MCPAgentBench: A Real-world Task Benchmark for Evaluating LLM Agent MCP Tool Use
作者: Wenrui Liu, Zixiang Liu, Elsie Dai, Wenhan Yu, Lei Yu, Tong Yang, Jinjun Han, Hong Gao
分类: cs.AI
发布日期: 2025-12-31 (更新: 2026-01-21)
💡 一句话要点
提出MCPAgentBench,用于评估LLM Agent在真实MCP工具使用中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 模型上下文协议 工具使用 评估基准 动态沙盒
📋 核心要点
- 现有MCP评估依赖外部服务且缺乏难度分级,难以有效评估Agent的工具使用能力。
- MCPAgentBench基于真实MCP定义,构建包含真实任务和模拟工具的数据集,并引入动态沙盒环境。
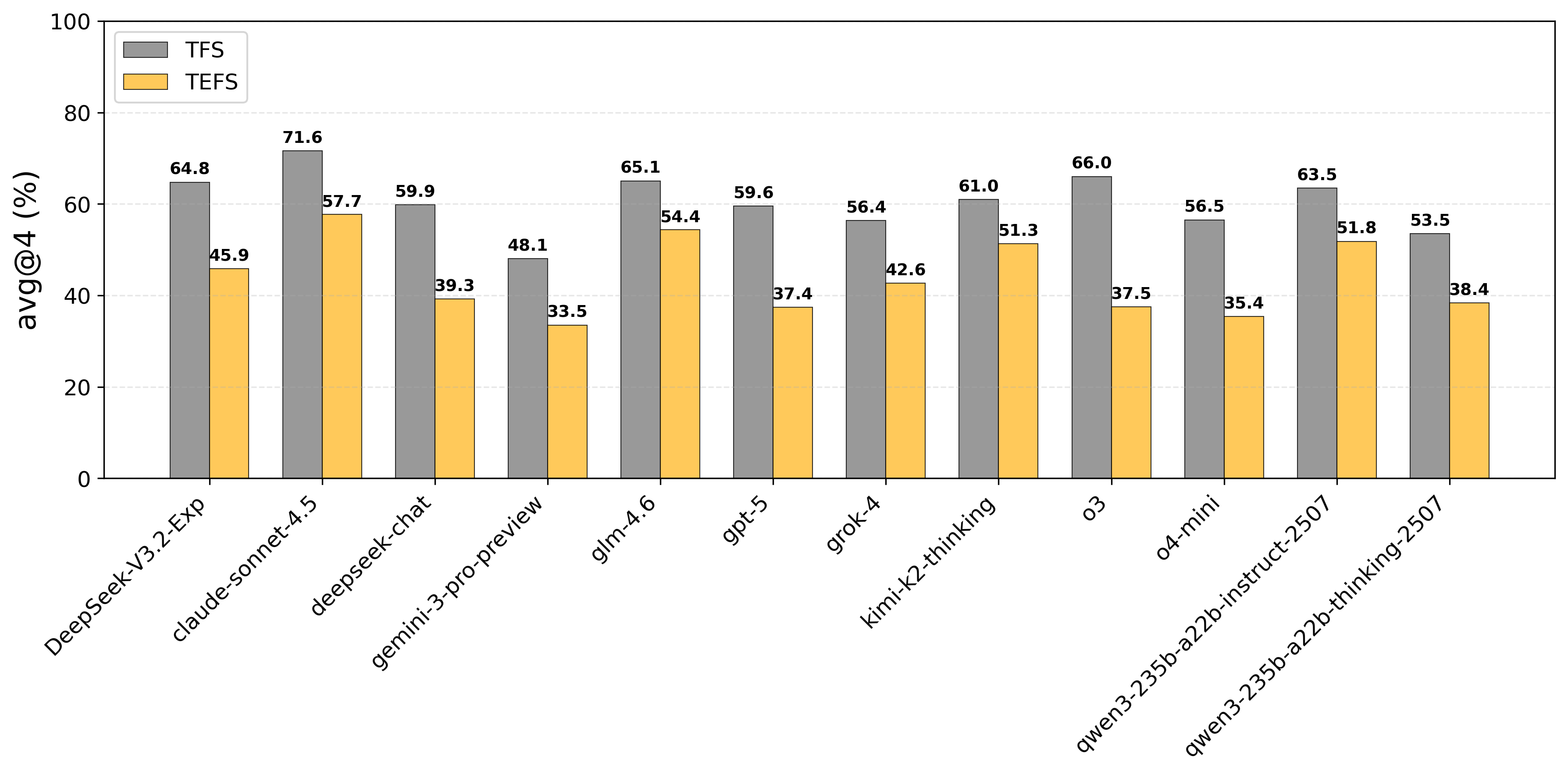
- 实验表明,不同LLM在处理复杂多步骤工具调用时性能差异显著,为Agent工具使用能力评估提供参考。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被用作自主Agent,并且通过模型上下文协议(MCP)利用外部工具被认为是未来的趋势。现有的MCP评估集存在依赖外部MCP服务和缺乏难度意识等问题。为了解决这些限制,我们提出了MCPAgentBench,这是一个基于真实MCP定义的基准,旨在评估Agent的工具使用能力。我们构建了一个包含真实任务和模拟MCP工具的数据集。评估采用动态沙盒环境,为Agent提供包含干扰项的候选工具列表,从而测试它们的工具选择和辨别能力。此外,我们引入了全面的指标来衡量任务完成率和执行效率。对各种最新的主流大型语言模型进行的实验表明,在处理复杂的、多步骤的工具调用时,性能存在显著差异。所有代码均已在Github上开源。
🔬 方法详解
问题定义:论文旨在解决现有LLM Agent在真实场景下使用MCP工具时,缺乏有效评估基准的问题。现有评估方法依赖外部MCP服务,通用性受限,且缺乏对任务难度的区分,无法全面评估Agent的工具选择、辨别和执行能力。
