Enhancing Retrieval-Augmented Generation with Topic-Enriched Embeddings: A Hybrid Approach Integrating Traditional NLP Techniques
作者: Rodrigo Kataishi
分类: cs.IR, cs.AI
发布日期: 2025-12-31
💡 一句话要点
提出主题增强嵌入,融合传统NLP技术,提升检索增强生成效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 主题建模 文本嵌入 信息检索 自然语言处理
📋 核心要点
- 现有RAG系统在主题复杂语料库中检索质量下降,无法有效利用外部知识。
- 提出主题增强嵌入,融合TF-IDF、主题模型和上下文嵌入,捕捉多层次语义。
- 实验表明,该方法在法律文本检索中提升了聚类一致性和检索精度,降低计算负担。
📝 摘要(中文)
检索增强生成(RAG)系统依赖于精确的文档检索,以便将大型语言模型(LLM)与外部知识相结合。然而,在主题重叠和主题变化高的语料库中,检索质量通常会下降。本研究提出了主题增强嵌入,将基于术语的信号和主题结构与上下文句子嵌入相结合。该方法结合了TF-IDF与主题建模和降维技术,使用潜在语义分析(LSA)和潜在狄利克雷分配(LDA)来编码潜在的主题组织,并将这些表示与紧凑的上下文编码器(all-MiniLM)融合。通过共同捕获术语级别和主题级别的语义,主题增强嵌入提高了语义聚类,提高了检索精度,并降低了相对于纯上下文基线的计算负担。在法律文本语料库上的实验表明,聚类一致性和检索指标均得到持续提升,表明主题增强嵌入可以作为更可靠的知识密集型RAG管道的实用组件。
🔬 方法详解
问题定义:论文旨在解决RAG系统中,由于文档主题重叠和主题变化大,导致检索质量下降的问题。现有方法,如单纯依赖上下文嵌入的方法,无法有效区分语义相似但主题不同的文档,导致检索精度不高,且计算成本较高。
核心思路:论文的核心思路是将传统的基于词项的统计方法(TF-IDF)和主题模型(LSA/LDA)与现代的上下文嵌入方法(all-MiniLM)相结合,从而在嵌入向量中同时编码词项级别的语义信息和主题级别的语义信息。这样可以更全面地表示文档的语义,提高检索的准确性和效率。
