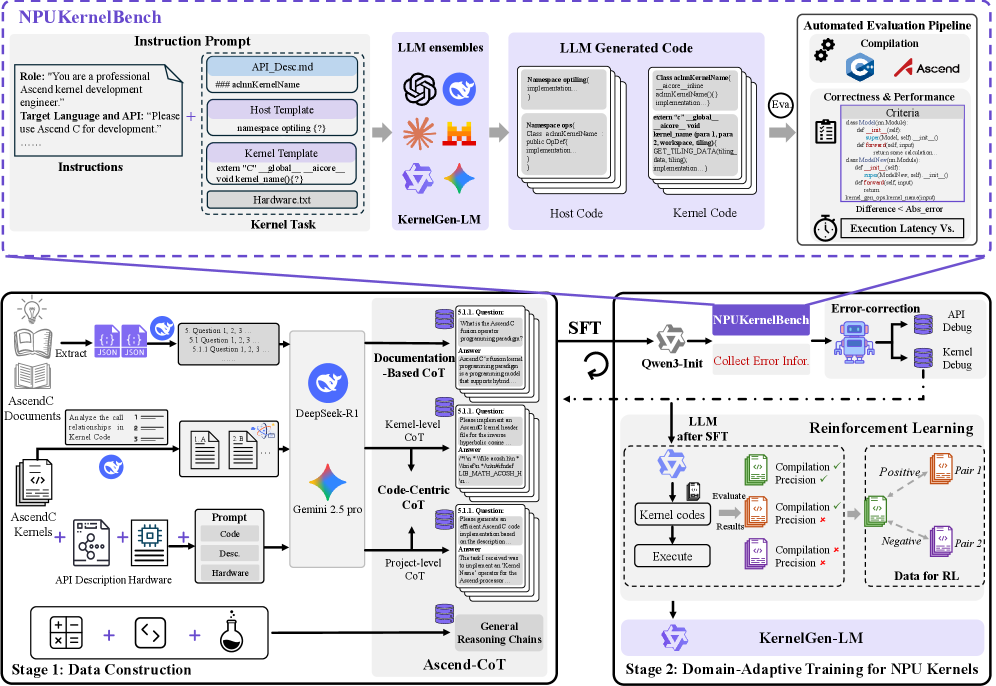
技术框架:AscendKernelGen框架包含以下主要模块:1) Ascend-CoT数据集构建,用于提供高质量的NPU内核生成训练数据;2) KernelGen-LM模型训练,通过监督微调和强化学习,使模型适应NPU内核生成的领域;3) NPUKernelBench基准测试,用于评估生成的内核的编译、正确性和性能。整个流程通过生成、评估和反馈循环,不断优化LLM的生成能力。
关键创新:该论文的关键创新在于:1) 提出了Ascend-CoT数据集,该数据集包含真实NPU内核实现的思维链推理,为LLM提供了高质量的训练数据;2) 开发了KernelGen-LM模型,通过领域自适应训练,显著提升了LLM在NPU内核生成上的性能;3) 构建了NPUKernelBench基准测试,为评估NPU内核生成模型的性能提供了全面的评估标准。
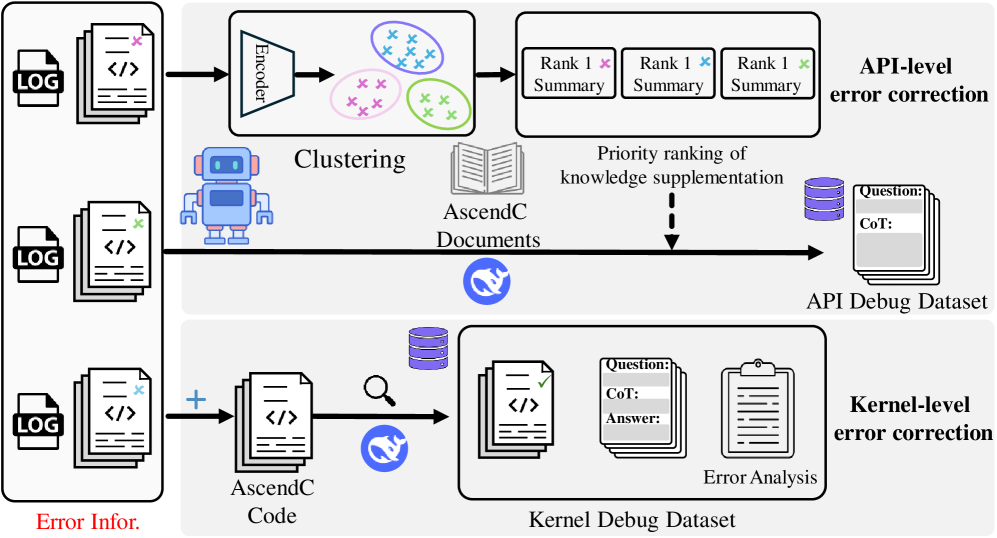
关键设计:Ascend-CoT数据集通过人工标注和专家知识,构建了包含思维链推理的NPU内核生成示例。KernelGen-LM模型采用监督微调和强化学习相结合的训练方法,其中强化学习使用执行反馈作为奖励信号,以优化生成的内核的正确性和性能。NPUKernelBench基准测试包含不同复杂程度的内核生成任务,并评估编译成功率、功能正确性和性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AscendKernelGen框架显著提升了NPU内核生成的性能。在复杂的Level-2内核上,编译成功率从0%提升到95.5%(Pass@10),功能正确性达到64.3%,而基线方法完全失败。这些数据表明,该方法在自动化NPU内核生成方面具有显著优势。
🎯 应用场景
该研究成果可应用于自动化NPU内核开发,降低开发门槛,加速AI应用在NPU上的部署。通过自动化生成高性能内核,可以提升NPU的利用率和计算效率,从而推动人工智能技术在各个领域的应用,例如智能交通、智慧医疗和智能制造等。
📄 摘要(原文)
To meet the ever-increasing demand for computational efficiency, Neural Processing Units (NPUs) have become critical in modern AI infrastructure. However, unlocking their full potential requires developing high-performance compute kernels using vendor-specific Domain-Specific Languages (DSLs), a task that demands deep hardware expertise and is labor-intensive. While Large Language Models (LLMs) have shown promise in general code generation, they struggle with the strict constraints and scarcity of training data in the NPU domain. Our preliminary study reveals that state-of-the-art general-purpose LLMs fail to generate functional complex kernels for Ascend NPUs, yielding a near-zero success rate. To address these challenges, we propose AscendKernelGen, a generation-evaluation integrated framework for NPU kernel development. We introduce Ascend-CoT, a high-quality dataset incorporating chain-of-thought reasoning derived from real-world kernel implementations, and KernelGen-LM, a domain-adaptive model trained via supervised fine-tuning and reinforcement learning with execution feedback. Furthermore, we design NPUKernelBench, a comprehensive benchmark for assessing compilation, correctness, and performance across varying complexity levels. Experimental results demonstrate that our approach significantly bridges the gap between general LLMs and hardware-specific coding. Specifically, the compilation success rate on complex Level-2 kernels improves from 0% to 95.5% (Pass@10), while functional correctness achieves 64.3% compared to the baseline's complete failure. These results highlight the critical role of domain-specific reasoning and rigorous evaluation in automating accelerator-aware code generation.