ProSoftArena: Benchmarking Hierarchical Capabilities of Multimodal Agents in Professional Software Environments
作者: Jiaxin Ai, Yukang Feng, Fanrui Zhang, Jianwen Sun, Zizhen Li, Chuanhao Li, Yifan Chang, Wenxiao Wu, Ruoxi Wang, Mingliang Zhai, Kaipeng Zhang
分类: cs.SE, cs.AI
发布日期: 2025-12-30
💡 一句话要点
ProSoftArena:构建专业软件环境多模态Agent能力分级评估基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态Agent 专业软件 能力评估 基准测试 人机协作
📋 核心要点
- 现有Agent基准缺乏对专业软件环境的覆盖,无法真实反映科研和工业场景的需求。
- ProSoftArena构建了专业软件Agent能力层级,并提供包含多种专业软件的评估基准。
- 实验表明现有Agent在复杂专业软件任务中表现不佳,为未来研究指明方向。
📝 摘要(中文)
多模态Agent在通用计算机使用任务上取得了快速进展,但现有基准主要局限于浏览器和基本桌面应用程序,无法满足实际科研和工业实践中专业软件工作流程的需求。为了弥补这一差距,我们推出了ProSoftArena,这是一个专门用于评估专业软件环境中多模态Agent的基准和平台。我们建立了首个针对Agent使用专业软件的能力层级结构,并构建了一个包含436个实际工作和研究任务的基准,涵盖6个学科和13个核心专业应用程序。为了确保可靠和可重复的评估,我们构建了一个可执行的真实计算机环境,并采用基于执行的评估框架,独特地结合了人机协作评估模式。大量实验表明,即使是性能最佳的Agent在L2任务上的成功率也仅为24.4%,并且完全无法完成L3多软件工作流程。深入分析进一步为解决当前Agent的局限性和更有效的设计原则提供了宝贵的见解,为构建在专业软件环境中更强大的Agent铺平了道路。
🔬 方法详解
问题定义:现有Agent基准主要集中在浏览器和桌面应用,缺乏对专业软件环境的评估,无法衡量Agent在科研和工业场景下的实际能力。现有方法难以评估Agent在复杂工作流中的表现,缺乏可靠的评估框架。
核心思路:ProSoftArena的核心思路是构建一个专门针对专业软件环境的Agent评估基准和平台,通过定义能力层级、构建真实环境和采用人机协作评估,全面评估Agent在专业软件中的能力。
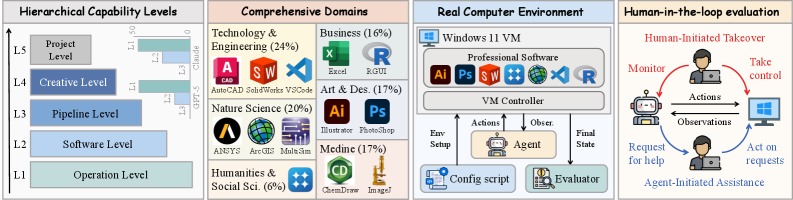
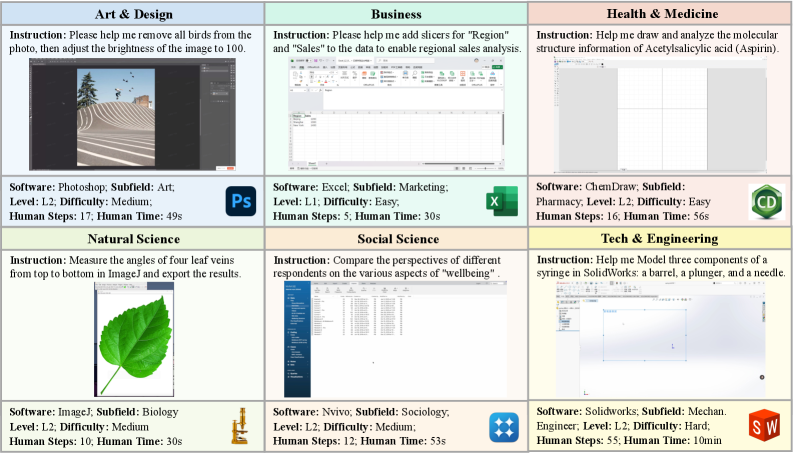
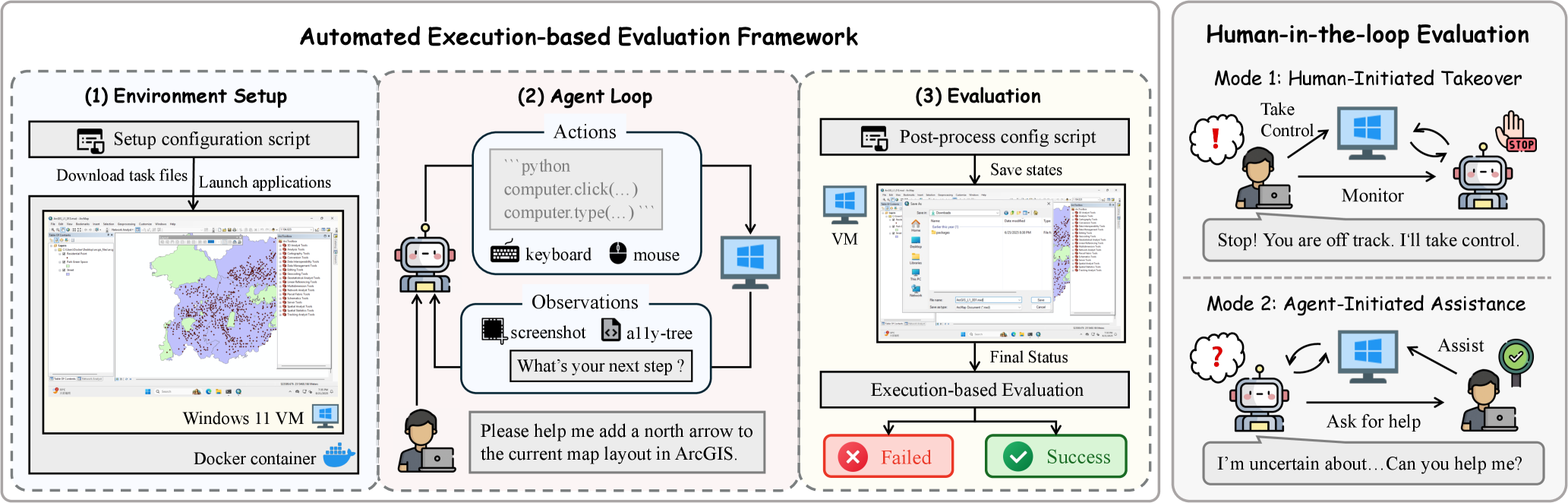
技术框架:ProSoftArena包含以下主要模块:1) 能力层级定义:定义了Agent在专业软件环境中所需的能力层级(L1-L3)。2) 任务构建:构建了包含436个任务的基准,涵盖6个学科和13个专业软件。3) 真实环境:构建了一个可执行的真实计算机环境,模拟实际软件使用场景。4) 评估框架:采用基于执行的评估框架,并结合人机协作评估,确保评估的可靠性和准确性。
关键创新:ProSoftArena的关键创新在于:1) 首次针对专业软件环境定义了Agent能力层级。2) 构建了包含多种专业软件的评估基准,更贴近实际应用场景。3) 采用了人机协作评估模式,提高了评估的准确性和可靠性。