技术框架:整体框架包括以下几个主要阶段:1) 使用TF-IDF提取文档的词项特征;2) 使用LSA或LDA进行主题建模,得到文档的主题表示;3) 使用all-MiniLM生成文档的上下文嵌入;4) 将TF-IDF特征、主题表示和上下文嵌入进行融合,得到最终的主题增强嵌入。检索时,使用主题增强嵌入计算文档之间的相似度,并返回相似度最高的文档。
关键创新:该方法最重要的创新点在于将传统的NLP技术(TF-IDF、LSA/LDA)与现代的深度学习技术(上下文嵌入)相结合,从而在嵌入向量中同时编码了词项级别的语义信息和主题级别的语义信息。与仅使用上下文嵌入的方法相比,该方法能够更好地捕捉文档的语义信息,提高检索的准确性和效率。
关键设计:论文中使用了all-MiniLM作为上下文编码器,因为它具有较小的模型尺寸和较高的性能。在融合TF-IDF特征、主题表示和上下文嵌入时,可以使用不同的融合策略,例如简单的拼接或加权平均。论文中可能还涉及到一些超参数的调整,例如LSA/LDA的主题数量、TF-IDF的词频阈值等。具体的损失函数和网络结构取决于融合策略的选择,论文中应该有详细的描述。
🖼️ 关键图片
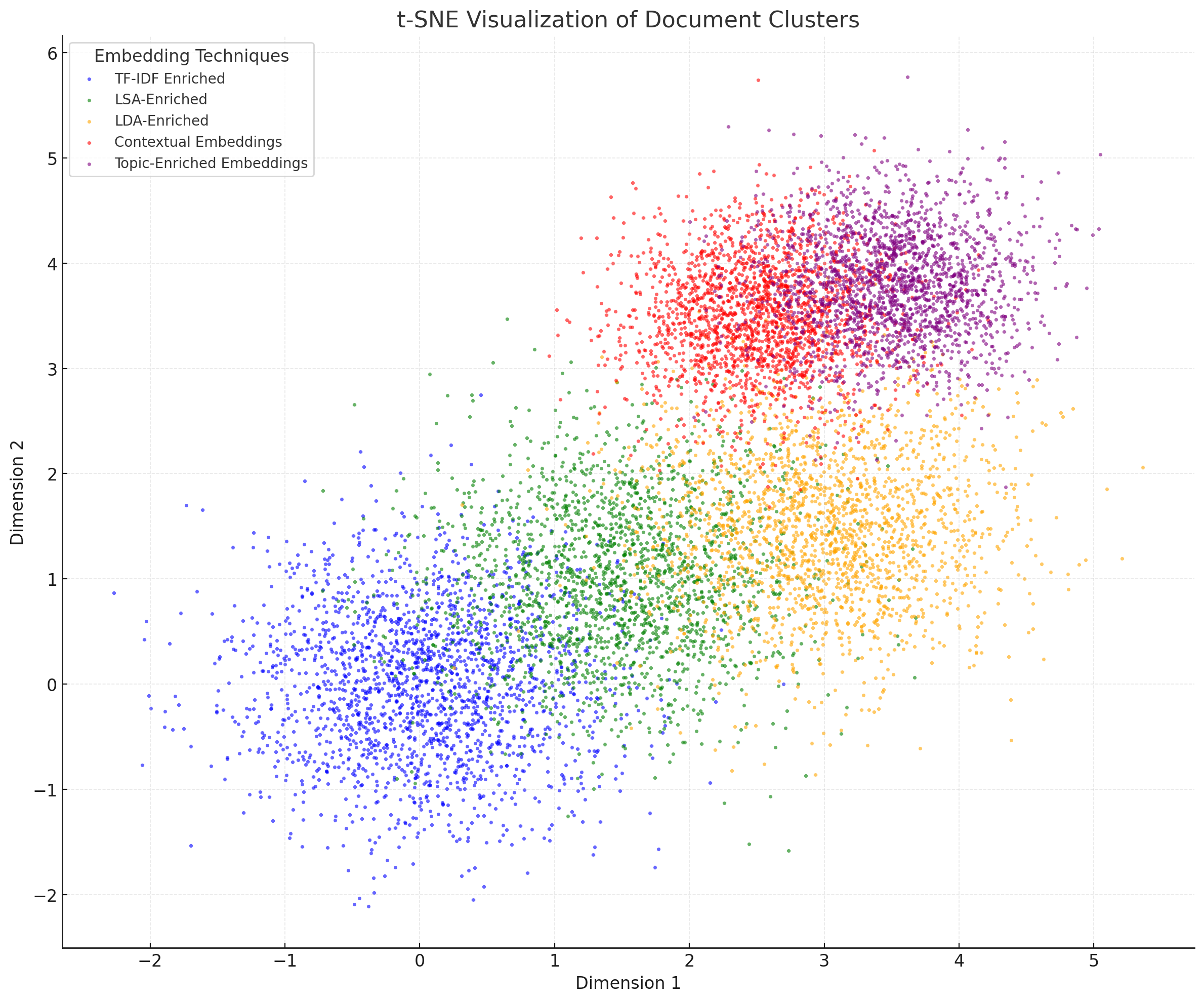
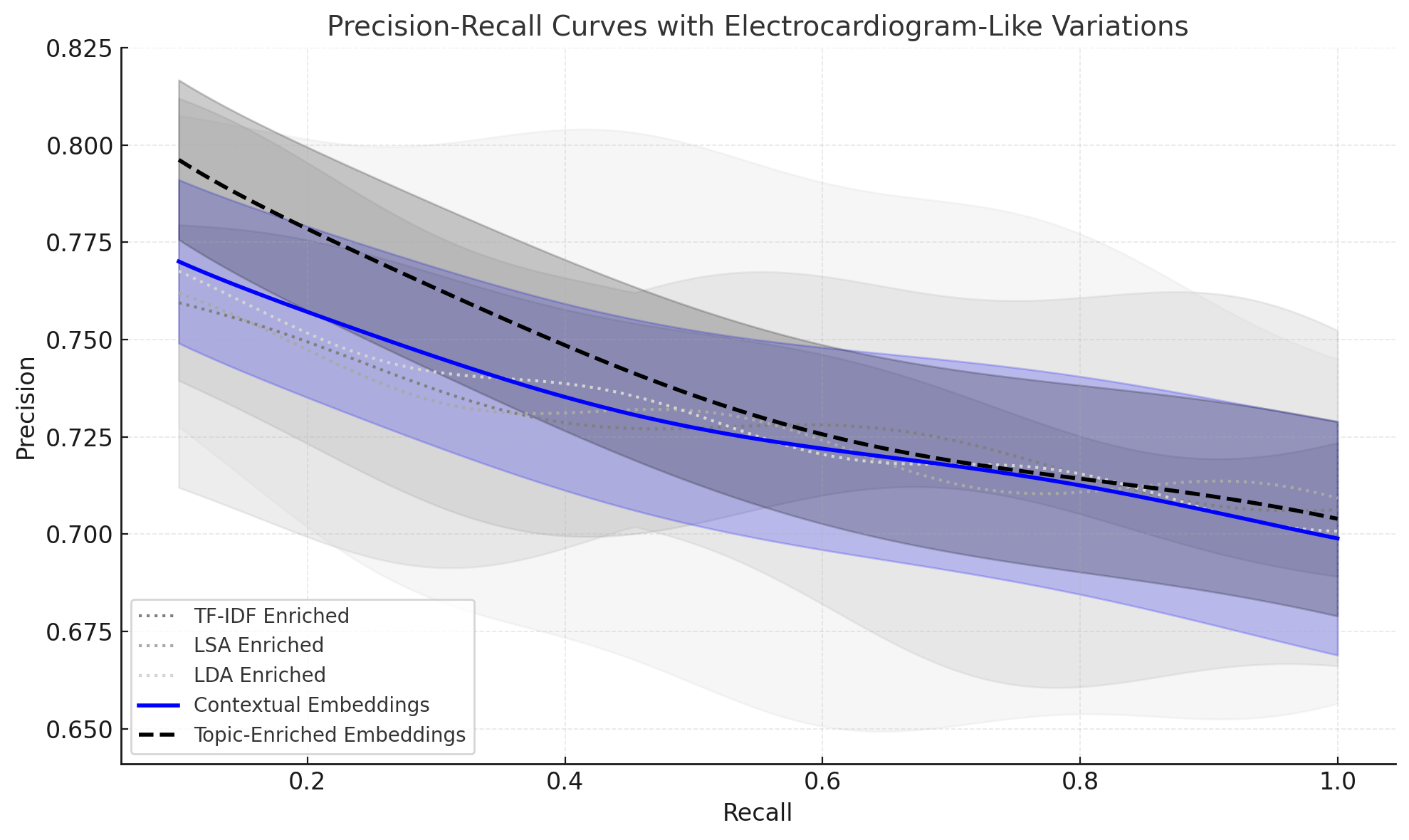
📊 实验亮点
实验结果表明,在法律文本语料库上,主题增强嵌入在聚类一致性和检索指标上均优于纯上下文嵌入基线。具体而言,该方法提高了检索精度,并降低了计算负担。这些结果表明,主题增强嵌入可以作为RAG管道的有效组成部分,提高知识检索的可靠性。
🎯 应用场景
该研究成果可应用于各种知识密集型RAG系统中,尤其是在处理主题复杂、领域知识丰富的文档时,例如法律、医学、金融等领域。通过提高检索精度,可以提升LLM生成内容的质量和可靠性,减少幻觉问题。未来,该方法可以扩展到其他模态的数据,例如图像和音频,构建更强大的多模态RAG系统。
📄 摘要(原文)
Retrieval-augmented generation (RAG) systems rely on accurate document retrieval to ground large language models (LLMs) in external knowledge, yet retrieval quality often degrades in corpora where topics overlap and thematic variation is high. This work proposes topic-enriched embeddings that integrate term-based signals and topic structure with contextual sentence embeddings. The approach combines TF-IDF with topic modeling and dimensionality reduction, using Latent Semantic Analysis (LSA) and Latent Dirichlet Allocation (LDA) to encode latent topical organization, and fuses these representations with a compact contextual encoder (all-MiniLM). By jointly capturing term-level and topic-level semantics, topic-enriched embeddings improve semantic clustering, increase retrieval precision, and reduce computational burden relative to purely contextual baselines. Experiments on a legal-text corpus show consistent gains in clustering coherence and retrieval metrics, suggesting that topic-enriched embeddings can serve as a practical component for more reliable knowledge-intensive RAG pipelines.