Recursive Language Models
作者: Alex L. Zhang, Tim Kraska, Omar Khattab
分类: cs.AI, cs.CL
发布日期: 2025-12-31 (更新: 2026-01-28)
备注: 9 pages, 33 with Appendix
🔗 代码/项目: GITHUB
💡 一句话要点
提出递归语言模型(RLM),通过推理时扩展处理超长上下文,显著提升长文本任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 递归语言模型 长上下文处理 大型语言模型 推理时扩展 Qwen3-8B 长文本理解 环境交互 提示分解
📋 核心要点
- 现有LLM受限于固定长度的上下文窗口,难以有效处理超长文本,限制了其应用场景。
- RLM将长文本提示视为外部环境,允许LLM递归调用自身处理文本片段,突破了上下文长度限制。
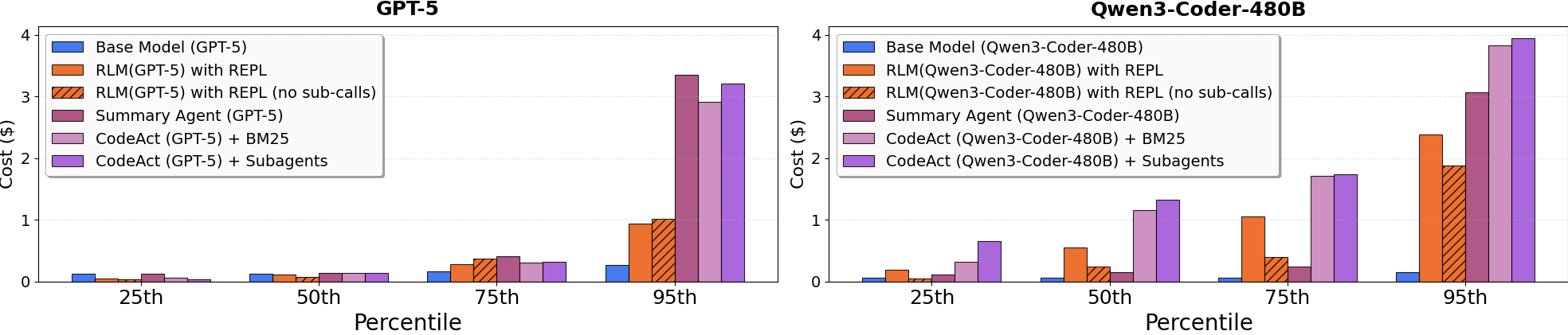
- 实验表明,RLM在长文本任务上显著优于传统LLM,甚至接近GPT-5的性能,且成本可控。
📝 摘要(中文)
本文研究了通过推理时扩展来允许大型语言模型(LLMs)处理任意长度的提示。我们提出递归语言模型(RLMs),这是一种通用的推理范式,它将长提示视为外部环境的一部分,并允许LLM以编程方式检查、分解提示,并递归地调用自身来处理提示片段。我们发现,RLMs可以成功处理比模型上下文窗口大两个数量级的输入,并且即使对于较短的提示,在四个不同的长上下文任务中,其质量也显著优于原始的前沿LLM和常见的长上下文支架,同时具有可比的成本。在一个小规模上,我们对第一个原生递归语言模型进行了后训练。我们的模型RLM-Qwen3-8B,平均比底层Qwen3-8B模型高出28.3%,甚至在三个长上下文任务中接近原始GPT-5的质量。代码可在https://github.com/alexzhang13/rlm获得。
🔬 方法详解
问题定义:现有大型语言模型(LLMs)在处理超长文本时面临上下文窗口的限制。这意味着模型无法一次性处理超过其预定义长度的输入,导致信息丢失或性能下降。现有的长上下文处理方法,例如截断、滑动窗口等,要么损失信息,要么效率低下,无法充分利用长文本中的信息。
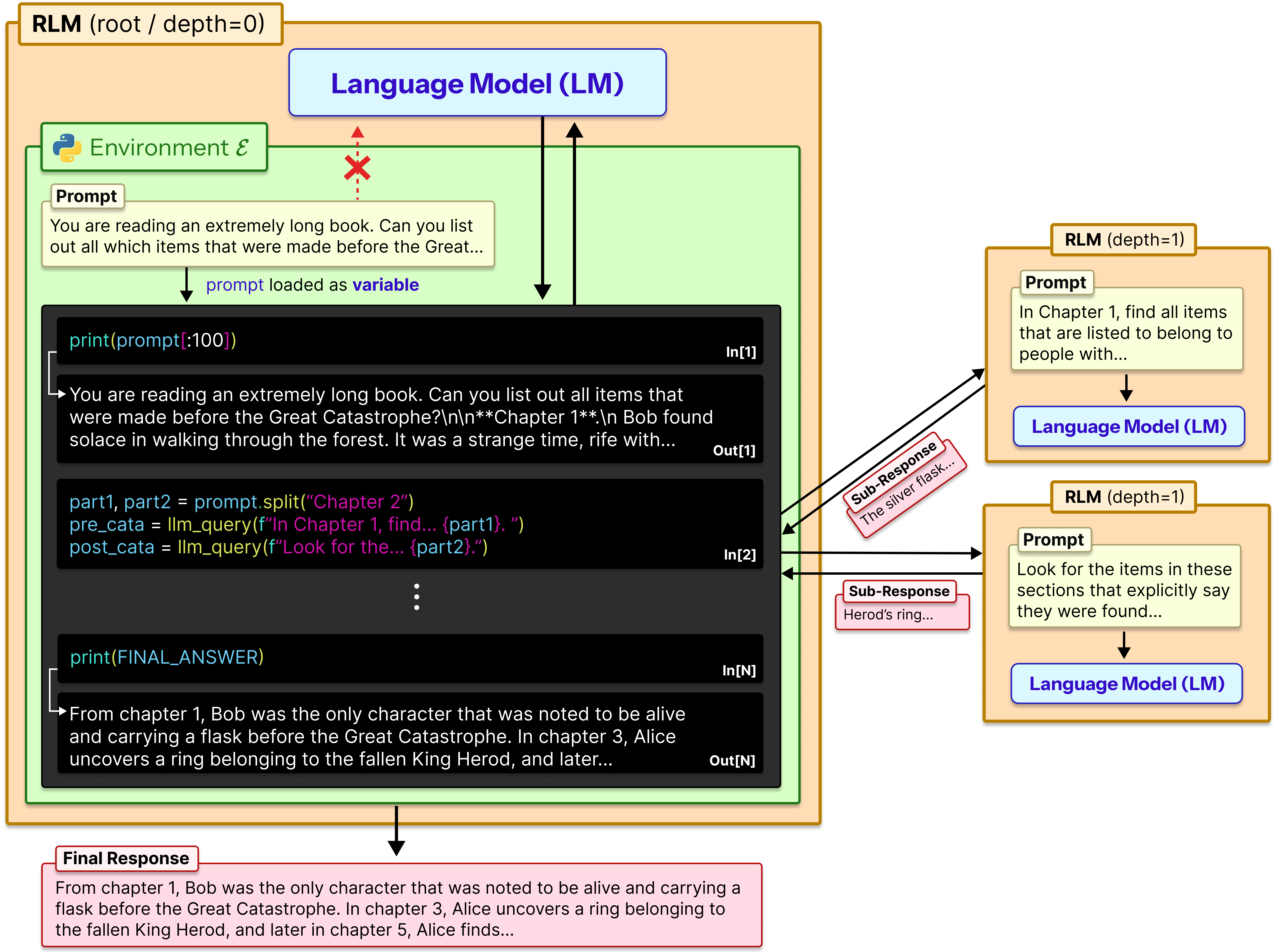
核心思路:RLM的核心思路是将长文本提示视为一个外部环境,允许LLM以编程方式与这个环境交互。具体来说,LLM可以分解长提示,选择性地提取关键信息,并递归地调用自身来处理不同的文本片段。这种递归处理方式使得模型能够逐步理解和整合长文本中的信息,突破了上下文窗口的限制。
技术框架:RLM的整体框架包含以下几个主要模块:1) 环境交互模块:负责将长文本提示呈现给LLM,并提供访问和操作提示的接口。2) 控制模块:LLM本身,它接收环境信息,并决定下一步的操作,例如分解提示、提取信息或递归调用自身。3) 递归调用模块:允许LLM在处理提示片段时,再次调用自身来进一步分析和理解。整个流程类似于一个程序,LLM通过编程的方式逐步处理长文本。
关键创新:RLM最重要的创新在于其递归处理长文本的方式。与传统的线性处理方式不同,RLM允许模型根据文本内容动态地调整处理策略,从而更有效地利用长文本中的信息。此外,RLM还引入了环境交互的概念,使得LLM能够以更灵活的方式与外部信息进行交互。
