PackKV: Reducing KV Cache Memory Footprint through LLM-Aware Lossy Compression
作者: Bo Jiang, Taolue Yang, Youyuan Liu, Xubin He, Sheng Di, Sian Jin
分类: cs.DC, cs.AI
发布日期: 2025-12-30 (更新: 2026-01-07)
🔗 代码/项目: GITHUB
💡 一句话要点
PackKV:通过LLM感知的有损压缩降低KV缓存内存占用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存压缩 长上下文推理 大型语言模型 有损压缩 LLM感知 内存优化 推理加速
📋 核心要点
- 长上下文LLM推理面临KV缓存巨大内存需求的挑战,现有方法难以兼顾压缩率和计算效率。
- PackKV提出LLM感知的有损压缩,协同设计压缩算法和系统架构,优化KV缓存管理。
- 实验表明,PackKV在保证精度前提下,显著提升内存压缩率和计算吞吐量,优于现有量化方法。
📝 摘要(中文)
基于Transformer的大型语言模型(LLM)在广泛的实际应用中展现了卓越的潜力。然而,由于键值(KV)缓存的大量内存需求,长上下文推理仍然是一个重大挑战,随着序列长度和批大小的增加,KV缓存可能会扩展到几个GB。本文提出了PackKV,这是一个为长上下文生成优化的通用且高效的KV缓存管理框架,它协同支持延迟敏感和吞吐量敏感的推理场景。PackKV引入了专门为KV缓存数据特性量身定制的新型有损压缩技术,其特点是压缩算法和系统架构的精心协同设计。我们的方法与KV缓存的动态增长特性兼容,同时保持了较高的计算效率。实验结果表明,在与最先进的量化方法相同且最小的精度下降下,PackKV实现了K缓存平均高153.2%的内存减少率,V缓存平均高179.6%的内存减少率。此外,PackKV提供了极高的执行吞吐量,有效地消除了解压缩开销并加速了矩阵-向量乘法运算。具体而言,与cuBLAS矩阵-向量乘法内核相比,PackKV在A100和RTX Pro 6000 GPU上实现了K平均75.7%和V平均171.7%的吞吐量提升,同时需要更少的GPU内存带宽。
🔬 方法详解
问题定义:现有的大型语言模型在长上下文推理时,KV缓存会占用大量内存,成为性能瓶颈。现有的压缩方法,例如量化,在压缩率和计算效率之间难以取得平衡,或者无法充分利用KV缓存数据的特性进行优化。
核心思路:PackKV的核心思路是设计一种LLM感知的有损压缩方法,该方法能够根据KV缓存数据的特性,在保证模型精度损失最小的前提下,最大程度地压缩KV缓存,同时优化系统架构,减少解压缩开销,提高计算效率。
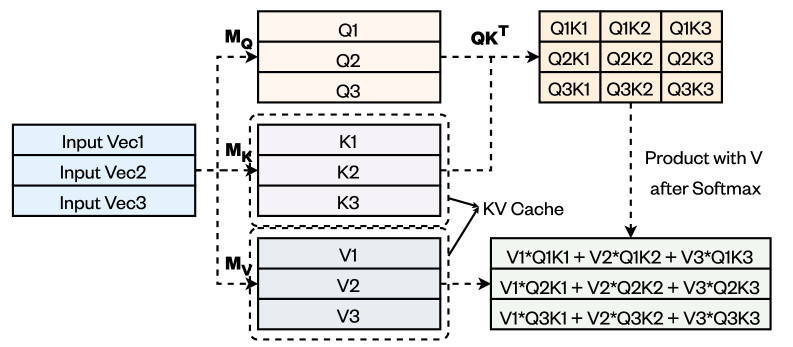
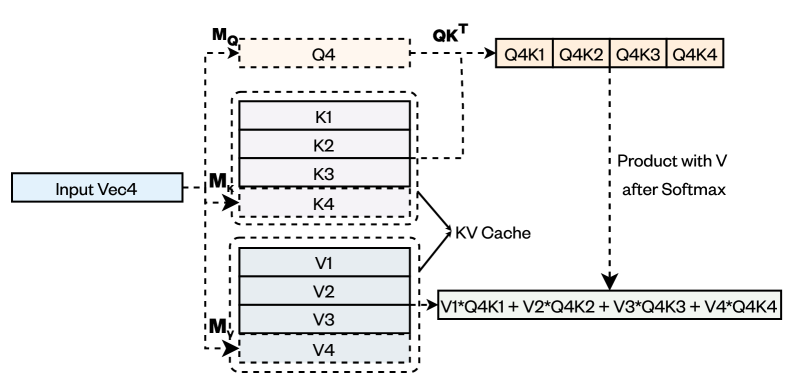
技术框架:PackKV框架包含压缩模块和计算模块。压缩模块负责对KV缓存进行有损压缩,采用专门为KV缓存数据设计的压缩算法。计算模块负责在压缩后的KV缓存上进行推理计算,通过优化矩阵-向量乘法运算,减少解压缩开销,提高计算效率。整体流程为:输入序列 -> KV缓存生成 -> KV缓存压缩 -> 压缩后的KV缓存用于推理计算 -> 输出结果。
关键创新:PackKV的关键创新在于LLM感知的有损压缩算法,该算法能够根据KV缓存数据的特性,自适应地调整压缩参数,从而在保证模型精度损失最小的前提下,最大程度地压缩KV缓存。此外,PackKV还通过优化系统架构,减少解压缩开销,提高计算效率。
关键设计:PackKV的关键设计包括:1) 针对K和V缓存分别设计不同的压缩算法,以适应它们不同的数据特性;2) 采用动态压缩策略,根据KV缓存的动态增长特性,自适应地调整压缩参数;3) 优化矩阵-向量乘法运算,减少解压缩开销,提高计算效率;4) 损失函数的设计需要考虑压缩带来的精度损失,并进行权衡。
🖼️ 关键图片

📊 实验亮点
PackKV在与最先进的量化方法进行比较时,在相同或更小的精度损失下,实现了K缓存平均高153.2%的内存减少率,V缓存平均高179.6%的内存减少率。此外,PackKV在A100和RTX Pro 6000 GPU上实现了K平均75.7%和V平均171.7%的吞吐量提升,同时需要更少的GPU内存带宽。这些结果表明,PackKV在内存压缩和计算效率方面都优于现有方法。
