Enhancing Cloud Network Resilience via a Robust LLM-Empowered Multi-Agent Reinforcement Learning Framework
作者: Yixiao Peng, Hao Hu, Feiyang Li, Xinye Cao, Yingchang Jiang, Jipeng Tang, Guoshun Nan, Yuling Liu
分类: cs.CR, cs.AI, cs.LG
发布日期: 2026-01-12
💡 一句话要点
提出CyberOps-Bots,一种基于LLM的多智能体强化学习框架,提升云网络弹性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 云网络安全 多智能体强化学习 大型语言模型 人机协同 网络弹性
📋 核心要点
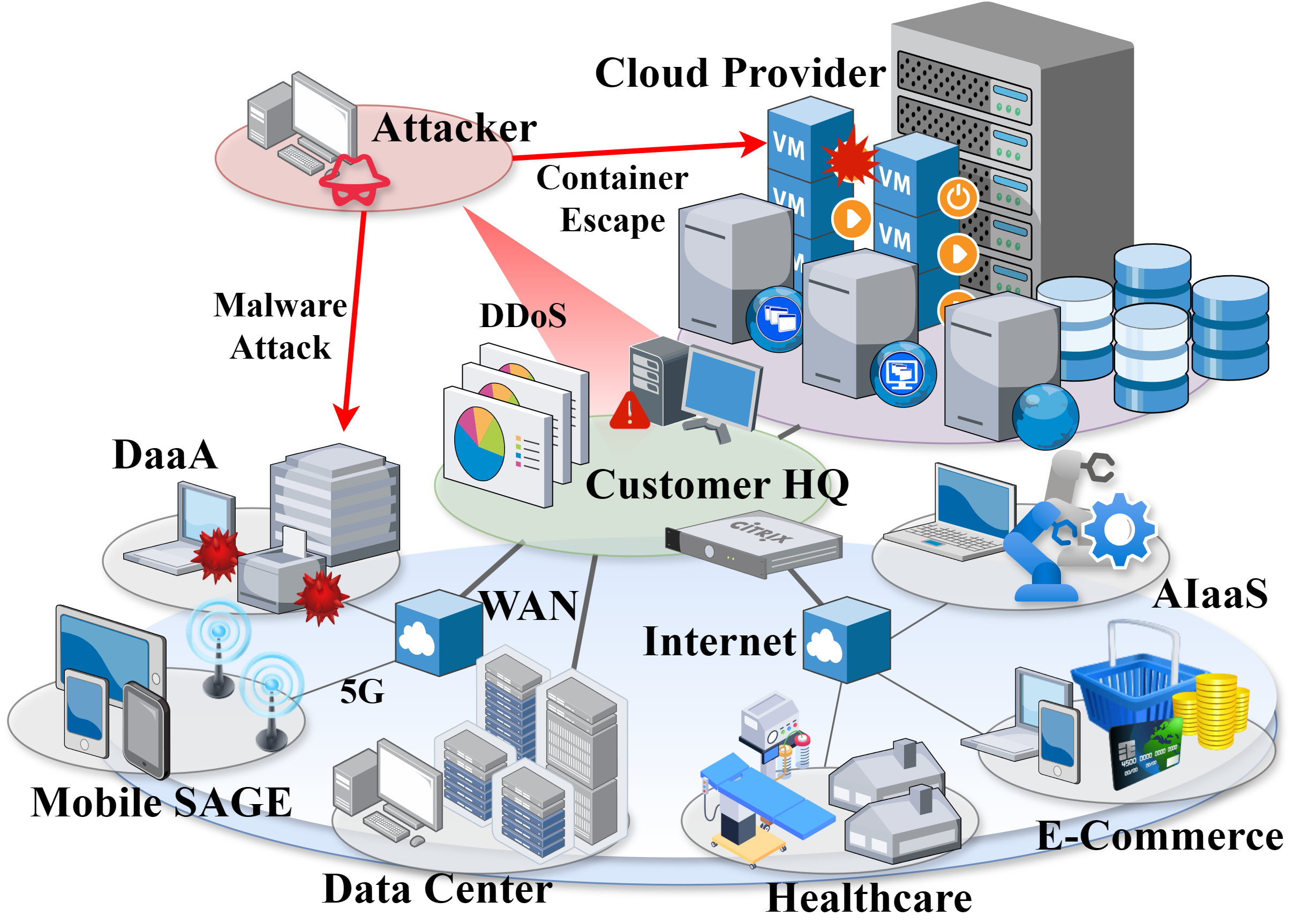
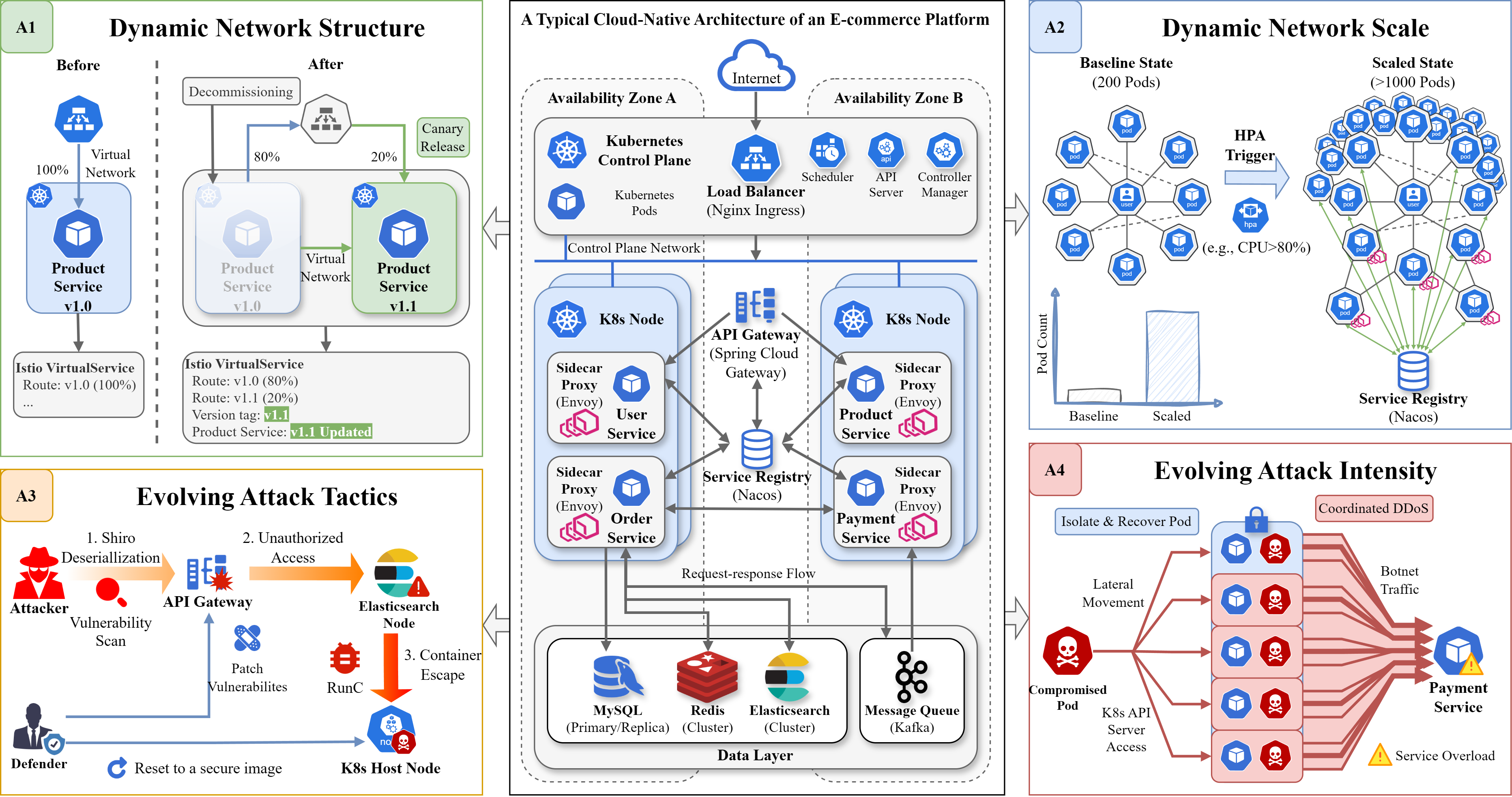
- 现有基于强化学习的云网络防御策略缺乏鲁棒性,难以适应动态变化的网络环境和攻击模式,需要大量重新训练。
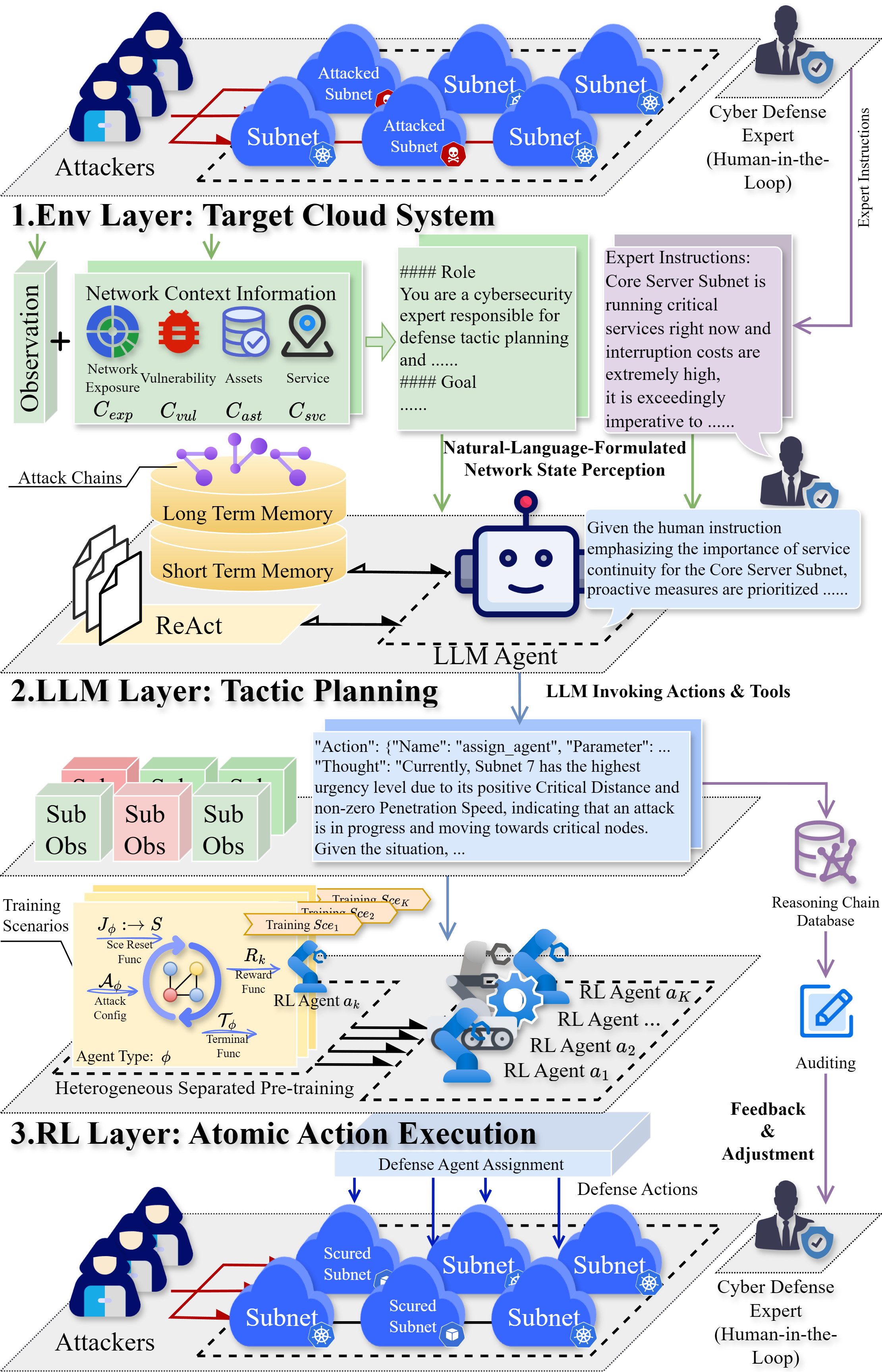
- CyberOps-Bots提出一种分层多智能体强化学习框架,上层LLM负责全局规划和人机交互,下层RL智能体执行局部防御,实现鲁棒性和可解释性。
- 实验结果表明,CyberOps-Bots在网络可用性和启动性能方面显著优于现有算法,无需重新训练即可适应新场景。
📝 摘要(中文)
云网络通过虚拟化和资源池化实现了结构灵活性和弹性可扩展性,但也因此扩大了攻击面,对网络弹性提出了挑战。基于强化学习(RL)的防御策略旨在通过维护和恢复网络可用性来增强系统弹性,但现有方法缺乏鲁棒性,需要重新训练以适应网络结构、节点规模、攻击策略和攻击强度的动态变化。此外,缺乏人机协同(HITL)支持限制了解释性和灵活性。为了解决这些限制,我们提出了CyberOps-Bots,一个由大型语言模型(LLM)驱动的分层多智能体强化学习框架。CyberOps-Bots采用受MITRE ATT&CK启发的两层架构:上层LLM智能体执行全局感知、人类意图识别和战术规划;下层RL智能体在局部网络区域内执行原子防御动作。实验表明,与现有算法相比,CyberOps-Bots在不重新训练的情况下,网络可用性提高了68.5%,场景切换时的启动性能增益达到34.7%。