关键设计:ProSoftArena的关键设计包括:1) 任务难度分级:根据任务的复杂程度,将其分为L1、L2和L3三个层级。2) 评估指标:采用成功率作为主要评估指标,并结合人工评估,全面评估Agent的性能。3) 环境配置:真实计算机环境配置与实际工作环境相似,保证评估的真实性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使是性能最佳的Agent在L2任务上的成功率也仅为24.4%,并且完全无法完成L3多软件工作流程。这表明现有Agent在专业软件环境中的能力仍然有限,需要进一步研究和改进。ProSoftArena为未来的Agent研究提供了重要的基准和评估工具。
🎯 应用场景
ProSoftArena的研究成果可应用于开发更智能的专业软件Agent,辅助科研人员和工程师完成复杂任务,提高工作效率。例如,可以应用于自动化数据分析、CAD设计、科学计算等领域,未来有望实现专业软件的智能化操作和自动化工作流程。
📄 摘要(原文)
Multimodal agents are making rapid progress on general computer-use tasks, yet existing benchmarks remain largely confined to browsers and basic desktop applications, falling short in professional software workflows that dominate real-world scientific and industrial practice. To close this gap, we introduce ProSoftArena, a benchmark and platform specifically for evaluating multimodal agents in professional software environments. We establish the first capability hierarchy tailored to agent use of professional software and construct a benchmark of 436 realistic work and research tasks spanning 6 disciplines and 13 core professional applications. To ensure reliable and reproducible assessment, we build an executable real-computer environment with an execution-based evaluation framework and uniquely incorporate a human-in-the-loop evaluation paradigm. Extensive experiments show that even the best-performing agent attains only a 24.4\% success rate on L2 tasks and completely fails on L3 multi-software workflow. In-depth analysis further provides valuable insights for addressing current agent limitations and more effective design principles, paving the way to build more capable agents in professional software settings. This project is available at: https://prosoftarena.github.io.