关键设计:RLM的关键设计包括:1) 提示分解策略:如何将长提示分解成更小的片段,以便LLM能够逐个处理。2) 信息提取策略:如何从提示片段中提取关键信息,并将其整合到模型的记忆中。3) 递归调用深度:递归调用的次数,需要根据任务的复杂程度进行调整。论文中使用了Qwen3-8B作为基础模型,并对其进行了后训练,使其能够原生支持递归调用。具体的损失函数和网络结构细节未在摘要中详细说明,需要参考论文全文。
🖼️ 关键图片

📊 实验亮点
RLM-Qwen3-8B模型在长上下文任务上表现出色,平均比底层Qwen3-8B模型高出28.3%。在三个长上下文任务中,RLM-Qwen3-8B甚至接近原始GPT-5的性能。这些结果表明,RLM是一种有效的长上下文处理方法,能够显著提升LLM的性能。
🎯 应用场景
RLM具有广泛的应用前景,例如长篇文档摘要、复杂问答、代码理解和生成、以及需要处理大量上下文信息的对话系统。通过突破上下文长度的限制,RLM可以更好地理解和利用长文本中的信息,从而提升各种自然语言处理任务的性能。未来,RLM有望应用于法律、金融、医疗等领域,帮助人们更有效地处理和分析海量信息。
📄 摘要(原文)
We study allowing large language models (LLMs) to process arbitrarily long prompts through the lens of inference-time scaling. We propose Recursive Language Models (RLMs), a general inference paradigm that treats long prompts as part of an external environment and allows the LLM to programmatically examine, decompose, and recursively call itself over snippets of the prompt. We find that RLMs can successfully process inputs up to two orders of magnitude beyond model context windows and, even for shorter prompts, dramatically outperform the quality of vanilla frontier LLMs and common long-context scaffolds across four diverse long-context tasks while having comparable cost. At a small scale, we post-train the first natively recursive language model. Our model, RLM-Qwen3-8B, outperforms the underlying Qwen3-8B model by $28.3\%$ on average and even approaches the quality of vanilla GPT-5 on three long-context tasks. Code is available at https://github.com/alexzhang13/rlm.