🔬 方法详解
问题定义:现有基于强化学习的云网络防御方法,在面对动态变化的网络环境(如网络结构变化、节点规模变化、攻击策略变化等)时,需要进行大量的重新训练,缺乏鲁棒性。此外,缺乏人机协同机制,导致防御策略的可解释性和灵活性不足。
核心思路:论文的核心思路是结合大型语言模型(LLM)的强大泛化能力和强化学习(RL)的决策能力,构建一个分层多智能体防御框架。LLM负责全局态势感知、人类意图理解和战术规划,RL智能体负责局部防御动作的执行。这种分层结构旨在利用LLM的灵活性和RL的可靠性,从而提高防御系统的鲁棒性和可解释性。
技术框架:CyberOps-Bots框架包含两个主要层次:(1) 上层LLM智能体:包含ReAct规划模块、基于IPDRR的感知模块、长短期记忆模块和动作/工具集成模块,负责全局感知、人类意图识别和战术规划。(2) 下层RL智能体:通过异构分离预训练开发,在局部网络区域内执行原子防御动作。上下层智能体协同工作,共同完成云网络防御任务。
关键创新:该论文的关键创新在于将大型语言模型(LLM)与多智能体强化学习(MARL)相结合,构建了一个鲁棒的云网络防御框架。与传统的RL方法相比,该框架能够更好地适应动态变化的网络环境,并且支持人机协同,提高了防御策略的可解释性和灵活性。这是首次将LLM-RL框架应用于云防御领域。
关键设计:上层LLM智能体使用ReAct框架进行规划,利用IPDRR(Identify, Predict, Decide, Respond, Recover)模型进行感知,并使用长短期记忆网络(LSTM)来处理时序信息。下层RL智能体采用异构分离预训练方法,针对不同的网络区域和攻击类型进行专门训练。具体的参数设置、损失函数和网络结构等技术细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CyberOps-Bots在真实云数据集上表现出色。与现有算法相比,CyberOps-Bots在不重新训练的情况下,网络可用性提高了68.5%,并且在场景切换时实现了34.7%的启动性能增益。这些数据表明,该框架具有很强的鲁棒性和泛化能力,能够有效地应对动态变化的云网络环境。
🎯 应用场景