🎯 应用场景
PackKV可应用于各种需要长上下文推理的大型语言模型应用场景,例如机器翻译、文本摘要、对话生成等。通过降低KV缓存的内存占用,PackKV可以支持更大的批处理大小和更长的序列长度,从而提高模型的推理性能和效率。此外,PackKV还可以降低部署LLM的硬件成本,使其更易于在资源受限的设备上部署。
📄 摘要(原文)
Transformer-based large language models (LLMs) have demonstrated remarkable potential across a wide range of practical applications. However, long-context inference remains a significant challenge due to the substantial memory requirements of the key-value (KV) cache, which can scale to several gigabytes as sequence length and batch size increase. In this paper, we present \textbf{PackKV}, a generic and efficient KV cache management framework optimized for long-context generation. %, which synergistically supports both latency-critical and throughput-critical inference scenarios. PackKV introduces novel lossy compression techniques specifically tailored to the characteristics of KV cache data, featuring a careful co-design of compression algorithms and system architecture. Our approach is compatible with the dynamically growing nature of the KV cache while preserving high computational efficiency. Experimental results show that, under the same and minimum accuracy drop as state-of-the-art quantization methods, PackKV achieves, on average, \textbf{153.2}\% higher memory reduction rate for the K cache and \textbf{179.6}\% for the V cache. Furthermore, PackKV delivers extremely high execution throughput, effectively eliminating decompression overhead and accelerating the matrix-vector multiplication operation. Specifically, PackKV achieves an average throughput improvement of \textbf{75.7}\% for K and \textbf{171.7}\% for V across A100 and RTX Pro 6000 GPUs, compared to cuBLAS matrix-vector multiplication kernels, while demanding less GPU memory bandwidth. Code available on https://github.com/BoJiang03/PackKV