Rewarding Creativity: A Human-Aligned Generative Reward Model for Reinforcement Learning in Storytelling
作者: Zhaoyan Li, Hang Lei, Yujia Wang, Lanbo Liu, Hao Liu, Liang Yu
分类: cs.AI, cs.CL
发布日期: 2026-01-12
💡 一句话要点
提出人类对齐的生成奖励模型以解决创意故事生成中的挑战
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成奖励模型 强化学习 创意故事生成 人类对齐 奖励塑形策略
📋 核心要点
- 现有方法在创意故事生成中缺乏可靠的奖励信号,导致主观质量评估困难,且训练过程不稳定。
- 提出了生成奖励模型(GenRM)和基于熵的奖励塑形策略,前者通过多维分析和推理链进行训练,后者动态调整学习重点。
- 实验结果显示,GenRM与人类创意判断的对齐度为68%,且RLCS在故事质量上显著超越了Gemini-2.5-Pro等基线模型。
📝 摘要(中文)
尽管大型语言模型(LLMs)能够生成流畅的文本,但创作高质量的创意故事仍然具有挑战性。强化学习(RL)提供了一个有前景的解决方案,但面临两个关键障碍:设计可靠的奖励信号以评估主观故事质量,以及减轻训练不稳定性。本文提出了创意故事强化学习(RLCS)框架,系统性地解决这两个挑战。首先,开发了生成奖励模型(GenRM),通过对故事偏好的多维分析和明确推理进行训练,随后基于扩展偏好数据进行GRPO优化。其次,引入了一种基于熵的奖励塑形策略,动态优先学习自信错误和不确定的正确预测,防止对已掌握模式的过拟合。实验表明,GenRM与人类创意判断的对齐度达到68%,RLCS在整体故事质量上显著优于包括Gemini-2.5-Pro在内的强基线。
🔬 方法详解
问题定义:本论文旨在解决创意故事生成中的奖励信号设计和训练不稳定性问题。现有方法往往无法有效评估故事的主观质量,导致生成结果不理想。
核心思路:论文提出的RLCS框架通过生成奖励模型(GenRM)和熵基奖励塑形策略,系统性地解决了奖励建模和训练稳定性的问题。GenRM通过多维度分析和推理链的训练,提供了更为可靠的奖励信号。
技术框架:RLCS框架包括两个主要模块:生成奖励模型(GenRM)和熵基奖励塑形策略。GenRM首先通过监督微调和教师模型的推理链进行训练,随后在扩展的偏好数据上进行GRPO优化。熵基奖励塑形策略则在训练过程中动态调整学习重点。
关键创新:最重要的技术创新在于生成奖励模型(GenRM)的设计,它通过多维度分析和明确推理来评估故事质量,与传统的单一奖励信号设计有本质区别。
关键设计:在GenRM的训练中,采用了监督微调和GRPO优化的组合,确保模型能够在多样化的偏好数据上进行有效学习。同时,熵基奖励塑形策略通过动态调整学习重点,避免了对已掌握模式的过拟合。
🖼️ 关键图片


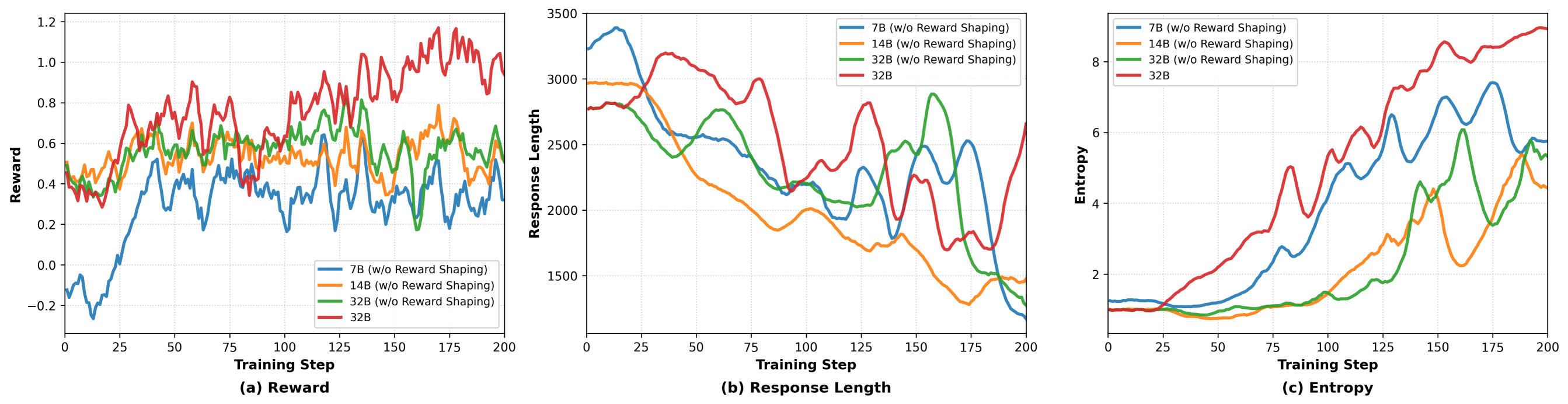
📊 实验亮点
实验结果表明,生成奖励模型(GenRM)与人类创意判断的对齐度达到68%,而RLCS在整体故事质量上显著超越了Gemini-2.5-Pro等强基线,展示了其在创意故事生成中的有效性和优势。
🎯 应用场景
该研究的潜在应用领域包括创意写作、游戏设计和教育等。通过提供有效的奖励信号和稳定的训练过程,RLCS框架能够帮助生成更具创意和吸引力的故事,推动相关领域的发展与创新。未来,该方法有望在更广泛的创意生成任务中得到应用。
📄 摘要(原文)
While Large Language Models (LLMs) can generate fluent text, producing high-quality creative stories remains challenging. Reinforcement Learning (RL) offers a promising solution but faces two critical obstacles: designing reliable reward signals for subjective storytelling quality and mitigating training instability. This paper introduces the Reinforcement Learning for Creative Storytelling (RLCS) framework to systematically address both challenges. First, we develop a Generative Reward Model (GenRM) that provides multi-dimensional analysis and explicit reasoning about story preferences, trained through supervised fine-tuning on demonstrations with reasoning chains distilled from strong teacher models, followed by GRPO-based refinement on expanded preference data. Second, we introduce an entropy-based reward shaping strategy that dynamically prioritizes learning on confident errors and uncertain correct predictions, preventing overfitting on already-mastered patterns. Experiments demonstrate that GenRM achieves 68\% alignment with human creativity judgments, and RLCS significantly outperforms strong baselines including Gemini-2.5-Pro in overall story quality. This work provides a practical pipeline for applying RL to creative domains, effectively navigating the dual challenges of reward modeling and training stability.