核心思路:论文的核心思路是构建一个基于真实MCP定义的benchmark,包含真实任务和模拟MCP工具,并设计一个动态沙盒环境,模拟真实世界中Agent需要面对的复杂情况,例如存在干扰工具。通过综合评估任务完成率和执行效率,更全面地衡量Agent的工具使用能力。
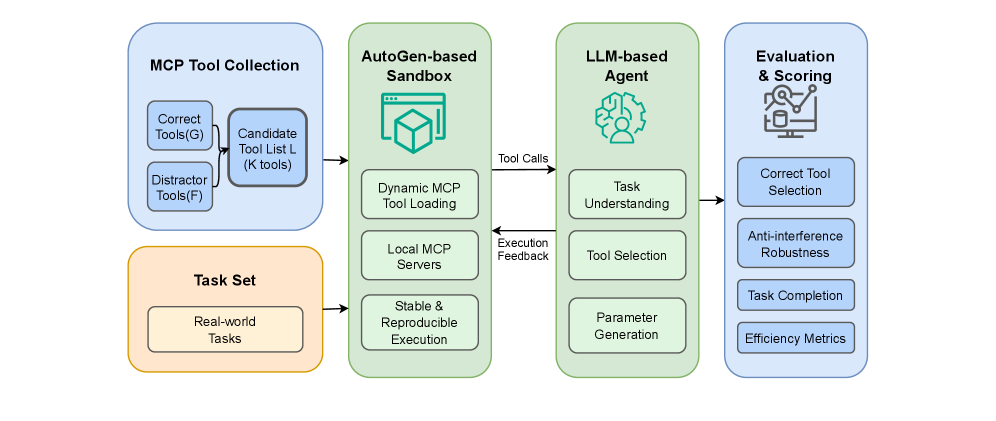
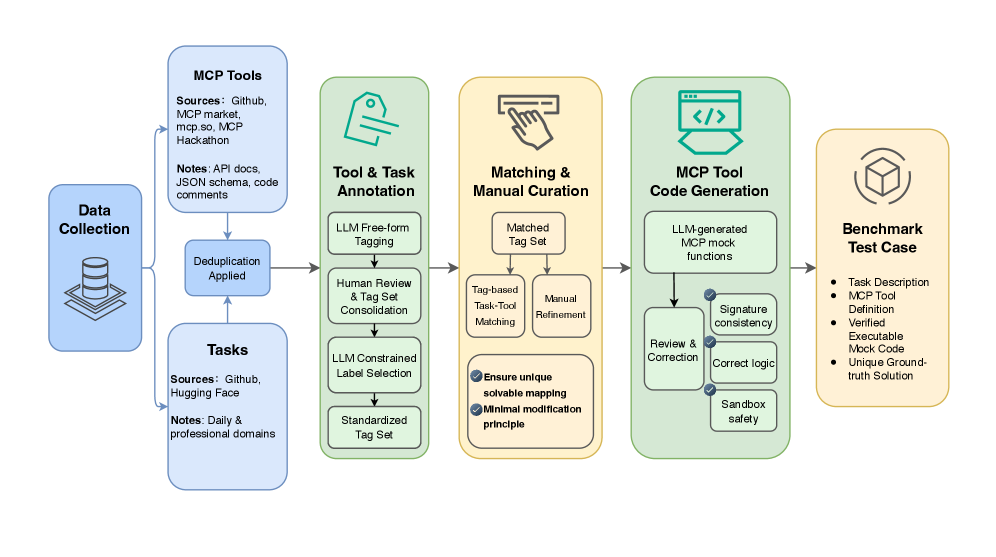
技术框架:MCPAgentBench包含以下几个主要组成部分:1) 真实任务数据集:收集真实世界中的任务需求,并将其转化为Agent可以理解的任务描述。2) 模拟MCP工具:根据真实MCP定义,模拟各种工具的功能和接口,并提供包含干扰项的候选工具列表。3) 动态沙盒环境:模拟真实世界的环境,Agent需要在该环境中选择合适的工具,并按照正确的顺序执行,以完成任务。4) 评估指标:包括任务完成率和执行效率,用于衡量Agent的工具使用能力。
关键创新:该论文的关键创新在于:1) 提出了一个基于真实MCP定义的benchmark,更贴近真实应用场景。2) 设计了一个动态沙盒环境,可以模拟真实世界中的复杂情况,例如存在干扰工具。3) 引入了全面的评估指标,可以更全面地衡量Agent的工具使用能力。与现有方法相比,MCPAgentBench更具通用性和可扩展性,可以更好地评估Agent在真实场景下的工具使用能力。
关键设计:论文中关键的设计包括:1) MCP工具的模拟,需要保证工具的功能和接口与真实工具尽可能一致。2) 动态沙盒环境的设计,需要考虑各种可能出现的干扰因素,例如存在功能相似的工具。3) 评估指标的设计,需要综合考虑任务完成率和执行效率,以全面衡量Agent的工具使用能力。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
论文通过在多个主流LLM上进行实验,验证了MCPAgentBench的有效性。实验结果表明,不同LLM在处理复杂、多步骤的工具调用时,性能存在显著差异。例如,某些LLM在任务完成率方面表现较好,而另一些LLM在执行效率方面更具优势。这些实验结果为Agent的设计和优化提供了重要的参考。
🎯 应用场景
MCPAgentBench可用于评估和提升LLM Agent在各种实际应用场景中的工具使用能力,例如智能助手、自动化流程、机器人控制等。通过该基准,可以更好地了解不同LLM在工具使用方面的优劣势,并为Agent的设计和优化提供指导,从而推动LLM Agent在实际应用中的落地。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly serving as autonomous agents, and their utilization of external tools via the Model Context Protocol (MCP) is considered a future trend. Current MCP evaluation sets suffer from issues such as reliance on external MCP services and a lack of difficulty awareness. To address these limitations, we propose MCPAgentBench, a benchmark based on real-world MCP definitions designed to evaluate the tool-use capabilities of agents. We construct a dataset containing authentic tasks and simulated MCP tools. The evaluation employs a dynamic sandbox environment that presents agents with candidate tool lists containing distractors, thereby testing their tool selection and discrimination abilities. Furthermore, we introduce comprehensive metrics to measure both task completion rates and execution efficiency. Experiments conducted on various latest mainstream Large Language Models reveal significant performance differences in handling complex, multi-step tool invocations. All code is open-source at Github.