该研究成果可应用于各种云网络安全场景,例如入侵检测与防御、漏洞修复、安全策略优化等。通过自动化和智能化防御,可以有效降低云网络的安全风险,提高系统的可用性和可靠性。该框架还支持人机协同,允许安全专家参与决策过程,从而提高防御策略的灵活性和可解释性。未来,该研究有望推动云网络安全防御技术的进一步发展。
📄 摘要(原文)
While virtualization and resource pooling empower cloud networks with structural flexibility and elastic scalability, they inevitably expand the attack surface and challenge cyber resilience. Reinforcement Learning (RL)-based defense strategies have been developed to optimize resource deployment and isolation policies under adversarial conditions, aiming to enhance system resilience by maintaining and restoring network availability. However, existing approaches lack robustness as they require retraining to adapt to dynamic changes in network structure, node scale, attack strategies, and attack intensity. Furthermore, the lack of Human-in-the-Loop (HITL) support limits interpretability and flexibility. To address these limitations, we propose CyberOps-Bots, a hierarchical multi-agent reinforcement learning framework empowered by Large Language Models (LLMs). Inspired by MITRE ATT&CK's Tactics-Techniques model, CyberOps-Bots features a two-layer architecture: (1) An upper-level LLM agent with four modules--ReAct planning, IPDRR-based perception, long-short term memory, and action/tool integration--performs global awareness, human intent recognition, and tactical planning; (2) Lower-level RL agents, developed via heterogeneous separated pre-training, execute atomic defense actions within localized network regions. This synergy preserves LLM adaptability and interpretability while ensuring reliable RL execution. Experiments on real cloud datasets show that, compared to state-of-the-art algorithms, CyberOps-Bots maintains network availability 68.5% higher and achieves a 34.7% jumpstart performance gain when shifting the scenarios without retraining. To our knowledge, this is the first study to establish a robust LLM-RL framework with HITL support for cloud defense. We will release our framework to the community, facilitating the advancement of robust and autonomous defense in cloud networks.