Evaluating the Reasoning Abilities of LLMs on Underrepresented Mathematics Competition Problems
作者: Samuel Golladay, Majid Bani-Yaghoub
分类: cs.AI
发布日期: 2025-12-30
备注: 7 pages, submitted to ACM Transactions on Intelligent Systems and Technology
💡 一句话要点
利用欠代表性数学竞赛题评估大语言模型的推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数学推理 竞赛题 模型评估 错误分析
📋 核心要点
- 现有研究主要依赖相同数据集评估LLM的数学推理能力,泛化性受限,无法充分反映数学任务的多样性挑战。
- 本研究采用欠代表性的数学竞赛题,考察LLM在微积分、解析几何和离散数学等领域的推理能力。
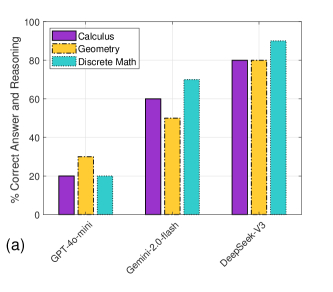
- 实验结果表明,DeepSeek-V3整体表现最佳,但所有模型在几何问题上均表现较弱,并呈现出不同的错误模式。
📝 摘要(中文)
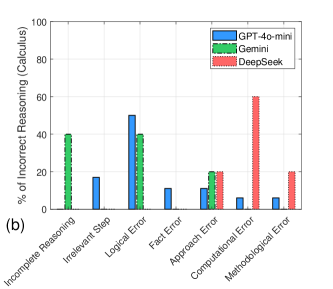
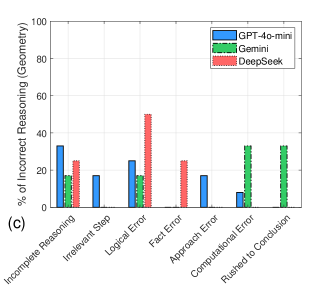
本研究旨在分析大语言模型(LLM)在欠代表性数学竞赛问题上的表现,以深入了解其数学推理能力的局限性。现有研究大多使用相同的数据集进行基准测试,这限制了研究结果的泛化性,并且可能无法充分捕捉数学任务中存在的各种挑战。本研究使用密苏里州大学生数学竞赛题(涵盖微积分、解析几何和离散数学领域)对GPT-4o-mini、Gemini-2.0-Flash和DeepSeek-V3三个领先的LLM进行了测试。通过将LLM的回答与已知正确答案进行比较,评估了它们在每个问题领域的准确性。此外,还分析了LLM的推理过程,以探索不同问题类型和模型之间的错误模式。结果表明,DeepSeek-V3在微积分、解析几何和离散数学的所有三个类别中都表现最佳,无论是在推理还是在正确答案方面。所有三个LLM在几何方面的表现都明显较弱。DeepSeek-V3的大部分错误归因于计算和逻辑错误,而GPT-4o-mini经常出现逻辑和方法相关的错误。另一方面,Gemini倾向于在不完整的推理和仓促的结论中挣扎。总之,在欠代表性数学竞赛数据集上评估LLM可以更深入地了解它们独特的错误模式,并突出结构化推理方面持续存在的挑战,尤其是在几何领域。
🔬 方法详解
问题定义:现有的大语言模型评估benchmark主要集中在常见数据集上,无法充分测试模型在更具挑战性和多样性的数学问题上的推理能力。尤其是在数学竞赛问题中,模型需要更强的逻辑推理、计算能力和问题解决策略。因此,本研究旨在评估LLM在欠代表性的数学竞赛问题上的表现,从而更全面地了解其数学推理能力的局限性。
核心思路:本研究的核心思路是利用欠代表性的数学竞赛题作为测试集,这些题目涵盖了不同的数学领域,并且具有一定的难度和挑战性,能够更好地考察LLM的推理能力。通过分析LLM在这些问题上的表现,可以发现其在不同问题类型上的优势和不足,以及其推理过程中的错误模式。
技术框架:本研究的技术框架主要包括以下几个步骤:1) 选择合适的数学竞赛题数据集(密苏里州大学生数学竞赛题);2) 选择待评估的LLM(GPT-4o-mini、Gemini-2.0-Flash和DeepSeek-V3);3) 使用适当的prompting策略,将数学问题输入到LLM中;4) 分析LLM的输出结果,包括答案的正确性以及推理过程的合理性;5) 比较不同LLM在不同问题类型上的表现,并总结其错误模式。
关键创新:本研究的关键创新在于使用了欠代表性的数学竞赛题作为评估LLM数学推理能力的测试集。与常用的benchmark数据集相比,这些题目更具挑战性和多样性,能够更好地考察LLM的推理能力。此外,本研究还对LLM的推理过程进行了分析,从而更深入地了解其错误模式。
关键设计:本研究的关键设计包括:1) 选择了涵盖微积分、解析几何和离散数学等不同领域的数学竞赛题;2) 选择了具有代表性的LLM进行评估;3) 使用了简单的prompting策略,避免引入额外的偏差;4) 对LLM的输出结果进行了详细的分析,包括答案的正确性和推理过程的合理性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DeepSeek-V3在微积分、解析几何和离散数学三个类别中表现最佳,但所有模型在几何问题上均表现出明显不足。错误分析揭示了不同模型独特的错误模式:DeepSeek-V3主要为计算和逻辑错误,GPT-4o-mini倾向于逻辑和方法错误,而Gemini则常因推理不完整和仓促结论而犯错。
🎯 应用场景
该研究成果可应用于改进大语言模型的数学推理能力,例如通过针对性的训练数据增强和推理策略优化。此外,该研究方法也可推广到其他领域的推理能力评估,例如逻辑推理、常识推理等。未来,更强大的数学推理能力将有助于LLM在科学研究、工程设计等领域发挥更大的作用。
📄 摘要(原文)
Understanding the limitations of Large Language Models, or LLMs, in mathematical reasoning has been the focus of several recent studies. However, the majority of these studies use the same datasets for benchmarking, which limits the generalizability of their findings and may not fully capture the diverse challenges present in mathematical tasks. The purpose of the present study is to analyze the performance of LLMs on underrepresented mathematics competition problems. We prompted three leading LLMs, namely GPT-4o-mini, Gemini-2.0-Flash, and DeepSeek-V3, with the Missouri Collegiate Mathematics Competition problems in the areas of Calculus, Analytic Geometry, and Discrete Mathematics. The LLMs responses were then compared to the known correct solutions in order to determine the accuracy of the LLM for each problem domain. We also analyzed the LLMs reasoning to explore patterns in errors across problem types and models. DeepSeek-V3 has the best performance in all three categories of Calculus, Analytic Geometry, and Discrete Mathematics, both in reasoning and correct final answers. All three LLMs exhibited notably weak performance in Geometry. The majority of errors made by DeepSeek-V3 were attributed to computational and logical mistakes, whereas GPT-4o-mini frequently exhibited logical and approach-related errors. Gemini, on the other hand, tended to struggle with incomplete reasoning and drawing rushed conclusions. In conclusion, evaluating LLMs on underrepresented mathematics competition datasets can provide deeper insights into their distinct error patterns and highlight ongoing challenges in structured reasoning, particularly within the domain of Geometry.